







Meta、Google、OpenAI、Anthropic 等在公开发布之前都投入了大量精力来审查其模型的输出,并设置安全使用的护栏。尽管他们付出了努力,但越狱仍然会发生,即使是最新版本也是如此。根据 [1],GPT4 很容易受到基于说服的攻击,事实上比旧版 ChatGPT 更容易受到攻击。
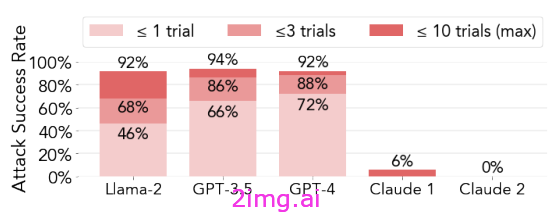
新的和更复杂的模型带来了新的和尚未发现的漏洞,这意味着安全训练协议需要跟上 LLM 不断增强的能力(特别提到 Claude,它似乎保持着强劲势头)。所以我试着看看最近的一些越狱方法,以及让 Claude 2 脱颖而出的安全训练过程的差异。
我的目标不是将每个人都变成 LLM 黑客(希望现在大多数问题都已经得到解决,这些论文中的结果在发表之前已经与感兴趣的各方共享),而是了解成功攻击背后的主要概念和当前安全培训程序的局限性。
LLM越狱方法
目前最常见、最系统的越狱手段可以分为以下几种:
1. 目标相冲突的快速工程
LLM 经过几轮训练,每轮都有不同的目标:基础训练侧重于下一个标记预测,微调侧重于任务(遵循指令、文本摘要、问答等),安
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2537
2537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









