










引言:认识AI Agent
在当前AI领域,传统的大语言模型(如GPT、Claude等)展现出了强大的语言理解和生成能力。但这些模型有一个根本性的限制:它们只能进行文字对话,给出建议和答案,却无法真正执行任何实际任务。例如:
-
当你让传统大模型查询实时天气时,它只能告诉你"我可以告诉你如何查询天气"
-
当你请求获取最新新闻时,它只能回答"我的知识可能不是最新的"
-
当你需要处理数据文件时,它只能描述处理步骤,而不能实际操作文件
这就是为什么我们需要AI Agent。AI Agent通过将大语言模型与各种工具和执行环境相结合,真正打破了"只能对话"的限制,使AI系统能够:
-
调用API获取实时信息
-
执行文件操作和数据处理
-
进行网络搜索
-
与其他系统交互
-
完成实际的任务执行
AI Agent的三大核心组件
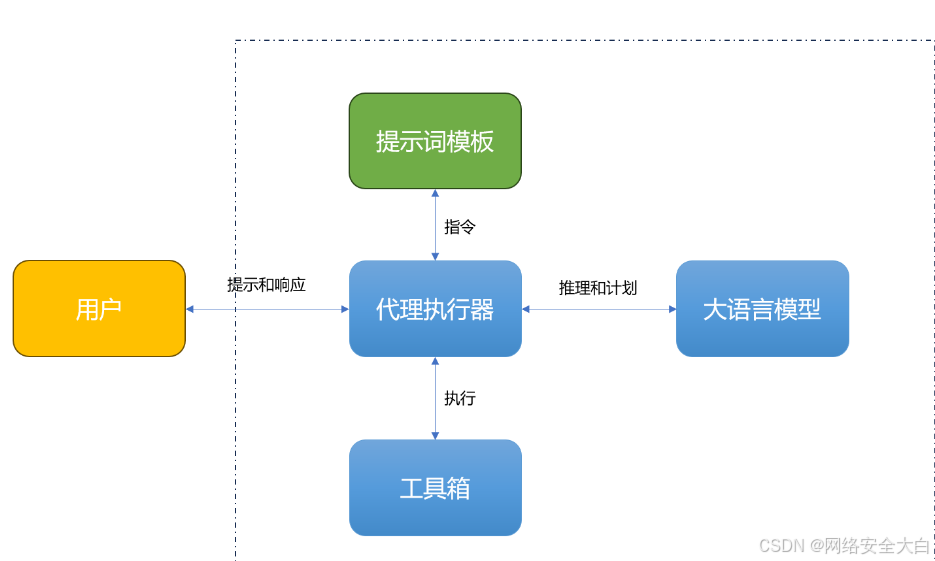
让我们通过一个不到100行实际的示例程序来理解AI Agent的架构,读者可以在文章末尾看到完整的程序代码:
1. 模型组件(Model)
模型是AI Agent的"大脑",负责理解用户输入并做出决策。在我们的示例中,使用了Azure OpenAI的模型:
from langchain_openai import AzureChatOpenAI
# Initialize Azure OpenAI model
model = AzureChatOpenAI(
azure_endpoint=azure_endpoint,
api_version=azure_api_version,
deployment_name=azure_deployment_name,
api_key=azure_api_key,
)
模型的主要职责:
-
理解用户的自然语言输入
-
判断是否需要使用工具
-
解析工具返回的结果
-
生成合适的回复
2. 工具组件(Tools)
工具是AI Agent与外界交互的接口。在示例中,我们使用了Tavily搜索工具:
from langchain_community.tools.tavily_search import TavilySearchResults
# Initialize Tavily search
search = TavilySearchResults(max_results=2)
# Create tools list
tools = [search]
工具的特点:
-
功能单一明确
-
有标准化的输入输出接口
-
可以动态添加和组合
-
支持异步操作
3. 代理执行器(Agent Executor)
执行器是连接模型和工具的核心组件,它使用ReAct(Reasoning and Acting)范式来协调整个系统:
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
agent_executor = create_react_agent(model, tools, checkpointer=memory)
执行器的工作流程:
-
接收用户输入
-
调用模型理解意图
-
决定是否使用工具
-
执行工具调用
-
处理结果并生成回复
实际运行示例
让我们看看AI Agent如何处理不同类型的请求,特别关注模型是如何决定是否使用工具的:
示例1:无需工具的基础对话处理
# 配置执行环境
config = {"configurable": {"thread_id": "abc123"}}
# 示例1:简单问候
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="你好!")]}, config
):
print(chunk)
输出结果:
{
"messages": [
{
"role": "assistant",
"content": "你好!很高兴见到你。我是一个AI助手,有什么我可以帮你的吗?"
}
]
}
----
在这个简单的问候场景中,模型能够独立生成响应,模型不需要使用任何外界工具即可完成对话。
示例2:模型自主判断不使用工具的知识查询
# 示例2:基础知识查询
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="水浒传的作者是谁?")]}, config
):
print(chunk)
print("----")
输出结果:
{
"messages": [
{
"role": "assistant",
"content": "《水浒传》的作者是施耐庵。施耐庵(约1296年-1372年),本名施仁,字耐庵,号子安,宋末元初人,江苏兴化人。他是中国古典小说四大名著之一《水浒传》的作者。"
}
]
}
----
此示例展示了模型处理已在其知识库内的问题时,如何判断无需调用外部工具,直接给出答案。
示例3:模型智能判断并使用工具获取实时信息
# 示例3:需要搜索的复杂查询
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="中国电影票房2024年前10名")]}, config
):
print(chunk)
输出结果:
{
"messages": [
{
"role": "assistant",
"content": "让我帮您搜索一下2024年中国电影票房榜的最新信息。"
}
]
}
----
{
"messages": [
{
"role": "assistant",
"content": "根据最新搜索结果,2024年目前中国电影票房前10名如下:..."
}
]
}
----
该示例说明模型在分析问题后,确定需要实时数据,主动调用工具来获取外部信息进行回答。
从这三个示例可以看出,AI Agent具备智能的工具使用决策能力:
-
对于简单对话,直接响应
-
对于基础知识问题,利用模型自身的知识库
-
对于需要实时或最新数据的查询,才会调用外部工具
这种智能决策机制不仅提高了系统效率,也展示了AI Agent在实际应用中的适应性和智能性。模型会根据问题的性质、所需信息的时效性、以及自身知识的覆盖范围,来决定是否需要调用外部工具。
总结与实践展望
当前AI领域正在经历一个关键的转折点:从"能说会道"走向"能做善成"。AI Agent的出现和发展,代表了人工智能从"纸上谈兵"到真正解决实际问题的重要跨越。这为整个行业带来了巨大的机遇:
- 技术层面的机遇
-
将强大的语言理解能力转化为实际的执行能力
-
通过工具集成实现AI能力的无限扩展
-
打造真正能够帮助人类的智能助手
-
降低AI应用的开发门槛
- 应用领域的机遇
-
个人助理:帮助处理日常任务、信息整理、日程管理
-
企业自动化:流程处理、数据分析、客户服务
-
研发辅助:代码开发、调试、文档生成
-
创意领域:内容创作、设计辅助、市场分析
- 商业价值
-
提高工作效率,降低人力成本
-
创造新的服务模式和商业模式
-
实现24/7全天候服务
-
打造智能化竞争优势
AI Agent代表了一个全新的发展方向:不再满足于模型只能进行对话,而是要真正帮助人类完成工作。这种转变带来的机会是巨大的:
-
对开发者而言:提供了构建实用AI应用的框架和工具
-
对企业而言:开启了业务流程自动化的新可能
-
对最终用户而言:带来了真正能帮助解决问题的AI助手
未来,我们可以期待看到:
-
更多样化的工具集成
-
更智能的任务规划能力
-
更自然的人机协作模式
-
更广泛的应用场景
结语
AI Agent的出现,标志着AI正在从"能力展示"迈向"价值创造"。它不仅代表了技术的进步,更开启了AI真正服务于人类的新篇章。对于开发者、企业和用户来说,现在正是探索和实践的最佳时机。
本文提到的完整程序代码
import os
from dotenv import load_dotenv
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_openai import AzureChatOpenAI
from langchain_core.messages import HumanMessage
# Load environment variables from .env file
load_dotenv()
# Set up Langchain tracing
os.environ["LANGCHAIN_TRACING_V2"] = os.getenv("LANGCHAIN_TRACING_V2", "false")
os.environ["LANGCHAIN_API_KEY"] = os.getenv("LANGCHAIN_API_KEY", "")
# Load Tavily API key
tavily_api_key = os.getenv("TAVILY_API_KEY")
# Ensure the Tavily API key is set
if not tavily_api_key:
raise ValueError("Tavily API key not found. Please set TAVILY_API_KEY in your .env file.")
# Initialize Tavily search
search = TavilySearchResults(max_results=2)
# If we want, we can create other tools.
# Once we have all the tools we want, we can put them in a list that we will reference later.
tools = [search]
# Set up Azure OpenAI
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT")
azure_api_key = os.getenv("AZURE_OPENAI_API_KEY")
azure_api_version = os.getenv("AZURE_OPENAI_API_VERSION")
azure_deployment_name = os.getenv("AZURE_OPENAI_DEPLOYMENT_NAME")
# Ensure all necessary Azure OpenAI variables are set
if not all([azure_endpoint, azure_api_key, azure_api_version, azure_deployment_name]):
raise ValueError("One or more Azure OpenAI environment variables are missing. Please check your .env file.")
# Initialize Azure OpenAI model
model = AzureChatOpenAI(
azure_endpoint=azure_endpoint,
api_version=azure_api_version,
deployment_name=azure_deployment_name,
api_key=azure_api_key,
)
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
agent_executor = create_react_agent(model, tools, checkpointer=memory)
config = {"configurable": {"thread_id": "abc123"}}
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="你好!")]}, config
):
print(chunk)
print("----")
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="水浒传的作者是谁?")]}, config
):
print(chunk)
print("----")
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="中国电影票房2024年前10名")]}, config
):
print(chunk)
print("----")
👉AGI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉AGI大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
👉AGI大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









