






目录
Manus对现实社会的重要改造在于,能将大模型(如DeepSeek)的逻辑与思维能力转化为实际行动,并应用于实际产品,这是Manus或智能体的核心概念。
智能体的核心概念
那么,智能体与传统人工智能有何区别?传统人工智能主要解决输入与输出的映射关系,例如输入图片判断是狗还是猫,通过输入感知内容,识别歌曲、图片,分析棋局局势,进行对话生成下一句内容等。而智能体有几个关键要素:它不仅进行感知,还像人脑一样进行推理和思维,进行规划,并采取行动,将事情落到实处,这便是简单智能体的概念。伯克利知名教授Russel认为,智能体是能够感知环境并做出响应以实现某些目标的任何实体。
智能体如今取得巨大成功,得益于大模型的迅猛发展。大模型与智能体能够有效结合,是因为智能体围绕其框架有三个关键模块:
一是具备记忆能力,以往人工智能在多轮对话中可能遗忘自身角色,而如今像调用DeepSeek时会为其设定角色,要求大模型也具备记忆功能。
二是具备思考能力,能分析语言语境并反思。
三是能结合外部调用工具,如DeepSeek有联网搜索功能。
ChatGPT的成功主要依赖于三项关键技术:指令微调、情景学习和思维链。
情景学习是指根据上下文信息来优化回答。例如,在DeepSeek中,为了让其给出更优质的答案,我们除了为其设定角色外,还会提供示例,如要求其呈现一份周报。此时,智能体便会利用情景学习,参考类似的上下文信息。
DeepSeek之所以能在全球引发轰动,是因为以往ChatGPT或OpenAI公司所呈现的思维链过程是隐含且闭源的,而DeepSeek首次将整个思维链(Chain of Thought,COT)过程公开,即输入问题后,DeepSeek会展示一段一段的思考过程。大家能感受到,其思考方式与人类相近,会将大问题拆解为不同步骤去解决,这正是思维链过程,也是大模型成功的关键秘诀。
在大模型与智能体结合的过程中,企业部署大模型通常要经历以下过程:先有一个具备世界知识的基座模型,即通识教育阶段;在此基础上,形成不同专业类型的大模型,或将其蒸馏成小型模型,分别用于专门记忆知识、调用工具、掌握流程性知识(如熟悉公司业务流);最后实现不同大模型之间的协作,这标志着智能体协作时代的到来。
智能体发展路径
从技术角度看,智能体的发展路径如下:单智能体的发展离不开大模型的成功,大模型具备预训练、人类对齐、指令微调、情景学习等能力。进入智能体时代,智能体拥有记忆、规划、动作执行等功能,具备强大的思维链与反思能力,能够调用外部工具学习,还能与机械实体进行具身交互,若将大模型融入人形机器人或某台机器,便赋予其具身智能能力。此后,智能体将走向群体智能,多个智能体交互协作以提供决策。早期大模型受算力限制,存在实时性不足、幻觉现象以及专业知识欠缺等问题,如部分大模型知识仅更新至去年12月,显得“像人工智障”。随着技术演进,这些问题将逐渐被智能体的发展所解决。
智能体与RAG
RAG(Retrieval-Augmented Generation,检索增强生成)技术通过检索增强生成,显著提升了知识问答的准确性和时效性。在构建知识库时,RAG通过向量数据库和动态更新机制,实现了高效的知识检索与生成;在构建知识图谱时,RAG通过GraphRAG和Graphusion等框架,实现了实体关系的精准抽取与图谱融合。
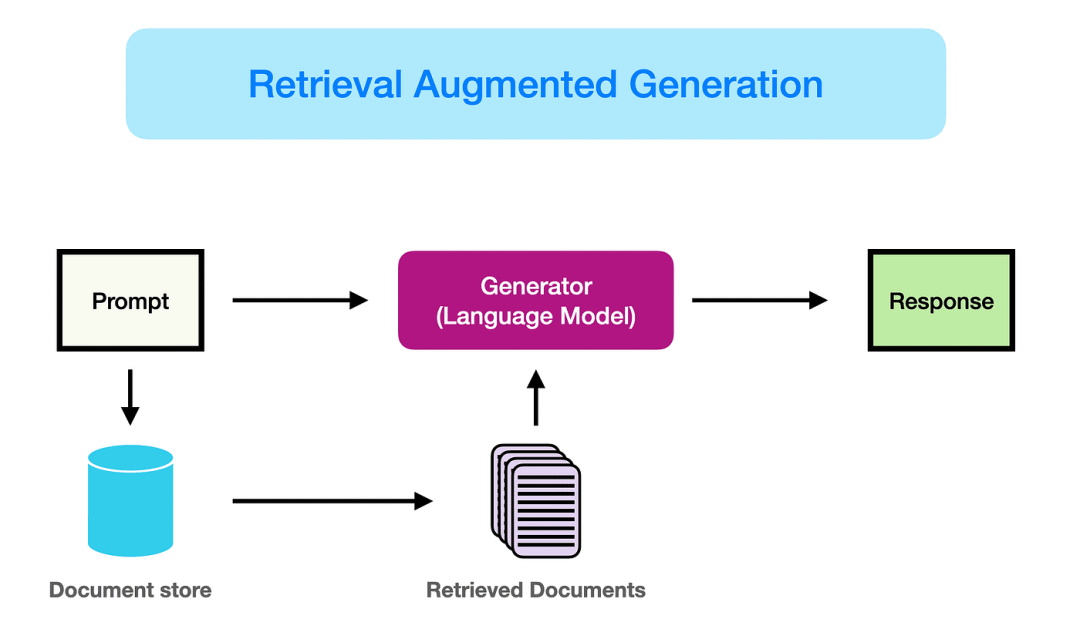
RAG(Retrieval-Augmented Generation,检索增强生成)是什么?RAG是一种结合信息检索与文本生成的人工智能技术,旨在通过引入外部知识库,解决大语言模型的幻觉问题。
RAG的核心目标是让大语言模型(LLM)在回答问题时不再仅依赖训练时的固化知识,而是动态检索最新或特定领域的资料来辅助生成答案。
RAG结合了信息检索与生成模型,通过以下三阶段工作:
-
检索:从外部知识库(如文档、数据库)中搜索与问题相关的信息。
-
增强:将检索结果作为上下文输入,辅助生成模型理解问题背景。
-
生成:基于检索内容和模型自身知识,生成连贯、准确的回答。
智能体与知识库
知识库(Knowledge Base)是什么?知识库是结构化、易操作的知识集群,通过系统性整合领域相关知识(如理论、事实、规则等),为问题求解、决策支持和知识共享提供基础平台。
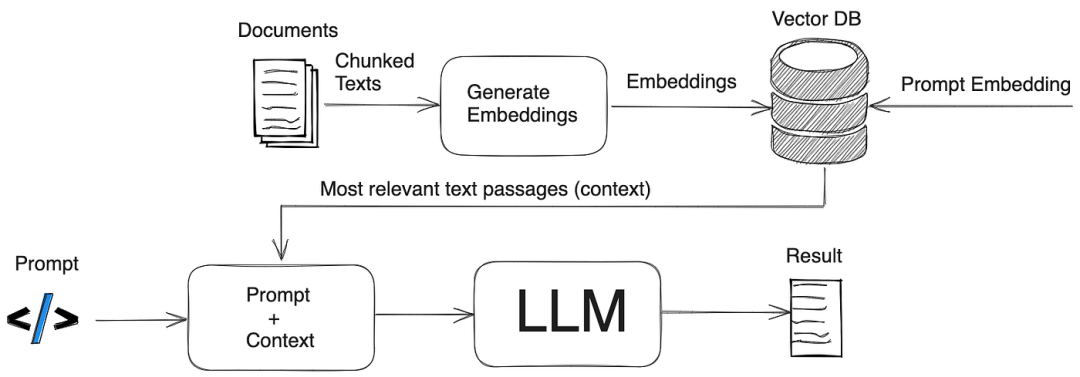
RAG构建知识库的核心在于将外部知识检索与大语言模型生成能力结合,通过高效检索为生成提供上下文支持,从而提升答案的准确性和时效性。(实战的重点在文本分块Chunking和向量化Embedding)
1. 文本分块(Chunking)
文本分块是将长文本分割为较小、可管理的片段,以便更高效地处理和分析。
2. 向量化(Embedding)
向量化是将文本或数据映射为高维向量空间中的数值表示,以捕获语义特征。
智能体与知识图谱
知识图谱(Knowledge Graph)是什么?知识图谱是一种通过实体与关系构建的语义化网络结构,支持推理与复杂查询,而传统知识库多以非关联的扁平化方式存储数据。
RAG构建知识图谱的核心是通过结合检索技术与大语言模型(LLM),将外部知识库中的结构化与非结构化数据整合为图谱形式。知识图谱为RAG系统注入结构化推理能力,使其从“信息检索器”进化为“知识推理引擎”。
RAG构建知识图谱的关键在于检索与生成的协同,其流程包括:
- 数据预处理:将文档分割为文本块(chunking),并通过命名实体识别(NER)提取实体与关系。
- 知识图谱索引:基于提取的实体与关系,构建初始知识图谱后,运用聚类算法(例如Leiden算法)对图谱中的节点进行社区划分。
- 检索增强:在用户查询时,通过本地搜索(基于实体)或全局搜索(基于数据集主题)增强上下文,提升生成答案的准确性。
智能体与Text2SQL
大模型的提示工程(Prompt Engineering) 是通过精心设计输入文本(Prompt),引导大语言模型(LLM)生成符合预期输出的技术。在Text2SQL(自然语言转SQL)和Text2API(自然语言调接口)场景中,提示工程的核心目标是将自然语言问题转化为准确的 SQL 查询和具体的 API 调用参数。
Text2SQL和Text2API的提示工程本质是是将领域知识显式化,通过角色定义和业务知识注入(如数据库Schema、API文档),让模型“理解”自然语言背后的真实意图,并将其转化为可执行的结构化指令。
Text2SQL(文本转SQL)是什么?Text2SQL是一种将自然语言描述的查询需求,自动转换为结构化查询语言(SQL)的技术。
如何实现Text2SQL?通过自然语言处理技术进行语义解析(包括实体识别、关系抽取、意图理解),结合预加载的数据库Schema信息,利用大语言模型(LLM)生成符合语法规范的SQL语句。
1. 输入解析:用户提问 → 提取关键实体(表名、字段、条件)。
-
-
例:“统计2024年销售额超过100万的产品” → 提取“销售额(sales)”、“产品(product)”、“年份(year=2024)”、“条件(>1,000,000)”。
-
2. Schema绑定:结合数据库表结构(Schema),明确字段和表关系。
-
- 关键:在Prompt中提供Schema,如:
表orders: id (int), product_id (int), sales (float), date (date) 表products: id (int), name (str), category (str)
- 关键:在Prompt中提供Schema,如:
3. SQL生成:模型根据Schema和用户意图生成查询语句。
智能体与Text2API
Text2API(文本转API调用)是什么?Text2API(文本转API调用) 是一种将自然语言描述的用户需求自动转换为对应用程序接口(API)的调用请求的技术。
如何实现Text2API?通过自然语言处理技术进行语义解析(含意图识别、实体抽取、上下文理解),结合预加载的API文档信息,利用大语言模型(LLM)生成符合语法规范的API调用请求。
1. API目录管理:维护API文档(端点、参数、权限)。
- 例:邮件API文档:
-
POST /send_email 参数:to (str), subject (str), content (str) 权限:需用户OAuth令牌
-
2. 意图识别:模型解析用户指令,匹配目标API。-
-
例:“给Allen发邮件,主题是项目开发进度,内容为‘本周完成80%’” → 调用
/send_email。
-
3. 参数填充:提取并验证参数(如邮箱、内容)。
数据蒸馏
数据蒸馏(Data Distillation)是什么?数据蒸馏通常关注于数据的处理和优化,旨在从原始数据集中提取出更具代表性和有用性的数据子集。
-
原始数据集:包含大量的、可能包含冗余和噪声的数据。
-
数据预处理:对原始数据进行清洗、去噪等处理,以提高数据质量。
-
特征提取:从数据中提取出关键特征,这些特征能够反映数据的本质属性。
-
数据降维:通过减少数据的维度,去除冗余信息,得到更为简洁的数据集。
-
精炼数据集:经过上述步骤处理后的数据集,具有更高的质量和代表。
在深度学习中,数据蒸馏通常是通过逐层过滤和提取特征来实现的。每一层都会对数据进行一定的变换和处理,使其更加接近最终的目标表示。
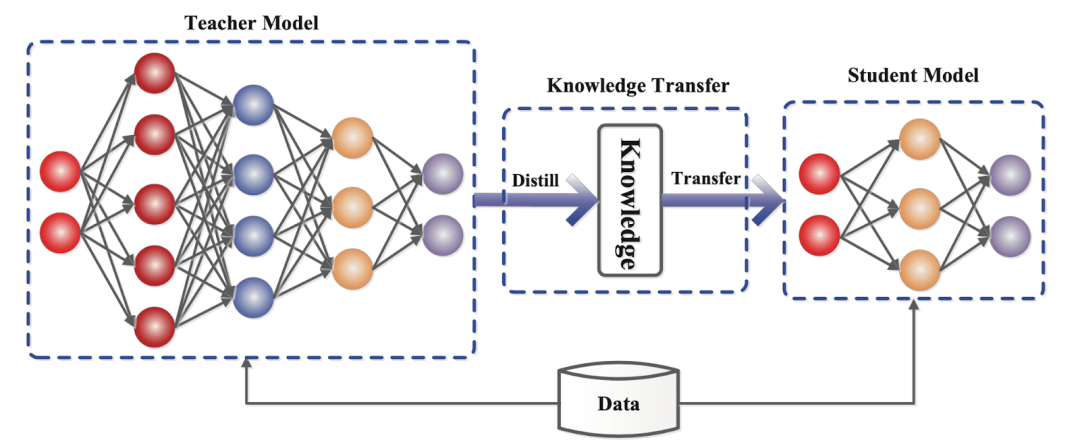
“数据蒸馏是一个数据处理与优化技术,它旨在从包含大量可能冗余和噪声的原始数据集中,通过一系列步骤如数据预处理、特征提取、数据降维等,提炼出一个高质量、低冗余且高度代表性的精炼数据集。”
知识蒸馏
知识蒸馏(Knowledge Distillation)是什么?知识蒸馏则是一种模型压缩和知识迁移的方法,旨在将大型教师模型中的知识转移到小型学生模型中。
-
教师模型(已训练):一个高精度、但可能较为复杂的大型模型。
-
提取知识:从教师模型的输出(如概率分布、中间特征等)中提取出有用的知识。
-
学生模型(待训练):一个轻量化、但性能可能较低的小型模型。
-
蒸馏训练:利用教师模型提取出的知识,作为学生模型的训练目标进行训练。
-
精炼学生模型:经过蒸馏训练后的学生模型,能够学习到教师模型的泛化能力,从而达到或接近教师模型的性能。
知识蒸馏从多个已经训练好的大型模型中,将知识转移给一个轻量级的模型。它主要关注于模型之间的知识传递,通过利用教师模型的输出(如概率分布或中间特征)作为软目标,来指导学生模型的训练。
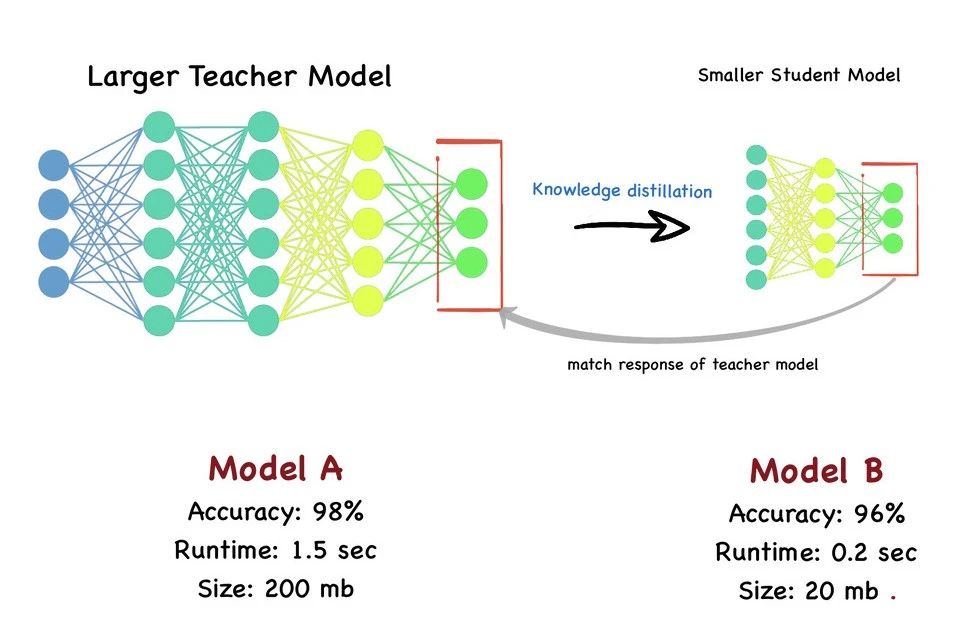
“知识蒸馏是一种模型压缩技术,旨在将大型、高精度教师模型中的关键知识提炼并传递给轻量化学生模型。通过这一过程,学生模型能在保持低计算成本的同时,学习到教师模型的泛化能力,实现性能的大幅提升,接近教师模型的性能水平。”

















 3769
3769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









