







声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
之前的几期推文里推出过Transformer以及优化Transformer(BKA-Transformer)预测的模型:
应后台小伙伴的要求,今天继续给大家推出几个小创新模型,包括Transformer-LSTM、Transformer-GRU、Transformer-BiLSTM。每个模型对应不同的数据集效果可能均不相同,大家需要进行尝试才知道哪个模型与自己的数据集最为匹配。
因此,为了方便大家的选择,本期推文这几个模型都是一次购买直接全部打包带走!!
原理简介
这里不再过多复杂的介绍公式,原始的Transformer模型模型结构图如下:
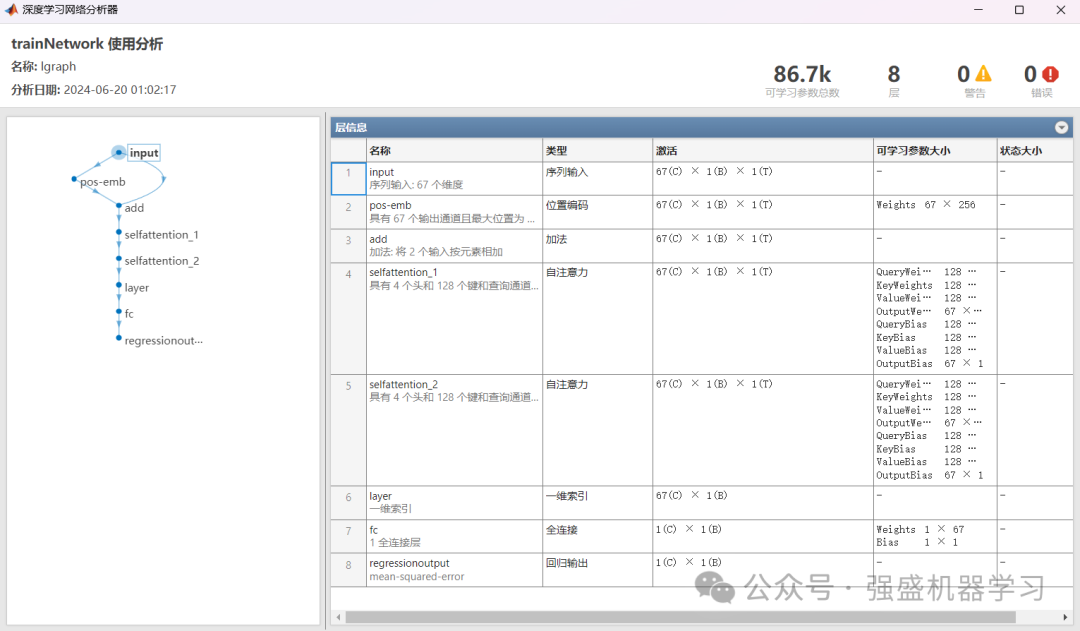
那么,如何嵌入LSTM/GRU/BiLSTM模块呢?这里以LSTM为例,采用串联方式,也就是在两个自注意力层后加入LSTM模型,加入LSTM后的模型结构图如下所示:
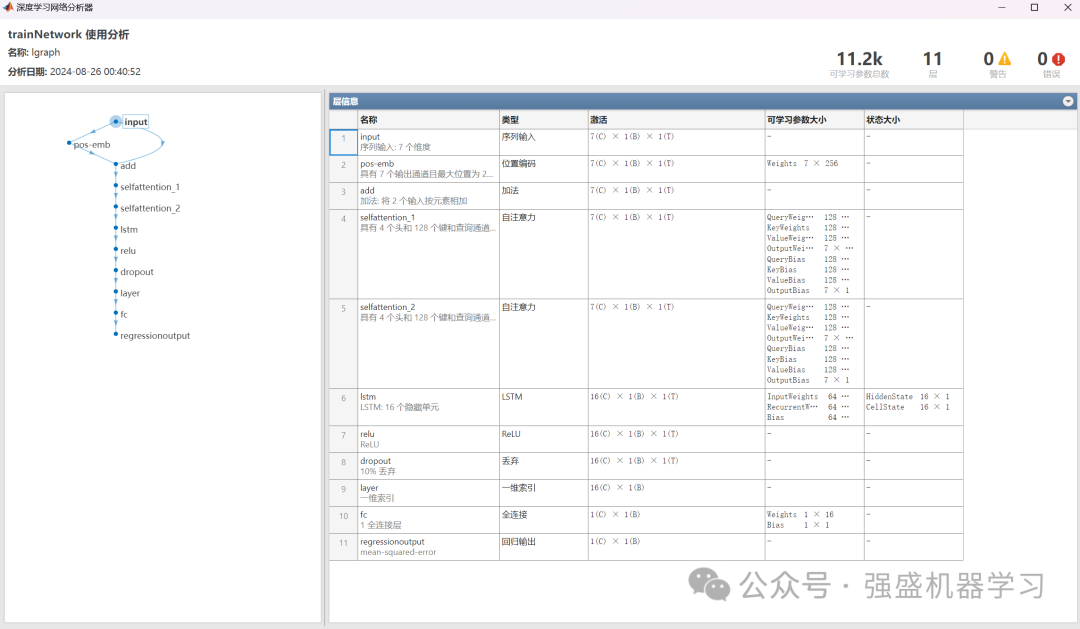
同时,加入了dropout模块可以在一定程度上防止过拟合。整体模型中,通过Transformer和LSTM进行连接,能够捕捉序列中的复杂依赖关系和长期信息。
数据介绍
本期采用的数据是经典的回归预测数据集,是为了方便大家替换自己的数据集,各个变量采用特征1、特征2…表示,无实际含义,最后一列即为输出。
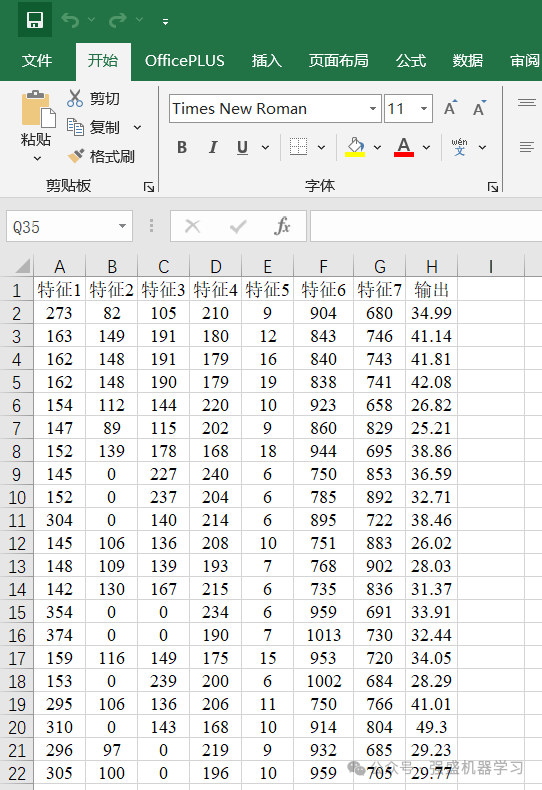
更换自己的数据时,只需最后一列放想要预测的列,其余列放特征即可(特征数量不限),无需更改代码,非常方便!
结果展示
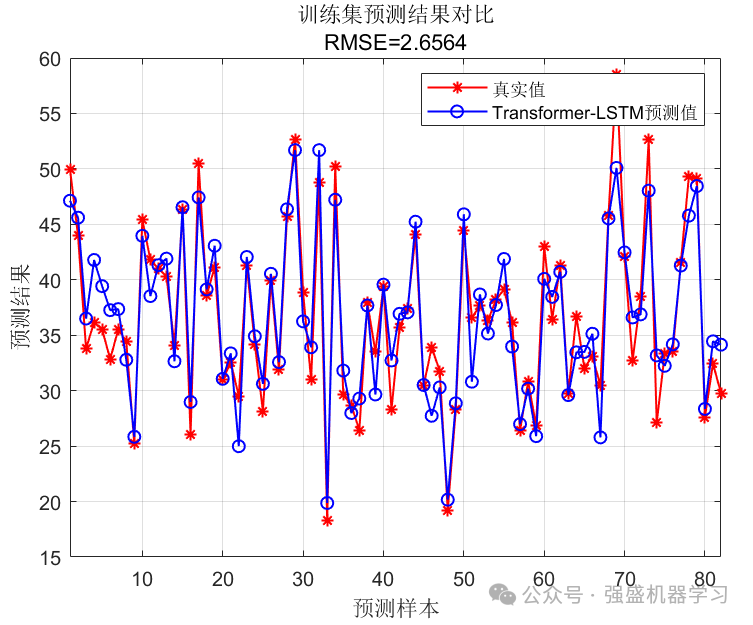
这里以Transformer-LSTM模型为例,设置最大训练次数为200次,初始学习率为0.001,最大位置编码长度为256,自注意力机制中的头数为4,每个头的键的通道数为4*32,利用上文的测试数据进行训练和测试,得到的结果如下所示(其余两个模型出图效果均类似):
训练集预测效果图:
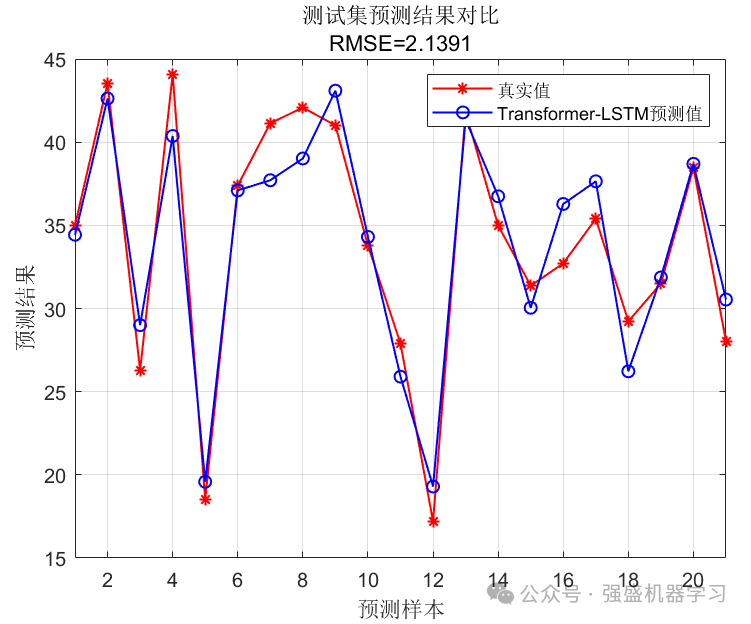
测试集预测效果图:
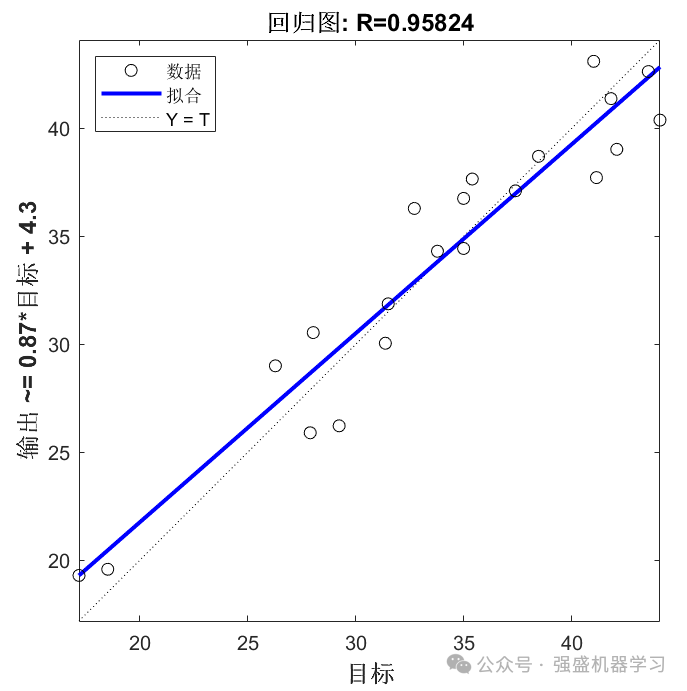
回归拟合图:
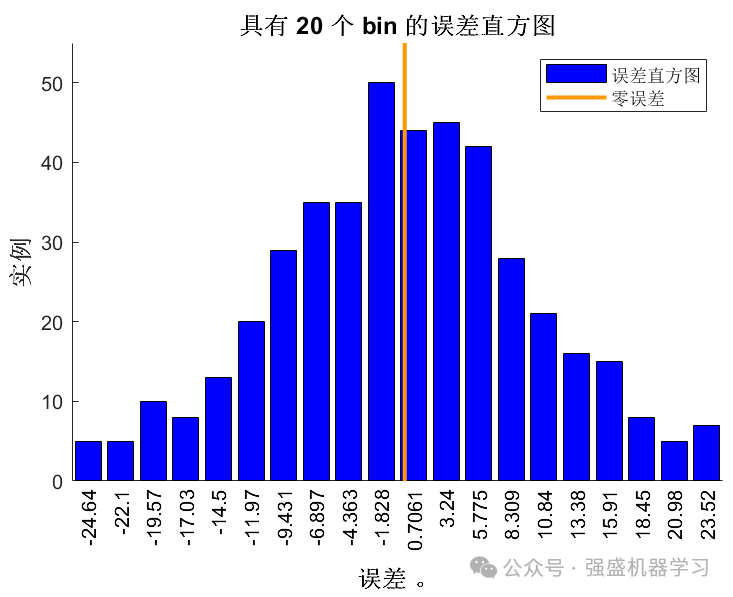
误差直方图:
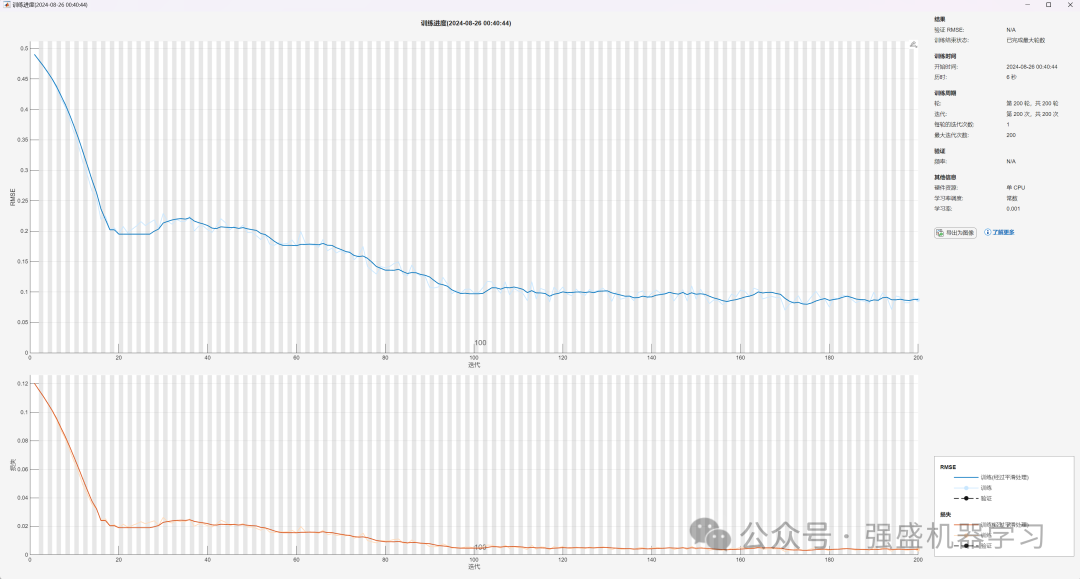
训练进度:
网络结构图:
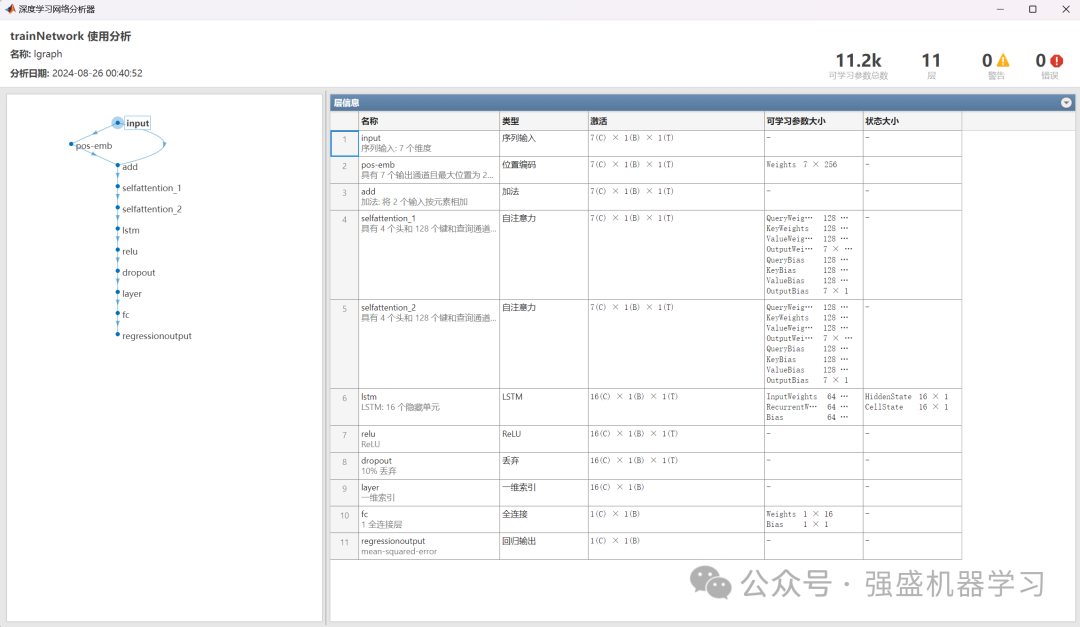
最后控制台也会输出完整的误差指标结果:
全家桶目录
完整代码
点击下方小卡片,再后台回复关键词:
TLGB
其他更多需求或想要的代码均可点击下方小卡片,再后台私信,看到后会秒回~















 1300
1300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









