







在PCA中,数据从原来的坐标系转换到新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们可以忽略余下的坐标轴,即对数据进行降维处理。
PCA降维的两个准则:
最近重构性:样本集中所有点,重构后的点距离原来的点的误差之和最小。
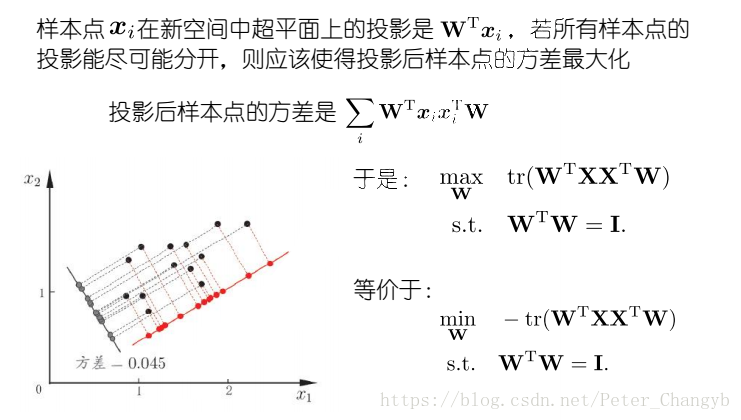
最大可分性:样本在低维空间的投影尽可能分开。
- 优化目标:

- 最大可分析(正交化)

/**
* Created by Administrator on 2017/7/28 0028.
*/
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.linalg.distributed.RowMatrix
import org.apache.spark.{SparkConf, SparkContext}
object PCA {
def main(args: Array[String]) {
val conf = new SparkConf() //创建环境变量
.setMaster("local") //设置本地化处理
.setAppName("PCA ") //设定名称
val sc = new SparkContext(conf) //创建环境变量实例
val data = sc.textFile("c://a.txt") //创建RDD文件路径
.map(_.split(' ') //按“ ”分割
.map(_.toDouble)) //转成Double类型
.map(line => Vectors.dense(line)) //转成Vector格式
val rm = new RowMatrix(data) //读入行矩阵
val pc = rm.computePrincipalComponents(3) //提取主成分,设置主成分个数
val mx = rm.multiply(pc) //创建主成分矩阵
mx.rows.foreach(println) //打印结果
}
}

















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









