







 本文介绍2022年ICLR论文提出的instruction tuning方法,得到FLAN模型。该方法通过指令描述数据集让LM微调,提高其在没见过任务上的零样本表现能力。文中阐述了指令微调细节、数据与模型评估方式,实验表明指令微调对特定格式数据集效果更好,且在大模型上作用明显。
本文介绍2022年ICLR论文提出的instruction tuning方法,得到FLAN模型。该方法通过指令描述数据集让LM微调,提高其在没见过任务上的零样本表现能力。文中阐述了指令微调细节、数据与模型评估方式,实验表明指令微调对特定格式数据集效果更好,且在大模型上作用明显。
诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:Finetuned Language Models Are Zero-Shot Learners
ArXiv网址:https://arxiv.org/abs/2109.01652
官方GitHub项目:https://github.com/google-research/flan
因为用的是TensorFlow所以我也不咋想看这代码……需要的话再看吧。
本文是2022年ICLR论文,作者来自谷歌。
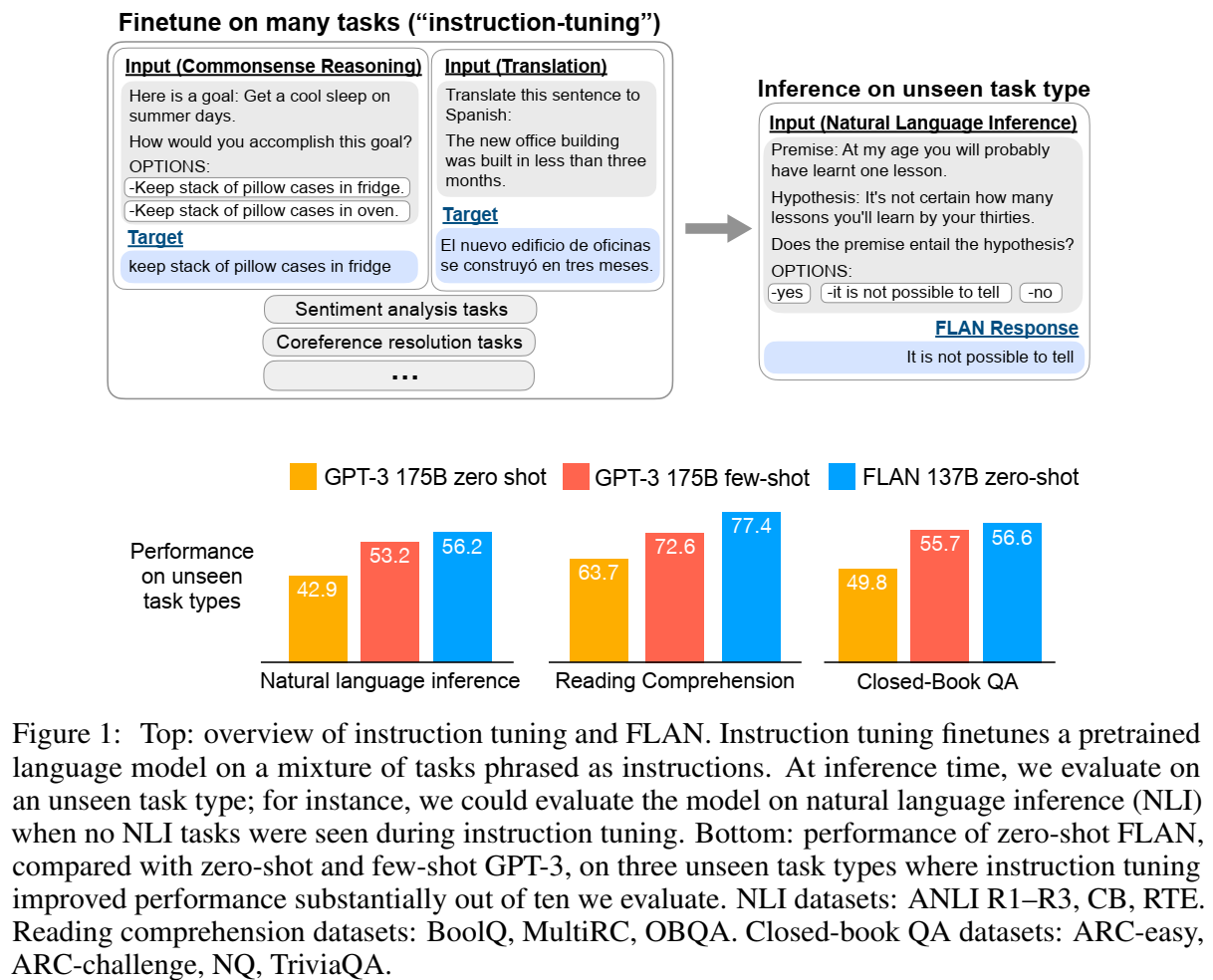
本文提出了instruction tuning(指令微调)方法,得到的模型叫FLAN (Finetuned Language Net):通过指令描述一堆数据集,用LM在这些数据集上微调,然后LM就能在别的用instruction描述的数据集上面的表现效果也有所提升。即提高LM在没见过任务上的零样本表现能力。
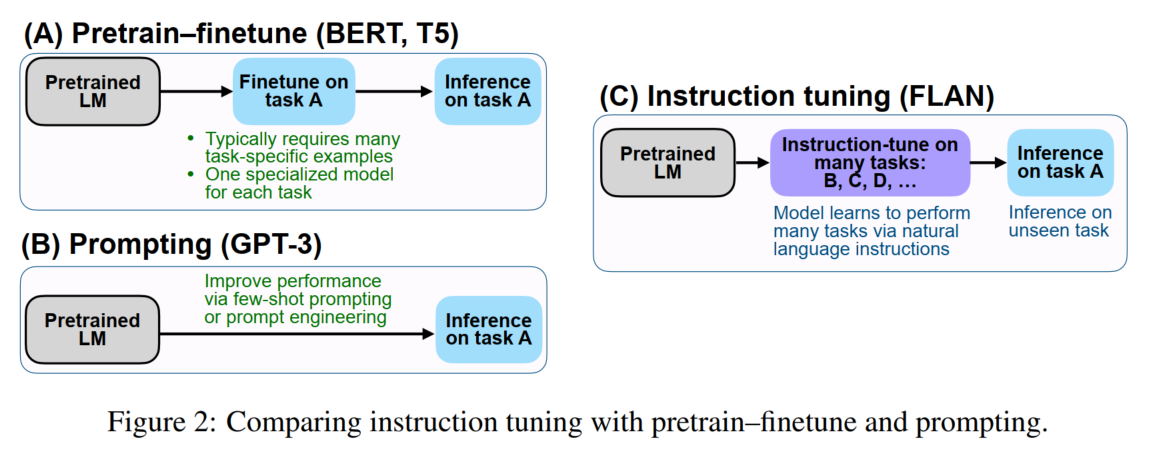
就直接教模型学如何理解指令了,而不是学习特定任务集的解法。
本文采用的基模型是LaMDA-PT:主要语言是英语,仅用语言模型损失函数微调。
附录太多了,我就简单看了一下,本文大部分内容就不写了。
1. 研究背景
GPT-3等模型在少样本场景下表现好,在零样本条件下不够好。
2. 指令微调
从训练集中随机抽样样本,由于数据集规模不同,因此限制每个数据集抽取30k个样本,并遵循T5的examples-proportional mixing scheme(mixing rate maximum为3k,即一个数据集中超过3k的样本不再有额外的采样权重,我的理解就是采样权重降低)和packing(将多个训练样本放到一个sequence里,在targets中用EOStoken分隔)
优化器是Adafactor1
其他细节略
3. 数据与模型评估
将数据集按类型分成簇,在评估时在其他簇上指令微调,用目标簇进行评估。(也不指令微调相似簇,比如阅读理解和常识推理,重述和NLI)
也就是说,在
c
c
c个簇上评估,就构建
c
c
c个FLAN模型。
(谷歌是真的壕)
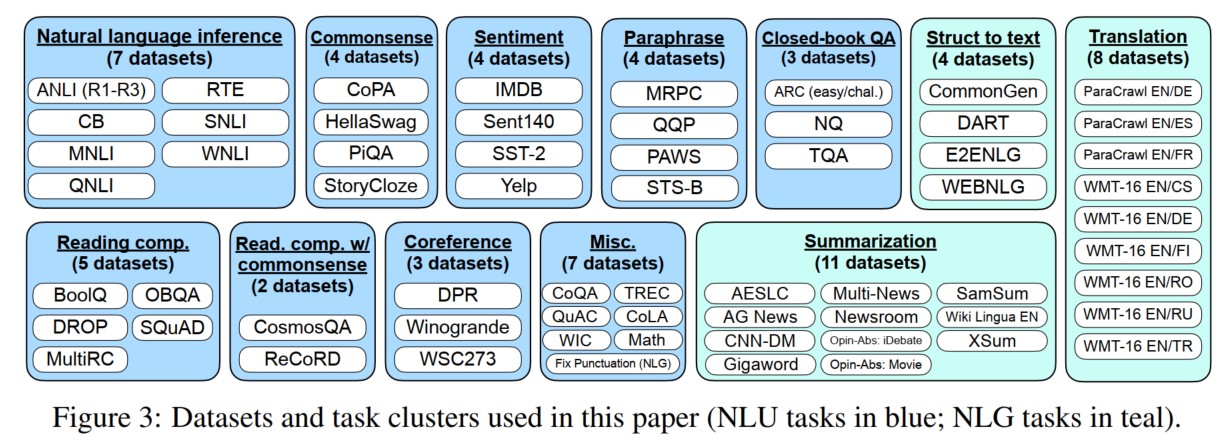
对每个数据集人工构建10个用指令描述数据集任务的模版:

(https://github.com/google-research/FLAN/blob/main/flan/templates.py:这个里面应该就是这些模版)
对于分类任务,GPT-3采用的rank classification方案是选择输出概率更高的作为预测结果,这种方案的问题在于,由于对同一答案存在不同的表述方式,只认某一表达的输出概率可能不公平。因此本文采用 options suffix 技术,在任务描述后增加OPTIONS token + 类的指定输出集合。(如Fig1所示)
这个options的代码应该是https://github.com/google-research/FLAN/blob/e9e4ec6e2701182c7a91af176f705310da541277/flan/v2/preprocessors.py#L158 format_options() 函数,形式应该就是这两种(我不会TensorFlow所以我直接拿代码去问的ChatGPT):
形式一:
OPTIONS:
(A) 选项一
(B) 选项二
(C) 选项三
形式二:
OPTIONS:
- 选项一
- 选项二
- 选项三
4. 实验结果
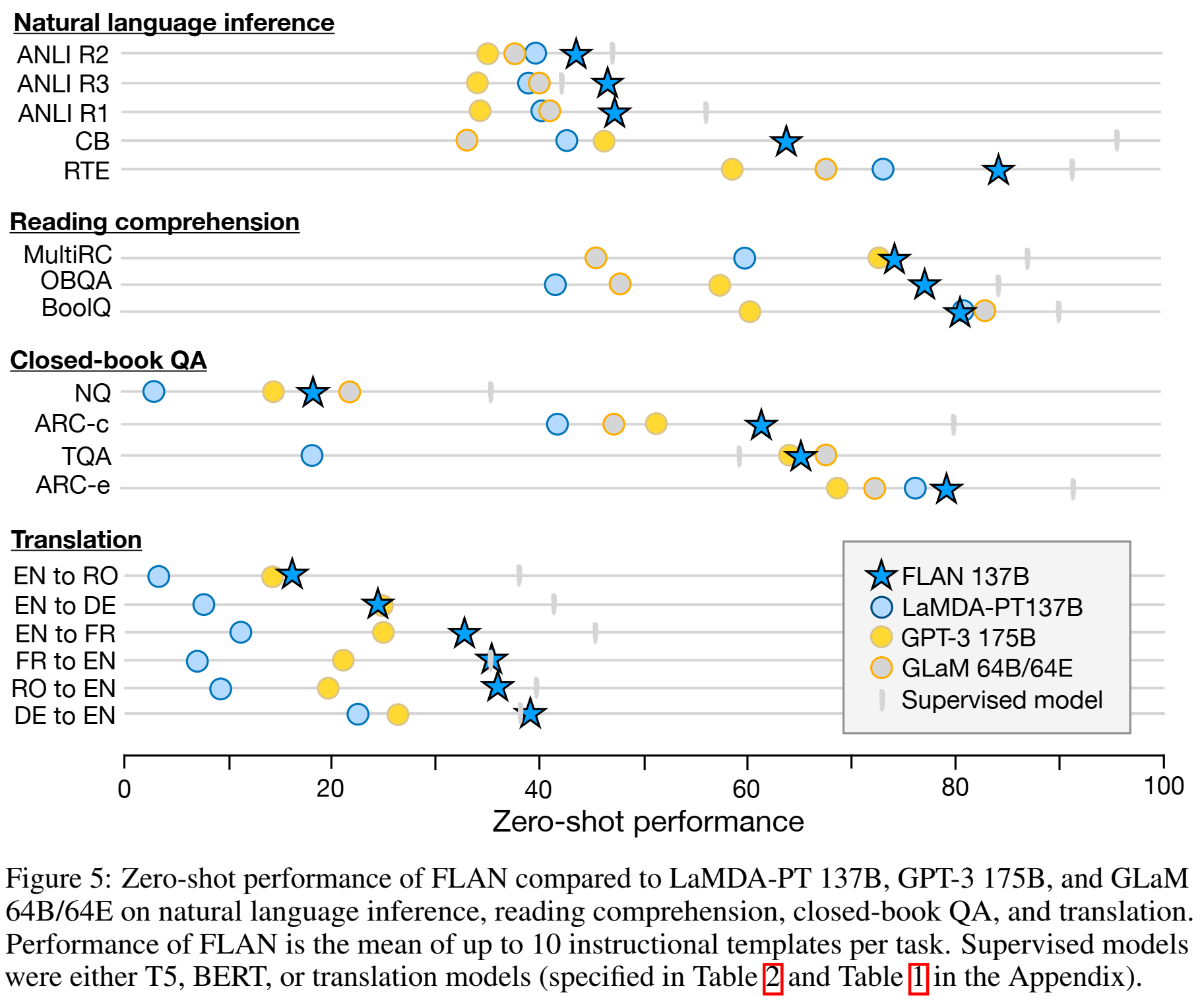
GPT-3和GLaM的实验结果是直接从原文扒下来的。
指令微调对指令格式的数据集((e.g., NLI, QA, translation, struct-to-text)效果更好,对语言模型格式的(指令没什么用的场景,如补全文字)没那么好。
细节略。
消融实验
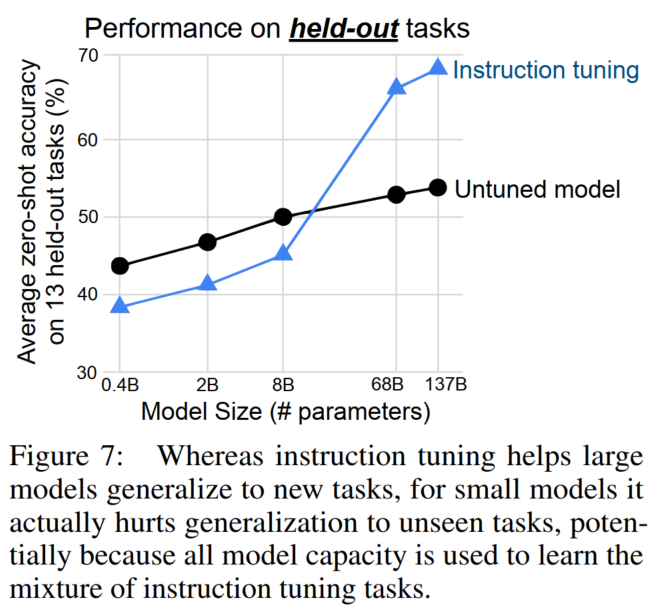
任务分类更精细和提高在未知任务上的效果,指令微调仅在模型尺寸够大时可用。
增加训练集,效果更好:(就算是谷歌也没钱一个一个做消融实验了吧)
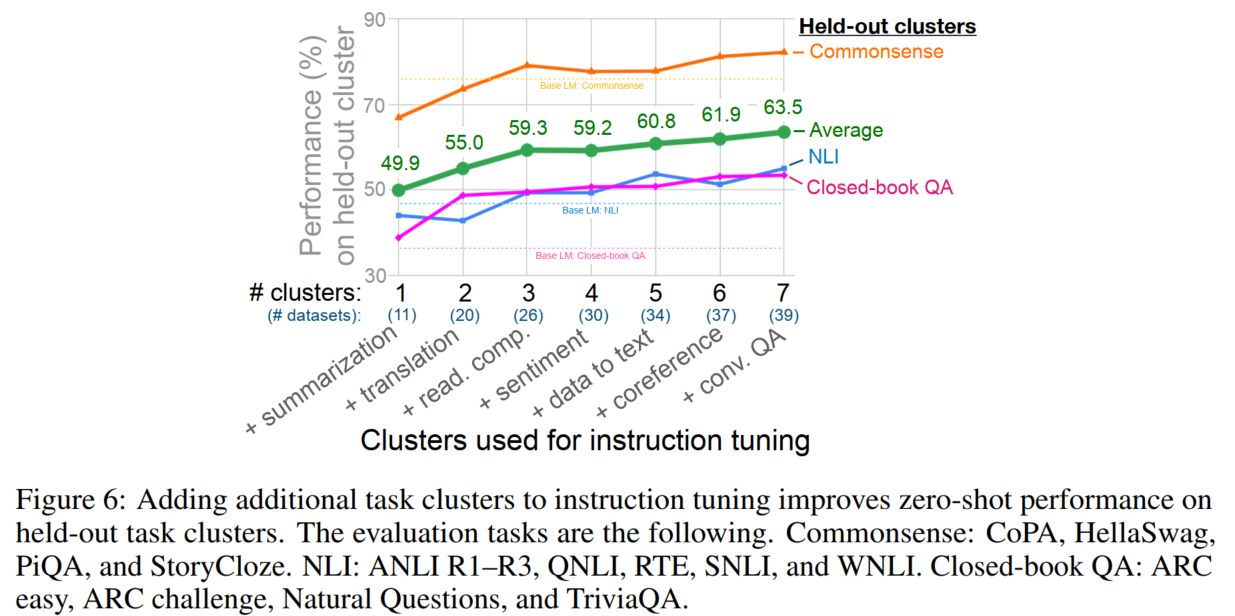
Scaling laws:
模型尺寸增加,准确率提升。在大模型上指令微调才有效果:
证明指令的作用(而不是纯属因为多任务学习提升了效果):

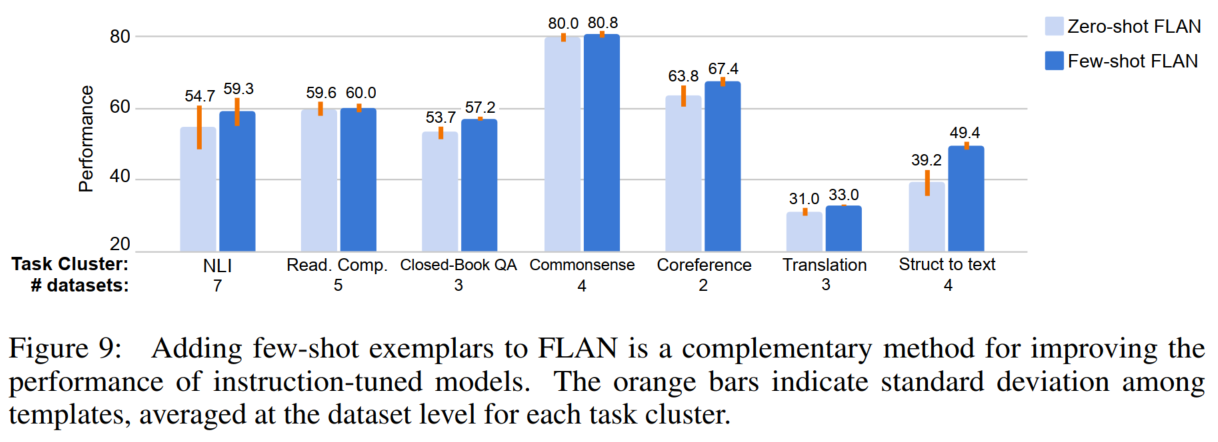
FLAN在少样本测试时的效果:
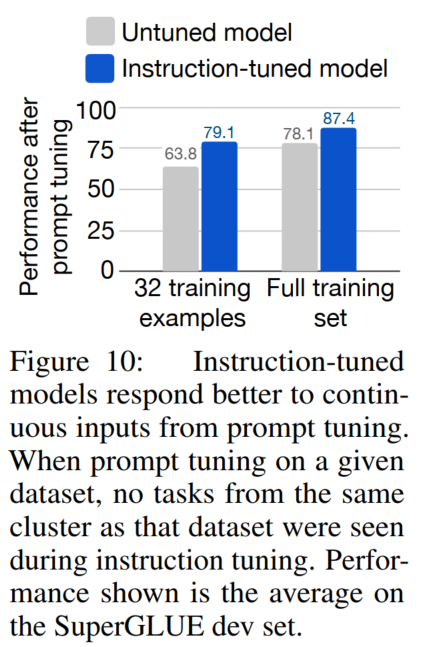
FLAN在提示微调上效果更好:(template prompt tuning2)
5. 附录
1. 跟GPT-3和T5的prompt的区别

T5 prompt主要用于区分数据集,GPT-3 prompt的目标是靠近预训练数据格式然后让模型进行文本补全。FLAN的prompt如果没有微调效果并不好。
2. 限制
会出现一些弱智bad case。
上下文限长只有1024。


















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











