







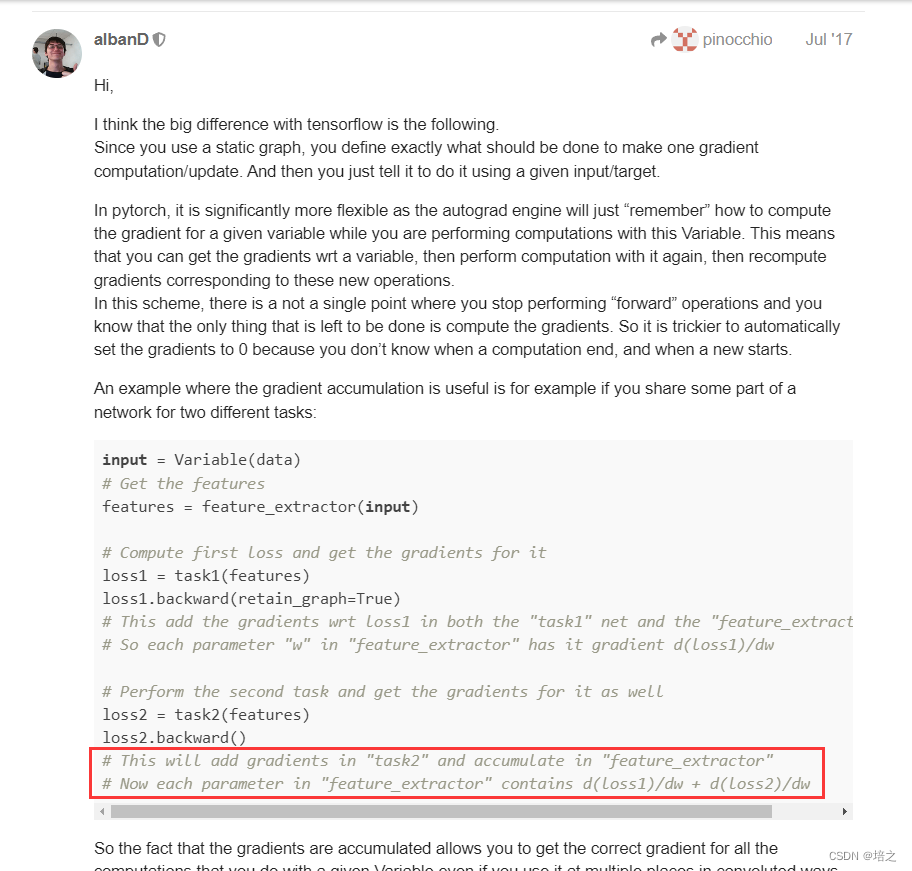
pytorch backwad 函数计算梯度是 累计式的
关于 pytorch 的 backward()函数反向传播计算梯度是 累计式的,见下图(主要是图中用黑框框出来的部分内容)。
因为这样,所以才需要 optimizer.zero_grad()。
利用 gradient accumulation 的框架
一般的优化框架是:
# loop through batches
for (inputs, labels) in data_loader:
# extract inputs and labels
inputs = inputs.to(device)
labels = labels.to(device)
# passes and weights update
with torch.set_grad_enabled(True):
# forward pass
preds = model(inputs)
loss = criterion(preds, labels)
# backward pass
loss.backward()
# weights update
optimizer.step()
optimizer.zero_grad()
利用 gradient accumulation 的框架是这样的。
为什么需要 gradient accumulation 呢?
因为可能会出现 训练集 batch size 比较大,电脑 显存吃不下的情况,这样就需要将一个 batch 分为几个小 batch训练,但是同时又都利用它们的gradient 信息。
# batch accumulation parameter
accum_iter = 4
# loop through enumaretad batches
for batch_idx, (inputs, labels) in enumerate(data_loader):
# extract inputs and labels
inputs = inputs.to(device)
labels = labels.to(device)
# passes and weights update
with torch.set_grad_enabled(True):
# forward pass
preds = model(inputs)
loss = criterion(preds, labels)
# normalize loss to account for batch accumulation
loss = loss / accum_iter
# backward pass
loss.backward()
# weights update
if ((batch_idx + 1) % accum_iter == 0) or (batch_idx + 1 == len(data_loader)):
optimizer.step()
optimizer.zero_grad()
















 1918
1918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











