







-
论文题目:UrBench: A Comprehensive Benchmark for Evaluating Large Multimodal Models in Multi-View Urban Scenarios
-
发表时间:2024.12.23
摘要
近年来,针对大型多模态模型(LMMs)的能力研究已覆盖多个领域,但专门针对城市环境的系统性评估体系仍较为匮乏。大多数现有的基准测试仅关注于单一视角下的区域级城市任务,无法全面评估 LMMs 在复杂城市环境中的表现。为此,本文提出了一个专为评估LMMs 在多视角城市场景中表现而设计的综合基准测试UrBench。
本文三点贡献如下:
-
一个多视角基准测试,旨在评估LMMs在城市环境中的表现。该基准包含14种城市任务,涵盖多个维度,既包括评估LMMs在城市规划能力的区域级任务,也涉及考察其应对日常问题的角色级任务。
-
采用跨视角检测匹配算法生成对象级标注,并结合基于LMM、规则和人工的方法生成问题,构建了大规模、高质量的问题集。
-
在24个(GPT-4o、DeepSeek-VL2、Gemini和InternVL2等)主流LMMs上的评估显示,当前模型在大多数任务中仍落后于人类专家,且在不同城市视角下表现不一致,揭示了现有LMMs在城市环境中的局限性。
背景
-
大型多模态模型(LMMs)的发展:近年来,LMMs在多个领域的表现引起了广泛的关注。其核心目标是构建以人为本的AI模型,以服务于日常生活。
-
LMMs在城市环境中的关键作用:随着全球城市化进程的加速,超过57%的人口居住在城市地区,城市任务的需求日益复杂,因此开发能够理解和处理复杂城市任务的人工智能模型变得尤为重要。
-
城市环境的多视角特性:城市环境通常从多个视角(如卫星图像的垂直视角和街景图像的水平视角)进行捕捉。要全面服务于城市人口,AI模型需要能够从多视角理解城市环境。
方法
Benchmark Analyse
与现有基准测试相比,UrBench具有以下特点:
-
多层次问题设计:UrBench不仅包含区域级任务,还引入了角色级问题,覆盖从城市规划到日常决策的多样化场景,而现有基准大多仅聚焦于区域级任务。
-
多视角数据整合:UrBench融合了街景、卫星及其跨视角配对数据(图3(b)),突破了传统基准测试单一视角的局限,为模型提供了更全面的城市场景理解能力。
-
多样化任务类型:UrBench设计了14种任务类型,涵盖地理定位、场景推理、场景理解和对象理解四大任务维度(图3(a)),远超现有基准测试中常见的计数、物体识别等单一任务类型,为模型评估提供了更丰富的场景支持。
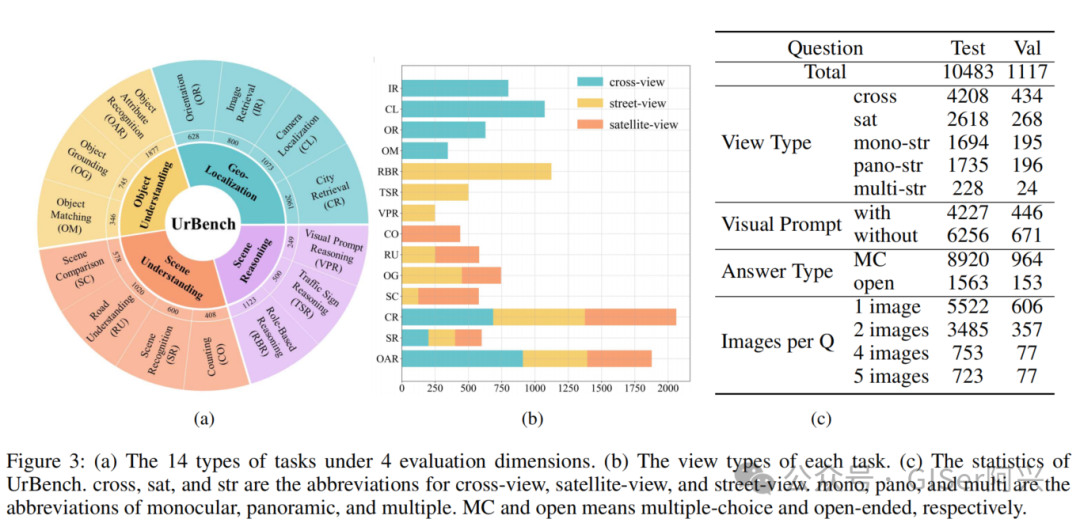
BenchMark Tasks
-
地理定位(Geo-Localization):评估LMMs根据图像预测地理坐标和方向的能力,包括图像检索(IR)、城市检索(CR)、方向预测(OR)和相机定位(CL)任务。
-
场景推理(Scene Reasoning):设计了视觉提示推理(VPR)、交通标志推理(TSR)和基于角色的推理任务,评估LMMs在多视角城市场景下的推理能力。
-
场景理解(Scene Understanding):通过场景识别(SR)、场景比较(SC)和道路理解(RU)等任务,评估LMMs对城市区域级场景的理解能力,例如识别建筑类型和道路类型。
-
对象理解(Object Understanding):包含目标定位(OG)、目标匹配(OM)和目标属性识别(OAR)任务,评估LMMs在城市环境中对目标的细粒度理解和跨视角匹配能力。
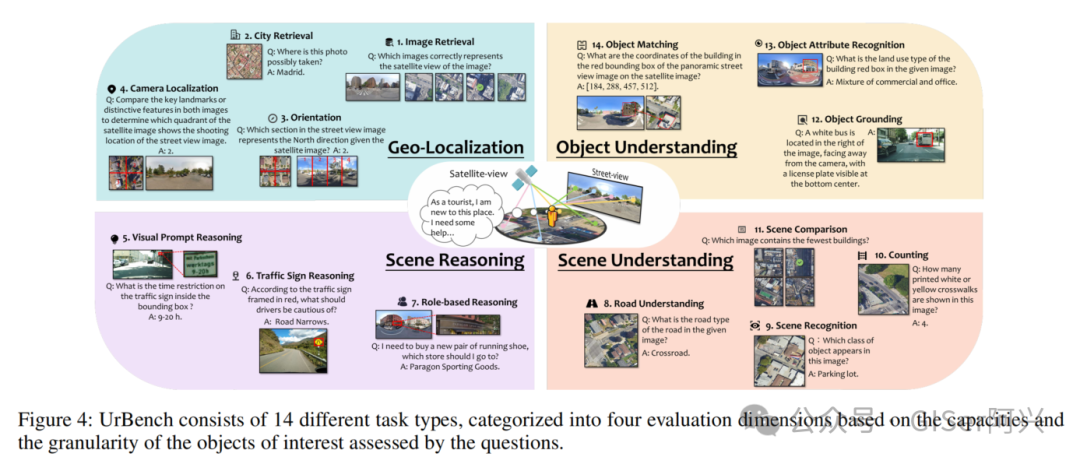
Benchmark Curation
-
数据收集:UrBench数据来自内部采集和开源数据集。内部数据包括2604张街景图像和4239张卫星图像,其中1965对图像根据地理坐标匹配,并包含OpenStreetMap注释。所有图像采集于2022-2023年,以避免时间差异。此外,还从Cityscapes、Mapillary、VIGOR和IM2GPS等开源数据集补充图像。
-
数据预处理:对图像数据进行处理,生成注释。开发跨视角检测匹配方法,利用Grounding DINO提取街景图像边界框,并通过光线追踪映射到卫星图像,筛选IoU大于0.5的匹配对,经人工检查确保质量。整合多数据集注释,构建全面注释数据库。
-
问题生成:设计三种问题生成方法:(1)基于LMM:使用四种模型生成问答对,人工审核确保质量;(2)基于规则:根据注释自动转换生成问答对;(3)基于人工:针对无法从注释生成答案的任务,人工标注问答对。
-
质量控制:通过人工检查减少偏差:移除时间不一致的图像,验证跨视角匹配的正确性,对LMM生成数据进行多人审核,确保数据质量。
实验
除了直接对比主流的LMMs在UrBench上表现,本研究还招募了一批具有遥感专业背景的志愿者,以“人类专家”的身份独立完成UrBench中的任务,并对其答题结果进行统计分析,以此作为对比LMMs表现的基准
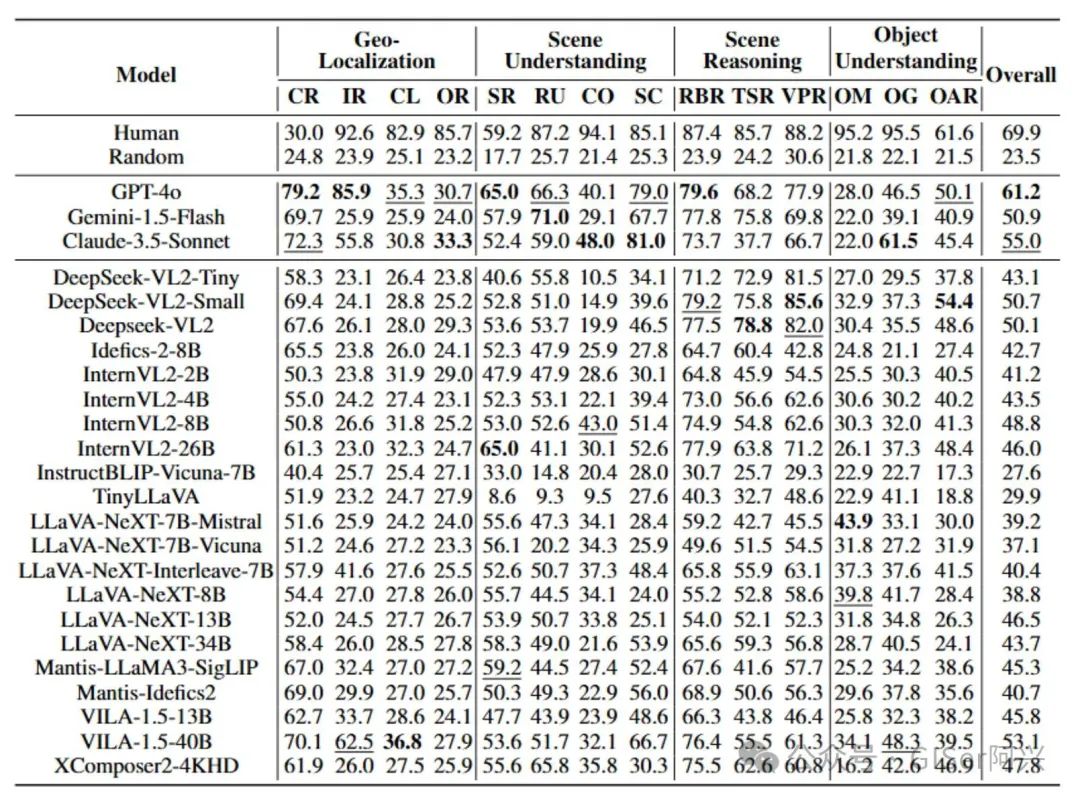
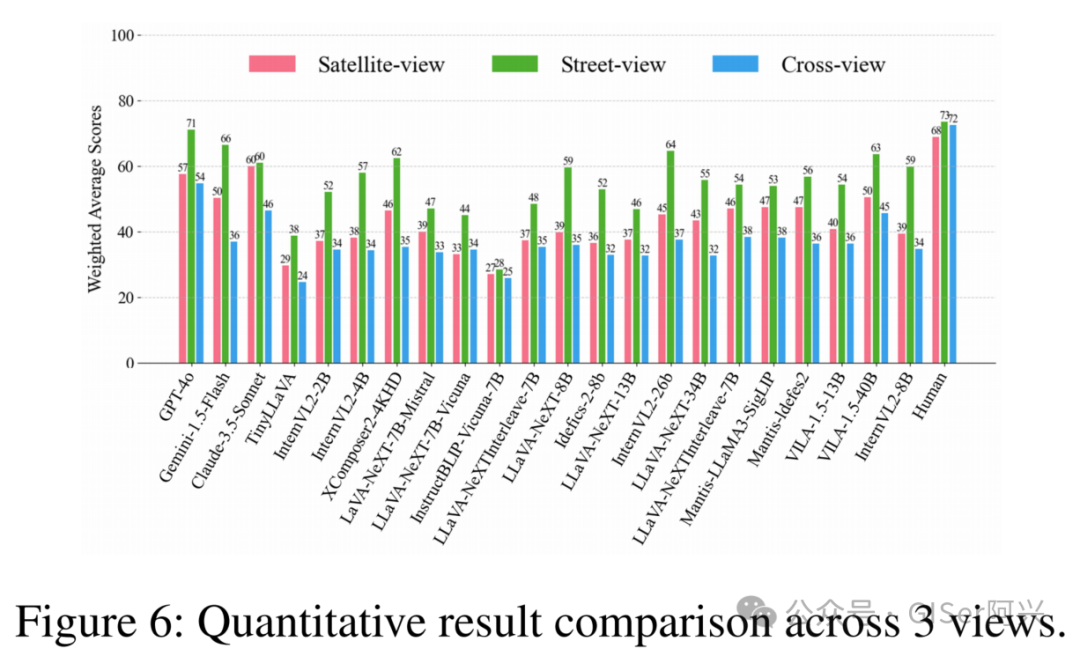
实验结果表明:LMMs在场景推理任务中表现尤为突出,展现了较强的逻辑推理和上下文理解能力。然而,与人类专家测评基准相比,LMMs整体表现仍存在一定差距。值得注意的是,在城市检索(CR)和场景识别(SR)任务中,LMMs的表现优于人类专家,凸显了其在特定任务上的独特优势。
结论
本工作提出了一个全新面向复杂城市环境的LMMs基准测试UrBench,旨在通过多样化的任务类型和视角类型评估LMMs在城市环境中的表现。
-
提出了一个新颖的跨视角数据收集流程,能够在实例级别上对跨视角图像进行配对。最终收集了11600个问题,包含四个维度下的14个子任务。
-
评估了24个LMMs在这些问题上的表现,并揭示了它们在城市环境中存在的局限性。
-
对不同视角类型和任务类型下的LMMs性能进行了广泛的分析,结果表明,当前的LMMs在城市环境中仍然显著落后于人类专家。
-
本文还指出,当前的LMMs在理解多视角图像关系方面存在困难,且在不同视角下的表现不一致,这揭示了在LMMs训练过程中不同视角之间存在的不平衡和偏差问题。
希望本文工作能够为未来提升LMMs在城市场景中的能力提供指导。

















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









