







在大模型风靡的 2024 年,如果说 AI 领域什么最火,「具身智能」这个方向必定位列其中。
什么是具身智能?
具身智能通过在物理世界和数字世界的学习和进化,达到理解世界、互动交互并完成任务的目标。
具身智能是由“本体”和“智能体”耦合而成且能够在复杂环境中执行任务的智能系统。一般认为,具身智能具有如下的几个核心要素:
第一是本体,作为实际的执行者,是在物理或者虚拟世界进行感知和任务执行的机构。
本体通常是具有物理实体的机器人,可以有多种形态。本体的能力边界会限制智能体的能力发挥,所以,具有广泛适应性的机器人本体是非常必要的。
随着机器人技术的进步,本体越来越呈现多样化和灵活性。比如,四足机器人可以具有良好的运动能力和通过性,复合机器人则把运动和操作机构整合,具有较好的任务能力;而人形机器人作为适应性更加广泛,通用能力更强的本体形态,得到了长足的进步,已经到了可以商业化的前夕。
本体具备环境感知能力、运动能力和操作执行能力,是连接数字世界和物理世界的载体。
具身智能的第二个要素是智能体(Embodied Agents),是具身于本体之上的智能核心,负责感知、理解、决策、控制等的核心工作。
智能体可以感知复杂环境,理解环境所包含的语义信息,能够和环境进行交互;可以理解具体任务,并且根据环境的变化和目标状态做出决策,进而控制本体完成任务。
随着深度学习的发展,现代智能体通常由深度网络模型驱动,尤其是随着大语言模型(LLM)的发展,结合视觉等多种传感器的复杂多模态模型,已经开始成为新一代智能体的趋势。
同时,智能体也分化为多种任务形态,处理不同层次和模态的任务。智能体要能够从复杂的数据中学习决策和控制的范式,并且能够持续的自我演进,进而适应更复杂的任务和环境。
智能体设计是具身智能的核心。具有通用能力的LLM和VLM等模型,赋予了通用本体强大的泛化能力,使得机器人从程序执行导向转向任务目标导向,向通用机器人迈出了坚实的步伐。
具身智能的第三个要素是数据。“数据是泛化的关键,但涉及机器人的数据稀缺且昂贵。”
为了适应复杂环境和任务的泛化性,智能体规模变的越来越大,而大规模的模型对于海量数据更为渴求。现在的LLM通常需要web-scale级别的数据来驱动基础的预训练过程,而针对具身智能的场景则更为复杂多样,这造成了多变的环境和任务,以及围绕着复杂任务链的规划决策控制数据。尤其是针对行业场景的高质量数据,将是未来具身智能成功应用落地的关键支撑。
具身智能的第四个要素是学习和进化架构。智能体通过和物理世界(虚拟的或真实的)的交互,来适应新环境、学习新知识并强化出新的解决问题方法。
采用虚拟仿真环境进行部分学习是合理的设计,比如英伟达的元宇宙开发平台Omniverse,就是构建了物理仿真的虚拟世界,来加速智能体的演进。
但真实环境的复杂度通常超过仿真环境,如何耦合仿真和真实世界,进行高效率的迁移(Sim2Real),也是架构设计的关键。
具身智能的科研和技术进展
在基于Transformer的大语言模型浪潮带领下,微软、谷歌、英伟达等大厂,以及斯坦福、卡耐基梅隆等高等学府均开展了具身智能的相关研究。
微软基于ChatGPT的强大自然语言理解和推理能力,生成控制机器人的相关代码;
英伟达VIMA基于T5模型,将文本和多模态输入交错融合,结合历史信息预测机器人的下一步行动动作;
斯坦福大学利用LLM的理解、推理和代码能力,与VLM交互并生成3D value map,来规划机械臂的运行轨迹;
谷歌具身智能路线较多,包括从PaLM衍生来的PaLM-E,从Gato迭代来的RoboCat,以及最新基于RT-1和PaLM-E升级得到的RT-2。

谷歌在具身智能的研究上更具有广泛性和延续性。与其他大厂相比,谷歌依托旗下两大AI科研机构,Google Brain和DeepMind(2023年4月两大机构合并为Google DeepMind),在具身智能上研究了更多的技术路线,且各路线之间有很好的技术延续性。
其中基于RT-1研究成果,谷歌融合了VLM(PaLM-E是其中一种)和RT-1中收集的大量机器人真实动作数据,提出了视觉语言动作(VLA)模型 RT-2,在直接预测机器人动作的同时,受益于互联网级别的训练数据,实现了更好的泛化性和涌现性。
从RT-2的实验结果看,一方面,面对训练数据中没见过的物体、背景、环境,RT-2系列模型能够仍能实现较高的成功率,远超基线对比模型,证明了模型有较强的泛化能力。
另一方面,对于符号理解、推理和人类识别三类不存在于机器人训练数据中的涌现任务,RT-2系列模型也能以较高正确率完成,表明语义知识从视觉语言数据中转移到RT-2 中,证明了模型的涌现性能。同时,思维链(CoT)推理能够让RT-2完成更复杂的任务。
任何的训练都需要数据的支撑。目前来看,机器人数据来源通常是真实数据和合成数据。
真实数据效果更好,但需要耗费大量的人力和物力,不是一般的企业或机构能够负担的。谷歌凭借自己的资金和科研实力,耗费17个月时间收集了13台机器人的13万条机器人真实数据,为RT-1和RT-2的良好性能打下根基。
谷歌的另一项研究RoboCat,在面对新的任务和场景时,会先收集100-1000个真实的人类专家示例,再合成更多数据,用于后续训练,是经济性和性能的权衡。
除了数据来源问题,还有一个就是具身智能体的预测如何映射到机器人的动作,这主要取决于预测结果的层级。
以谷歌PaLM-E和微软ChatGPT for Robotics为例,预测结果处于高级别设计层级:PaLM-E实现了对具身任务的决策方案预测,但不涉及机器人动作的实际控制,需要依赖低级别的现成策略或规划器来将决策方案“翻译”为机器人动作。
微软默认提供控制机器人的低层级 API,ChatGPT 输出是更高层级的代码,只需调用到机器人低层级的库或API,从而实现对机器人动作的映射和控制。
还有一种情况就是预测结果已经到了低级别动作层级。例如,RT-2输出的一系列字符串,是可以直接对应到机器人的坐标、旋转角等信息;VoxPoser规划的结果直接就是机器人运行轨迹;VIMA也可以借助现有方法将预测的动作token映射到离散的机器人手臂姿势,即不需要再经过复杂的翻译将高层级设计映射到低层级动作。
智元机器人
视线放到国内,「智元机器人」这家具身智能公司备受瞩目。自 2023 年 2 月成立以来,「智元机器人」已马不停蹄地完成了 6 轮融资,迅速成为机器人创业圈的「顶流项目」。
创业半年,稚晖君和团队就拿出了首款产品「远征 A1」。一出道,「远征 A1」的行走能力和人机互动就是业界领先水平。不过,在「远征 A1」初次亮相之后,我们似乎再也没听说过它的下一步消息,甚至没有放出任何整活视频。
但今天的发布会之后,我们知道了,智元机器人在「闷声干大事」。



在这场发布会中,稚晖君一口气推出了三款远征系列机器人产品:交互服务机器人「远征 A2」、柔性智造机器人「远征 A2-W」、重载特种机器人「远征 A2-Max」。最后的 One more thing 环节,智元 X-Lab 孵化的模块化机器人系列产品「灵犀 X1」和「灵犀 X1-W」也作为「彩蛋」正式亮相。
相比上一代,五款机器人采用了家族化设计语言,对机器人的外形进行了系列化的规整,结合轮式与足式两种形态,覆盖交互服务、柔性智造、特种作业、科研教育和数据采集等应用场景。
关于量产进度,智元机器人也透露了最新消息:2024 年预估发货量将达到 300 台左右,其中双足 200 台左右,轮式 100 台左右。
智元机器人的实践
8月18日,智元机器人在具身智能远征A1的发布会提出了一种具身智脑的概念:
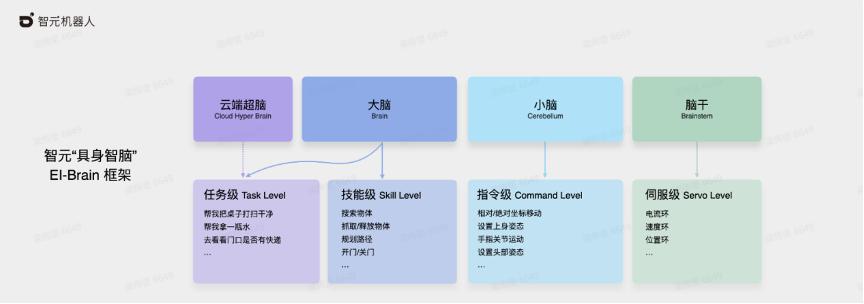
具身智脑EI-Brain(Embodied Intelligence Brain)把机器人的具身智能思维系统分为云端的超脑、端侧的大脑、小脑,以及脑干这样四层,分别对应于机器人任务级、技能级、指令级以及伺服级的能力。
⼤脑⽤于完成前⾯提到的语义级多段推理任务,结合上下文进行任务理解,⽽且如果模型的通识能⼒不满⾜任务需求,还可以借⽤更强的云端超脑的互联⽹能⼒。
小脑则负责结合各种传感器的信息进行运动指令⽣成,就跟⼈类⼀样,⼤家⾛路的时候并不会想着怎么精确地控制每块肌⾁收缩,而是由⼤脑发出⼀个宏观指令后,由⼩脑完成身体的平衡和各种运动学动⼒学的控制,运控算法都跑在这⼀层。
最后在硬件底层,由脑⼲来进⾏精确的伺服闭环控制每个电机⾼效精准地执⾏。
在硬件层面,智元自研了关节电机PowerFlow、灵巧手SkillHand、反曲膝设计等关键零部件,以此提升具身智能机器人的能力、同时降低成本。
在软件层面,智元自研了AgiROS,是一套机器人运行时中间件系统,在AI感知决策与视觉控制等大模型算法方面,能够实现自主任务编排、常识推理与规划执行等。
开源
而智元机器人做到了,还预备在今年第四季度开源。稚晖君表示,会开源灵犀 X1 的本体设计图纸、软件框架、中间件源码、基础运控算法。

















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









