









声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
创新点一:利用24年一区顶刊优化算法AE实现超参数自动优化:
创新点二:结合Transformer-LSTM新颖模型实现预测
经常有小伙伴问我区间预测里能不能加上一些优化算法,凸显创新性。因此,今天,对我们之前推出的区间预测全家桶进行更新,将最新推出的阿尔法进化算法AE优化Transformer-LSTM-ABKDE模型加入到我们的全家桶当中,非常新颖,包含三大创新点,后文也会一一介绍。
传统的点预测相信大家已经做腻了,审稿人也看腻了。其输出的仅有一个预测值,无法定量描述预测结果的不确定性。
而区间预测能够得到预测值可能出现的范围,即给出上界和下界。目前应用在光伏、风电功率预测比较多,而如果你想应用在其他学科,比如碳价预测、剩余寿命预测、降水量预测等等,完全是一个创新的机会,给审稿人眼前一亮,也能增加工作量和Accept的概率,传统点预测能发的期刊,你加上区间预测不就能更上一层了吗?
如果你之前购买过区间预测全家桶,此次推出的模型免费下载即可,需要代码的朋友可直接拉到最后~
同样,我们提出的这个模型在知网和WOS平台依旧都是搜不到的,属于尚未发表的创新点,不信可以看下图:
知网平台:
SCI检索平台(WOS):
您只需做的工作:替换Excel数据,一键运行main文件!非常适合新手小白!
数据输入格式
本期数据使用的依旧是多变量回归数据集,是某地一个风电功率的数据集,经过处理后有3个特征,分别用特征1、2、3来表示,具体特征含义大家不必深究,这边只是给大家提供一个示例而已,大家替换成自己的数据集即可~
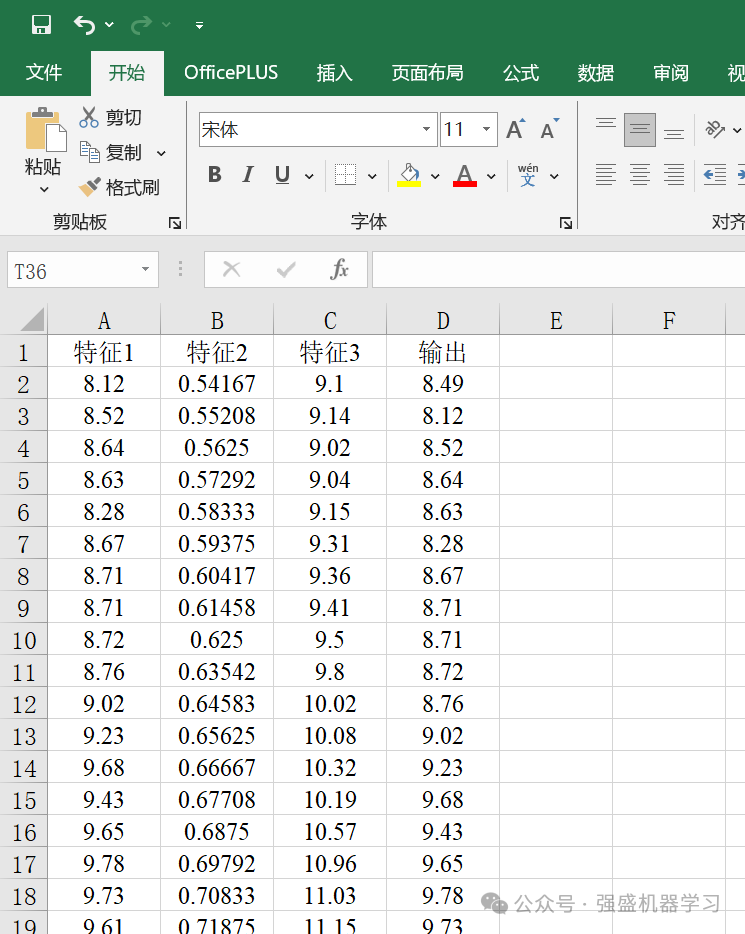
更换自己的数据时,只需最后一列放想要预测的列,其余列放特征即可,无需更改代码,非常方便!
原理简介与创新点
创新点一:利用24年一区顶刊优化算法AE实现超参数自动优化:
阿尔法进化算法(Alpha evolution, AE)于2024年11月发表在SCI一区顶刊《Engineering Applications of Artificial Intelligence》上!该算法灵感新颖,具有强大的进化能力、快速的搜索速度和出色的寻优能力。该算法刚刚提出,提出时间极短。目前,还没有使用该算法的文献,可以说,你先用,你就是创新。
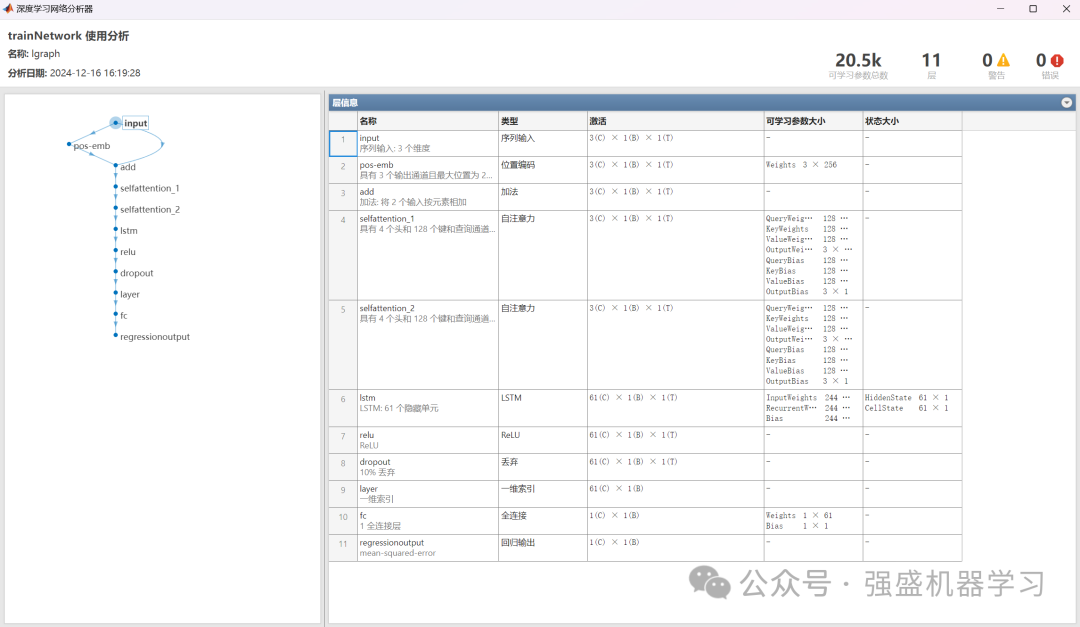
在我们的模型中,利用AE算法优化Transformer-LSTM模型的自注意力机制头数、LSTM隐藏层节点数、学习率、L2正则化系数。
原文作者在CEC2017基准函数上与106种算法进行了比较,并用于解决多序列比对和工程设计问题。结果表明,AE算法在勘探开发、收敛速度和精度、避免局部最优、适用性和可靠性等方面具有竞争力。
具体原理和测试效果可以查看这篇推文:
2024年SCI一区最新算法-阿尔法进化算法(AE)-公式原理详解与性能测评 Matlab代码免费获取
创新点二:结合Transformer-LSTM新颖模型实现预测
Transformer模型采用并行机制,本身是适用于自然语言处理任务,可以很好地实现机器翻译的任务,而当Transformer模型应用于时序数据预测时,输入序列可能会存在时间信息的缺失;且时间序列滑动窗口数据之间的映射和机器翻译任务不同,带掩码的多头注意力层(Masked Multi-Head Attention)是用于确保在生成文本序列时,模型只能看到当前位置之前的内容,以确保生成的文本是合理连贯的。而在时间序列预测中,模型的输入是已知的历史时间数据,而输出是未来时间的预测值,在这种情况下,是不需要解码器的注意力层结构的。这也回答了开头文中的问题。
LSTM模型作为一种循环神经网络,适用于序列数据的建模,其在时间序列预测任务中表现出色,能够更好地捕捉到数据的动态模式。因此,创新性地尝试将传统Transformer模型中的Decoder层修改为全连接层,用LSTM层替换原来的注意力层,结构如下图所示。
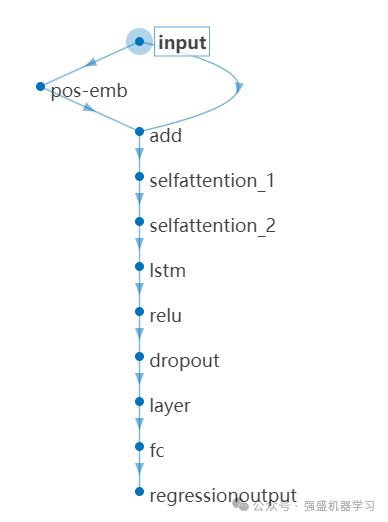
创新点三:利用改进的核密度估计(自适应)实现区间概率预测
自适应带宽核函数密度估计(Adaptive Bandwidth Kernel Density Estimation, ABKDE)是一种用于估计概率密度函数的非参数方法,它使用核函数对数据进行平滑处理,并通过自动选择合适的带宽参数来适应数据的本地特性。
在传统的核密度估计中,带宽参数控制着核函数的宽度,从而影响了平滑程度和估计的准确性。而自适应带宽核函数密度估计则通过将带宽参数作为每个数据点的函数来进行估计,从而使得每个数据点都有自己独立的带宽参数。
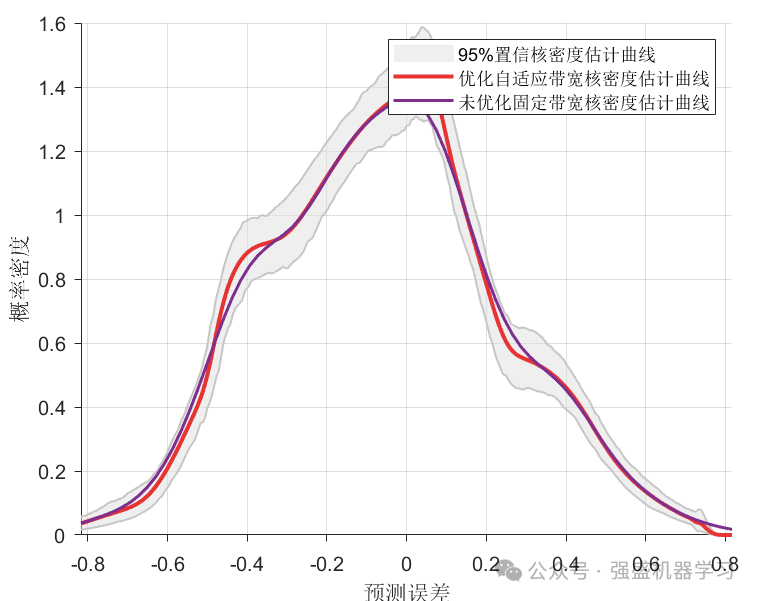
而在核密度估计中,带宽最影响预测区间质量,如何确定合适的全局带宽是值得研究的问题。使用黄金分割法对带宽进行寻优可以简单高效地找到全局最优带宽。黄金分割法又称0.618法, 由美国的基弗(Kiefer)在1953年提出,后逐渐被广泛应用,具有简单、收敛速度极快的特点,且目标函数存在单峰极值点。其主要思想是通过不断缩小区间的长度来搜索目标函数的零点,且 是按照可行域全长的0.618(及0.382)选取新点。相比于固定带宽的方法,自适应带宽核函数密度估计可以提供更准确的概率密度估计,并更好地捕捉到密度函数的细节和变化。
模型流程
再介绍一下我们的这个模型是怎么实现的以及它的流程:
1.数据导入:从Excel文件中读取数据,设定最后一列为输出变量,其余列作为特征变量。
2.训练集与测试集划分:按比例划分训练集和测试集,比例暂定为70%。
3.数据归一化:对训练集和测试集的特征和标签进行归一化处理,以提高模型训练效率。
4.优化算法确定超参数:使用AE优化算法确定Transformer-LSTM模型的最优参数,包括学习率、隐藏层节点数和正则化系数。
5.构建模型:建立Transformer-LSTM网络,更好地捕捉到数据的动态模式。
6.模型训练:将AE算法确定的最优参数代入该模型,使用训练集对Transformer-LSTM模型进行训练。
7.模型预测:利用训练好的模型对训练集和测试集进行预测,然后对预测结果进行反归一化。
8.区间概率预测:得到训练集误差,设置置信区间,进行自适应带宽核密度估计。
9.核密度估计:确定采样点,进行核密度估计,得到核密度估计图片。
10.性能评估:通过绘制真实值与预测值的对比图、概率密度图、误差分布图等,并计算R^2、MAE、RMSE、MAPE、PICP、PINAW、CRPS等指标,评估模型性能。
效果展示
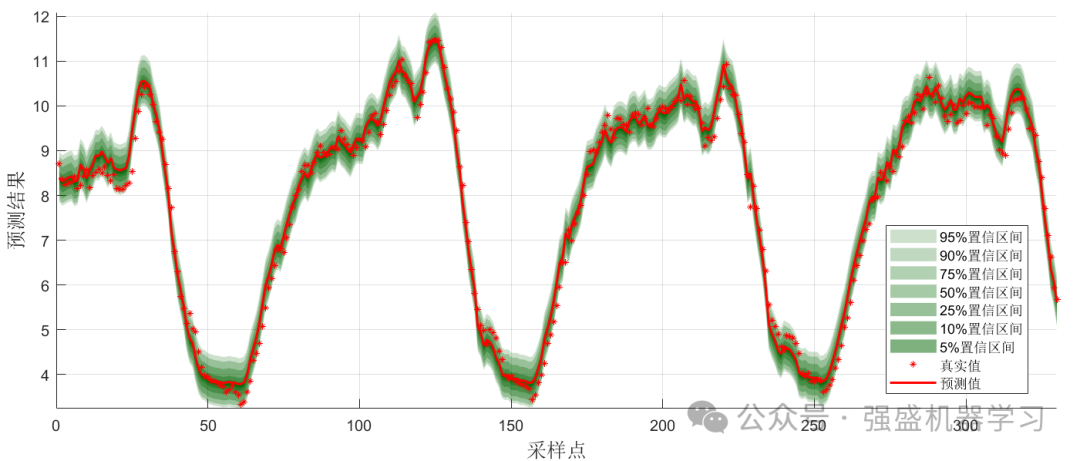
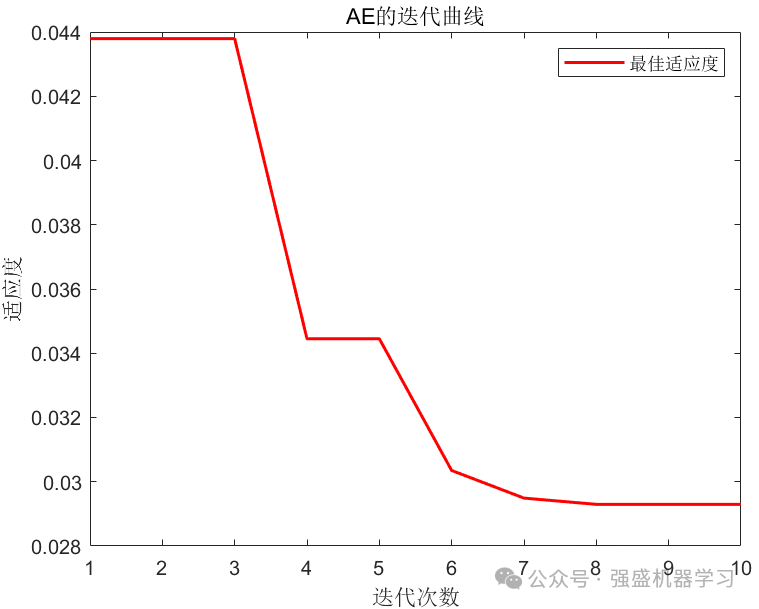
这里设置种群数量为6,优化算法最大迭代次数为10,展示一下运行效果。同时,设置置信区间分别为95%、90%、75%、50%、25%、10%、5%。当然,这里因为时间原因只设置了10次迭代次数,如果你时间充足或想要更好的结果,可以增大迭代次数。
区间概率预测效果图:
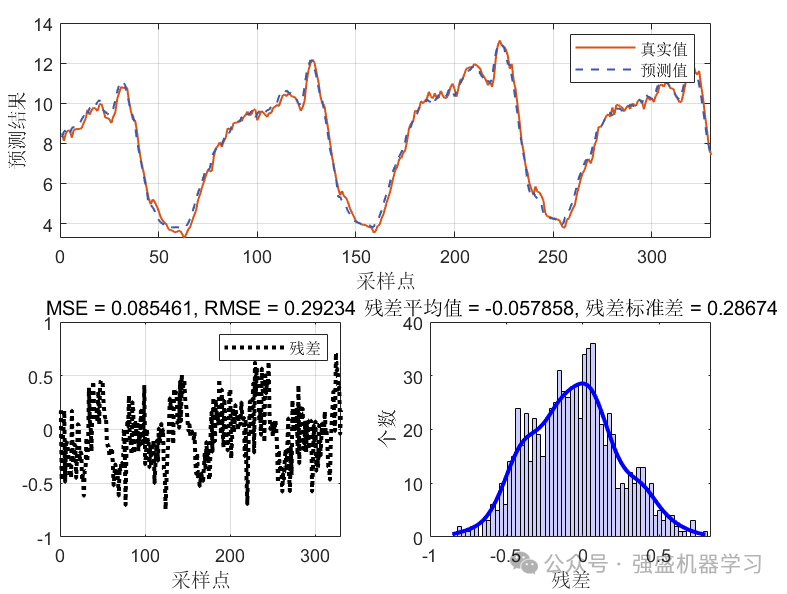
点预测效果图:
迭代曲线图:
核密度估计曲线图:
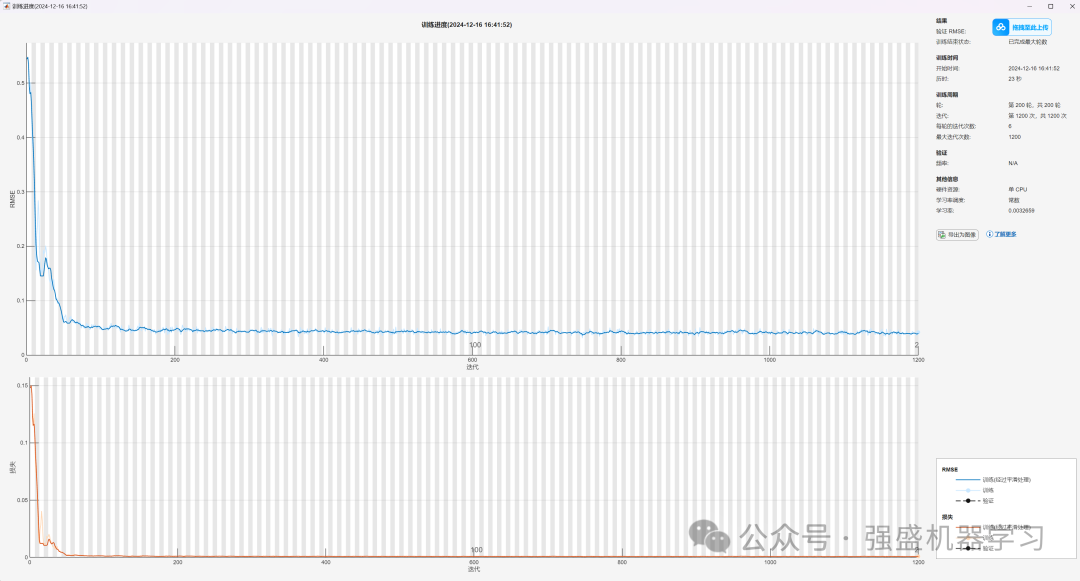
训练进度图:
网络结构图:
命令行窗口误差显示:
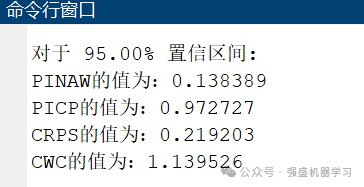

可以看到,在本数据集上,精度是非常高的,在95%置信区间上的PICP甚至达到了97%,R2也达到了0.98以上,与真实值基本吻合,非常适合用来作为创新点!
以上所有图片,作者都已精心整理过代码,都可以一键运行main直接出图,不像其他代码一样需要每个文件运行很多次!
适用平台:Matlab2023b及以上,没有的文件夹里已经免费提供安装包,直接下载即可!
全家桶代码目录
目前,全家桶在之前14个模型的基础上又增加了一个,共15个,并已推出了8篇推文进行讲解,之后还会推出更多更新颖的模型!
正如上文提到的,如果你想快速发paper,或者想要尝试到底哪个模型才最适合你的数据、精度最高,或者需要很多对比模型衬托你的模型的优越性,那么全家桶包含的这么多模型可以说完全符合你的需求!

购买后如果以后推出其他区间预测模型,直接免费下载,无需再次付费。
但如果你之后再买,一旦推出新模型,价格必然会上涨。因此,需要创新的小伙伴请尽早下手。
完整代码获取
1.已将本文算法加入区间预测全家桶中,点击下方小卡片,后台回复关键字,不区分大小写:
区间预测全家桶
2.如果实在只想要AE-Transformer-LSTM-ABKDE单品的同学,点击下方小卡片,后台回复关键字,不区分大小写:
ATLK

















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









