






文章目录
Abstract
文章来源:Deep reinforcement learning for data-efficient weakly supervised business process anomaly detection
在线时间序列(文中为商业流程日志事件数据)异常检测任务中,由于小样本和标记成本的问题,收集大量带标记的异常数据非常困难,监督学习的方法在此领域适用性极差。因此,基于完全标记的正常数据和无监督学习方法和半监督学习方法长期以来占主导地位。然而,由于缺乏对真实异常的先验知识,这些方法的效果也并不完全理想。在本研究中,我们提出了一种基于深度弱监督强化学习的方法,通过利用有限的标记异常数据来识别时序数据中的异常。
该方法旨在利用少量标记的异常数据的同时,探索大量未标记的数据,以发现超出标记异常数据范围的新类别异常。我们创建了一个独特的奖励函数,该函数由未标记数据上训练的变分自编码器提供的监督信号与环境奖励提供的监督信号结合组成。为了进一步减少数据不足的问题,我们引入了一种采样方法,以有效探索未标记数据,并解决异常检测领域常见的数据不平衡问题, 该方法依赖于变分自编码器潜在空间中数据样本之间的相似性。此外,为了有效处理时序数据长期依赖问题,我们结合自注意力机制使用了长短期记忆网络(LSTM)来开发强化学习模型的代理Agent。最后在真实和合成数据集上使用多个场景对所提方法进行了测试。研究结果表明,所提方法通过有效利用少量可用的异常示例,优于其他方法。
Related work
-
过程挖掘(Process Mining):这一领域的常见做法是使用发现方法从事件日志中构建流程模型,然后通过一致性检查来发现异常轨迹。这种方法能够检测流程模型和流程执行之间的偏差。然而,这种方法存在一些缺点,例如无法使用事件属性,可能导致高误报率,以及依赖于干净数据集。
-
统计方法:统计异常检测方法通过构建一个代表正常行为的随机模型来工作。如果未见行为映射到这个随机模型的低概率区域,那么就会被认定为异常。这些方法通常依赖于对数据分布的精确假设,这在多维数据中可能很难实现。
-
机器学习方法:随着机器学习技术的发展,尤其是在深度学习领域,越来越多的研究开始关注如何利用这些技术来识别商业流程中的异常。这些方法可以根据标签的可用性分为监督学习、半监督学习和无监督学习。
-
监督学习方法:这些方法使用正常和异常轨迹的标签来训练一个二元或多类分类器。然而,获取标签数据困难。
-
无监督学习方法:这些方法不需要标签训练数据,可以检测多种异常,因为它们不限制于特定的异常类别。但这些方法由于缺乏对真实异常的先验知识,性能会受到影响。
-
半监督学习方法:这些方法试图利用有限的标记正常或异常轨迹来检测异常。但这些方法通常只适用于有限的标记异常分类,忽略了未标记数据中可能的异常。
-
文章的作者指出,尽管已有研究提出了多种方法,但在弱监督学习设置下,尤其是在商业流程异常检测领域,深度强化学习方法的应用还远远不够。现有的方法无法在弱监督学习中工作,无法检测新的异常类别,也无法处理不平衡数据问题。因此,作者提出了一种新的深度强化学习方法来解决这些问题。
Datasets
事件日志是业务流程建模学科中的关键数据结构。事件日志由多个轨迹组成,每个轨迹由在某个流程中发生的事件构成,每个事件都被分配一个活动名称。预处理将事件日志转换为数值表示,训练集进一步分为一个小的数据集D1和一个大的数据集D2,在D1中加入人工异常,形成有标签的异常数据集Dla,这些异常数据用于训练模型,使其能够识别已知的异常类别;在D2中也加入人工异常,但不保留它们的标签,以形成未标记的数据集Du,这个数据集用于模型的探索阶段,以发现新的异常类别。
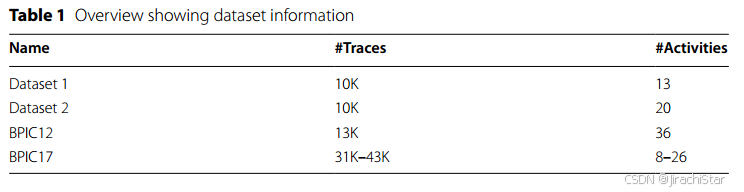
Deep reinforcement learning‑based anomaly detection framework
基于深度强化学习(DRL)的异常检测框架结合了强化学习(RL)的泛化能力和自学习特性,以下是该框架的具体公式和流程:
强化学习公式
-
目标函数:
代理的目标是学习一个最优策略 π ∗ \pi^* π∗,以最大化累积奖励:
π ∗ = argmax π E π { ∑ t = 0 ∞ γ t r t } \pi^*=\operatorname{argmax}_\pi \mathrm{E}^\pi\left\{\sum_{t=0}^{\infty} \gamma^t r_t\right\} π∗=argmaxπEπ{t=0∑∞γtrt}
其中, γ \gamma γ 是折扣因子, r t r_t rt 是在每个时间步 t t t 收到的奖励。 -
Q值函数:
Q值函数 Q π ( s , a ) Q^\pi(s, a) Qπ(s,a) 表示在状态 s s s 下采取动作 a a a 的期望回报:
Q π ( s , a ) = E π [ ∑ T = t ∞ γ t r t ∣ s t = s , a t = a ] Q^\pi(s, a)=\mathrm{E}^\pi\left[\sum_{T=t}^{\infty} \gamma^t r_t \mid s_t=s, a_t=a\right] Qπ(s,a)=Eπ[T=t∑∞γtrt∣st=s,at=a] -
策略推导:
根据Q值函数,可以推导出最优策略 π ( s ) \pi(s) π(s):
π ( s ) = argmax a Q π ( s , a ) \pi(s)=\operatorname{argmax}_a Q^\pi(s, a) π(s)=argmaxaQπ(s,a) -
Q学习算法:Q学习更新方程:
Q学习的核心是更新Q值函数,以下是一个离散状态空间的Q学习更新方程:
Q π ( s , a ) = Q π ( s , a ) + α ( r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ) Q^\pi(s, a)=Q^\pi(s, a)+\alpha\left(r+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right) Qπ(s,a)=Qπ(s,a)+α(r+γa′maxQ(s′,a′)−Q(s,a))
其中, α \alpha α 是学习率, r r r 是立即奖励, γ \gamma γ 是折扣因子, s ′ s^{\prime} s′ 是下一个状态, a ′ a^{\prime} a′ 是下一个动作。 -
DQN更新:
DQN使用神经网络来近似Q值函数,并通过以下方式更新:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma \max_{a'} Q(s', a') - Q(s, a)] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
其中, Q ( s , a ) Q(s, a) Q(s,a) 是由神经网络计算得到的Q值。 -
DDQN目标网络:
DDQN使用一个目标网络来稳定学习,目标网络的参数在训练过程中不会频繁更新:
Q target ( s ′ , a ′ ) = target_network ( s ′ , a ′ ) Q_{\text{target}}(s', a') = \text{target\_network}(s', a') Qtarget(s′,a′)=target_network(s′,a′)
其中, Q target Q_{\text{target}} Qtarget 是目标网络的Q值。 -
经验回放:经验回放存储:
代理的经验(状态-动作-奖励-下一个状态)被存储在经验回放记忆中:
ϵ = { ( s , a , r , s ′ ) } \epsilon = \{(s, a, r, s')\} ϵ={(s,a,r,s′)} -
经验回放:经验回放更新:
DQN使用经验回放来更新网络权重,通过随机选择经验样本进行更新。 -
VAE重建误差:
VAE通过重建误差来识别异常,重建误差越大,表示数据越异常,一般用向量之间的距离表示:
reconstruction_error = ∥ x ^ − x ∥ 2 \text{reconstruction\_error} = \| \hat{x} - x \|_2 reconstruction_error=∥x^−x∥2
其中, x ^ \hat{x} x^ 是重建的输入, x x x 是原始输入。 -
奖励函数:混合奖励:
代理的奖励由外部奖励和内部奖励组成:
r t = r e + r i r_t = r_e + r_i rt=re+ri
其中, r e r_e re 是外部奖励, r i r_i ri 是基于VAE的内部奖励。
通过这些公式和方法的结合,框架能够有效地在有限的有标签数据和大量的无标签数据之间进行平衡,从而提高异常检测的性能。
框架
这个框架是基于深度强化学习(DRL)的异常检测框架:
-
目标:
- 平衡利用小规模有标签数据集 D l a D_{l a} Dla 和探索大规模无标签数据集 D u D_u Du 中新的异常类别。
- 利用有标签的异常数据提高检测精度,同时不限制搜索异常类别的范围。
-
强化学习核心:
- 代理(Agent):负责根据当前状态和策略选择动作,并从环境中接收奖励。
- 环境(Environment):由数据采样函数 S S S 和外部奖励函数 X X X 组成,用于生成状态和奖励。
- 奖励(Reward):由外部奖励 r e r_e re 和内部奖励 r i r_i ri 组成,外部奖励基于代理的动作,内部奖励基于VAE对无标签数据的异常检测能力。
-
训练过程:
- 采样策略:代理从有标签数据集和无标签数据集交替采样数据,以训练和探索。
- 动作选择:代理根据当前状态和策略选择动作,并从环境中接收奖励。
- 奖励计算:代理从外部奖励函数和内部奖励函数接收奖励,并更新其策略。
-
强化学习方法:
- Q学习(Q-learning):一种基于值函数的强化学习方法,通过学习状态-动作值(Q值)来选择最优动作。
- 深度Q网络(DQN):结合了Q学习和深度神经网络(DNN)的强化学习方法,用于处理高维状态空间。
- 深度双Q网络(DDQN):通过引入目标Q网络来提高DQN的学习稳定性和性能。
- 经验回放(Experience Replay):将代理的经验存储在回放记忆中,以实现数据高效和减少更新方差。
-
VAE的应用:
- 使用VAE对无标签正常数据进行训练(可以认为训练数据都为正常数据的先验知识),以生成正常数据的潜在表示。
- 当输入序列与正常数据不同时,VAE无法以相同质量重建序列,从而计算异常分数。
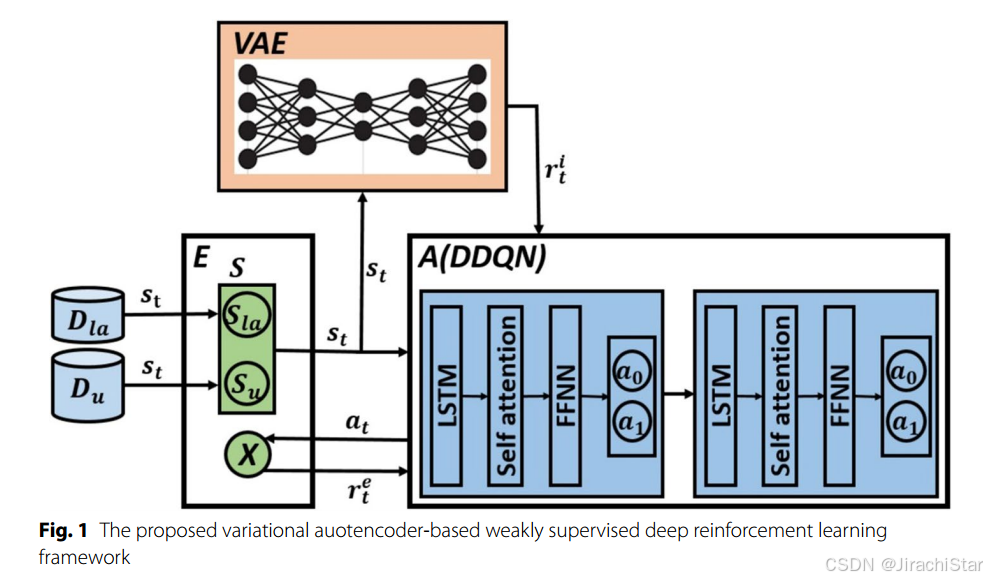
Agent
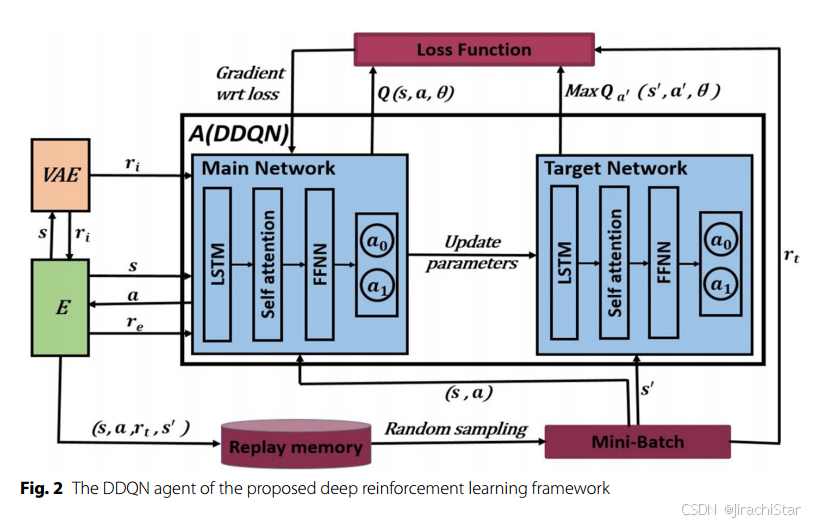
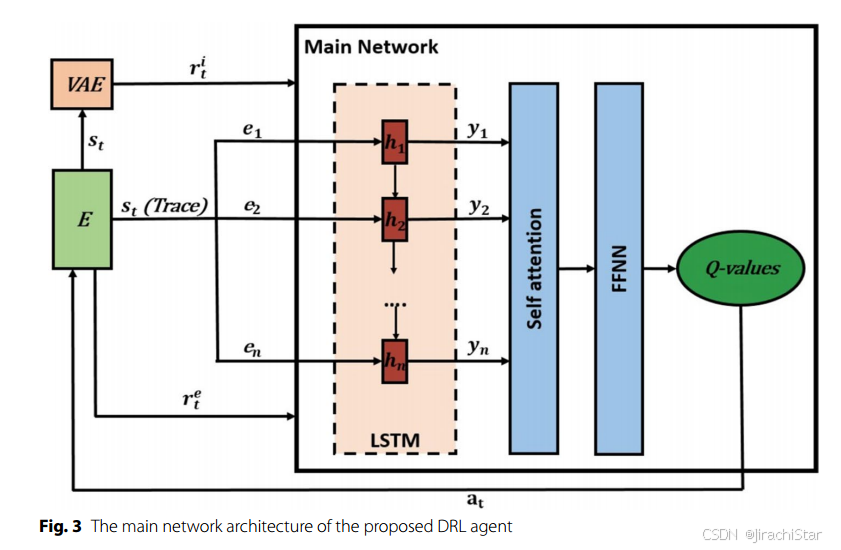
.
- Agent目标
代理的目标是学习一个最优策略,以最大化累积奖励。使用状态-动作值函数(Q 值函数)。在训练过程中,代理的目标是学习一个最优的动作值函数 Q ∗ ( s , a ) Q^*(s, a) Q∗(s,a),其定义为:
Q ∗ ( s , a ) = argmax π E [ r t + γ r t + 1 + γ 2 r t + 2 + … ∣ s t = s , a t = a , π ] Q^*(s, a) = \operatorname{argmax}_{\pi} \mathrm{E}\left[r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \ldots \mid s_t = s, a_t = a, \pi\right] Q∗(s,a)=argmaxπE[rt+γrt+1+γ2rt+2+…∣st=s,at=a,π]
这里, s s s 是当前状态, a a a 是当前动作, π \pi π 是行为策略, r t r_t rt 是在时间步 t t t 收到的奖励, γ \gamma γ 是衰减因子。
- DDQN 的选择
选择了双深度 Q 网络(DDQN)来学习最优的 Q 值函数 Q ( s , a ) Q(s, a) Q(s,a)。DDQN 利用深度神经网络作为函数逼近器,其参数为 θ \theta θ,并通过最小化损失函数来学习这些参数。损失函数定义为:
L i ( θ i ) = E s , a , r , s ′ ∼ U ( ε ) [ ( r + γ max a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ i ) ) 2 ] L_i(\theta_i) = \mathrm{E}_{s, a, r, s' \sim U(\varepsilon)}\left[\left(r + \gamma \max_{a'} Q\left(s', a'; \theta^{-}\right) - Q\left(s, a; \theta_i\right)\right)^2\right] Li(θi)=Es,a,r,s′∼U(ε)[(r+γa′maxQ(s′,a′;θ−)−Q(s,a;θi))2]
其中, ε \varepsilon ε 是代理的学习经验, θ i \theta_i θi 是主 Q 网络的参数, θ i − \theta_i^{-} θi− 是目标网络的参数。
- 梯度更新
主网络的梯度更新公式为:
∇ θ i L i ( θ i ) = E s , a , r , s ′ ∼ U ( ε ) [ ( r + γ max a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ i ) ) ∇ θ i Q ( s , a ; θ i ) ] \nabla_{\theta_i} L_i(\theta_i) = \mathrm{E}_{s, a, r, s' \sim U(\varepsilon)}\left[\left(r + \gamma \max_{a'} Q\left(s', a'; \theta^{-}\right) - Q\left(s, a; \theta_i\right)\right) \nabla_{\theta_i} Q\left(s, a; \theta_i\right)\right] ∇θiLi(θi)=Es,a,r,s′∼U(ε)[(r+γa′maxQ(s′,a′;θ−)−Q(s,a;θi))∇θiQ(s,a;θi)]
- 自注意力机制
为了增强 LSTM 网络的建模能力,结合了自注意力机制。自注意力机制能够在序列的不同位置之间建立依赖关系,从而更好地捕捉序列的全局信息。自注意力的计算公式为:
Score ( h i , h j ) = Softmax ( ( h i ) T h j d h ) \operatorname{Score}(h_i, h_j) = \operatorname{Softmax}\left(\frac{(h_i)^T h_j}{\sqrt{d_h}}\right) Score(hi,hj)=Softmax(dh(hi)Thj)
- 整体架构
DDQN 代理的主网络和目标网络均由 LSTM 网络、自注意力层和前馈神经网络(FFNN)组成。主网络接收一个事件序列
s
=
(
e
1
,
e
2
,
…
,
e
n
)
s = (e_1, e_2, \ldots, e_n)
s=(e1,e2,…,en) 作为输入,LSTM 生成隐藏向量序列
h
=
(
h
1
,
h
2
,
…
,
h
n
)
h = (h_1, h_2, \ldots, h_n)
h=(h1,h2,…,hn) 和输出
y
=
(
y
1
,
y
2
,
…
,
y
n
)
y = (y_1, y_2, \ldots, y_n)
y=(y1,y2,…,yn)。自注意力层将隐藏向量序列作为输入,生成上下文向量序列,最后通过 FFNN 预测 Q 值。
在深度强化学习中,前馈神经网络(FFNN)用于预测 Q 值的过程可以分为几个关键步骤。以下是对 FFNN 如何预测 Q 值的详细解释:
- FFNN
FFNN 的输入通常是经过 LSTM 和自注意力机制处理后的上下文向量。这些上下文向量包含了时间序列数据的特征,能够捕捉到序列中各个时间步之间的关系和依赖性。
FFNN 通常由多个全连接层(也称为线性层)组成,每一层都包含若干个神经元:
- 输入层:接收上下文向量。
- 隐藏层:一个或多个隐藏层,每层通过权重矩阵和偏置向量进行线性变换,并通过激活函数进行非线性变换。
- 输出层:输出与每个可能动作相关的 Q 值。
假设我们有一个上下文向量 C C C,FFNN 预测 Q 值的过程可以表示为以下步骤:
- 输入上下文向量:将上下文向量 C C C 作为输入传递给 FFNN。
- 线性变换:在每个隐藏层中,进行线性变换:
- 对于第
l
l
l 层,计算:
Z ( l ) = W ( l ) A ( l − 1 ) + b ( l ) Z^{(l)} = W^{(l)} A^{(l-1)} + b^{(l)} Z(l)=W(l)A(l−1)+b(l)
其中, W ( l ) W^{(l)} W(l) 是第 l l l 层的权重矩阵, A ( l − 1 ) A^{(l-1)} A(l−1) 是前一层的激活值, b ( l ) b^{(l)} b(l) 是偏置向量。
- 对于第
l
l
l 层,计算:
- 激活函数:应用激活函数:
A ( l ) = σ ( Z ( l ) ) A^{(l)} = \sigma(Z^{(l)}) A(l)=σ(Z(l))
其中, σ \sigma σ 是激活函数(如 ReLU)。 - 输出层:在最后一层,进行线性变换以输出 Q 值:
Q ( s , a ) = W ( L ) A ( L − 1 ) + b ( L ) Q(s, a) = W^{(L)} A^{(L-1)} + b^{(L)} Q(s,a)=W(L)A(L−1)+b(L)
这里, L L L 是网络的总层数, W ( L ) W^{(L)} W(L) 和 b ( L ) b^{(L)} b(L) 是输出层的权重和偏置。
最终,FFNN 输出的 Q 值表示在给定状态下采取每个可能动作的预期回报。代理会选择具有最高 Q 值的动作进行执行,从而实现策略的优化。
在训练过程中,FFNN 的权重和偏置会通过反向传播算法进行更新。损失函数通常定义为预测 Q 值与目标 Q 值之间的均方误差(MSE):
L = 1 N ∑ i = 1 N ( Q ( s i , a i ) − Q ^ ( s i , a i ) ) 2 L = \frac{1}{N} \sum_{i=1}^{N} \left(Q(s_i, a_i) - \hat{Q}(s_i, a_i)\right)^2 L=N1i=1∑N(Q(si,ai)−Q^(si,ai))2
其中, Q ^ ( s i , a i ) \hat{Q}(s_i, a_i) Q^(si,ai) 是目标 Q 值, N N N 是样本数量,通过最小化损失函数,FFNN 学习到更准确的 Q 值预测。
Enviorment
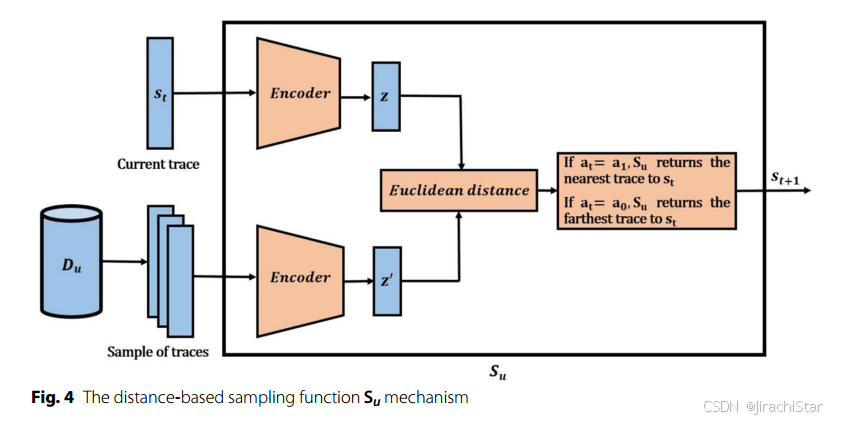
在这个环境 E E E 中,代理通过利用已标记的异常数据集 D l a D_{l a} Dla 和探索未标记的数据集 D u D_u Du 来进行学习。环境的组成包括一个轨迹采样函数 S S S 和一个外部奖励函数 X X X。
- 轨迹采样函数 S S S(轨迹就是指时序)
轨迹采样函数 S S S 由两个子函数组成:随机采样函数 S l a S_{l a} Sla 和基于距离的采样函数 S u S_u Su。这两个函数的设计旨在处理不平衡数据集的问题。
随机采样函数
S
l
a
S_{l a}
Sla:
从已标记的异常数据集
D
l
a
D_{l a}
Dla 中随机采样下一个轨迹
s
t
+
1
s_{t+1}
st+1,确保每个标记的异常轨迹都有相同的机会被利用。
基于距离的采样函数
S
u
S_u
Su:
从未标记的数据集
D
u
D_u
Du 中采样
s
t
+
1
s_{t+1}
st+1,根据当前轨迹
s
t
s_t
st 与
D
u
D_u
Du 中其他轨迹在变分自编码器(VAE)潜在空间中的欧几里得距离进行采样。具体定义如下:
S u ( s t + 1 ∣ s t , a t ; θ ) = { argmin d ( s t , s ; θ ) if a t = a 1 argmax d ( s t , s ; θ ) if a t = a 0 S_u\left(s_{t+1} \mid s_t, a_t ; \theta\right)=\left\{ \begin{array}{l} \operatorname{argmin} d\left(s_t, s ; \theta\right) \text{ if } a_t=a_1 \\ \operatorname{argmax} d\left(s_t, s ; \theta\right) \text{ if } a_t=a_0 \end{array} \right. Su(st+1∣st,at;θ)={argmind(st,s;θ) if at=a1argmaxd(st,s;θ) if at=a0
- 这里, s ∈ S s \in S s∈S, S S S 是从 D u D_u Du 中随机选择的轨迹子集, θ \theta θ 是编码器的参数, d d d 返回当前轨迹 s t s_t st 与 s s s 在 VAE 潜在空间中的欧几里得距离。
- 当代理选择异常动作 a 1 a_1 a1 时, S u S_u Su 返回与当前轨迹最近的轨迹;当选择正常动作 a 0 a_0 a0 时,返回最远的轨迹。这种设计允许代理在探索过程中更有效地发现潜在的异常轨迹。
- 外部奖励函数 X X X
外部奖励函数 X X X 为代理提供外部奖励 r e r_e re,其定义如下:
r e = x ( s , a ) = { 1 if a = a 1 , s ∈ D l a 0 if a = a 0 , s ∈ D u − 1 Otherwise r_e=x(s, a)= \begin{cases} 1 & \text{ if } a=a_1, s \in D_{l a} \\ 0 & \text{ if } a=a_0, s \in D_u \\ -1 & \text{ Otherwise } \end{cases} re=x(s,a)=⎩ ⎨ ⎧10−1 if a=a1,s∈Dla if a=a0,s∈Du Otherwise
- 该函数在代理正确标记已知异常轨迹为异常时给予正奖励(1),在代理将正常轨迹标记为异常时给予负奖励(-1),并在其他情况下给予零奖励。这种设计鼓励代理充分利用已标记的数据集 D l a D_{l a} Dla。
Award
内在奖励与外在奖励:
智能体不仅接收外在奖励 r e r_e re,还接收来自 VAE 的内在奖励 r i r_i ri 。内在奖励的目的是鼓励智能体对未标记数据集 D u D_u Du中潜在异常轨迹的无监督探索。VAE 的重构误差被用作内在奖励的指标,重构误差越大,表明该轨迹的异常性越高。
- VAE 的损失函数
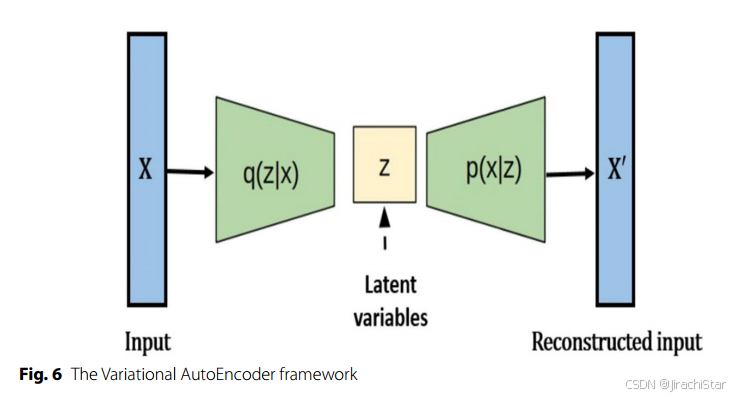
VAE 的损失函数由两个部分组成:
重构损失:第一项是对第 ( i ) 个数据点的重构损失或期望负对数似然性,表示为:
L i ( θ , φ ) = − E z ∼ q θ ( z ∣ x i ) [ log p φ ( x i ∣ z ) ] L_i(\theta, \varphi) = -\mathrm{E}_{z \sim q_\theta(z \mid x_i)}\left[\log p_\varphi(x_i \mid z)\right] Li(θ,φ)=−Ez∼qθ(z∣xi)[logpφ(xi∣z)]
q θ ( z ∣ x i ) q_\theta(z \mid x_i) qθ(z∣xi) 是编码器的分布, p φ ( x i ∣ z ) p_\varphi(x_i \mid z) pφ(xi∣z) 是解码器的分布。重构损失反映了模型对输入数据的重构能力,重构误差越大,损失越高。
- 重构误差
重构误差定义为原始输入 x x x 和重构输入 x ′ x' x′ 之间的差异,计算公式为:
∣ x − x ′ ∣ 2 \left|x - x'\right|^2 ∣x−x′∣2
重构误差通过 Min-Max 归一化方法被缩放到 [ 0 , 1 ] [0, 1] [0,1]的范围内,从而使得异常发生的概率随着内在奖励 r i r_i ri的增加而增加。
- 总奖励的计算
智能体为每个轨迹接收的总奖励 ( r_t ) 定义为外在奖励和内在奖励的和:
r t = r e + r i r_t = r_e + r_i rt=re+ri
这意味着智能体在探索过程中不仅考虑外部环境的反馈(外在奖励),还考虑自身对数据的理解和探索(内在奖励)。
结论
训练过程
输入输出描述如下:
输入:
- D = { D l α , D u } D=\left\{D_{l \alpha}, D_u\right\} D={Dlα,Du}
输出:
- Q ( s , a , θ ∗ ) \mathrm{Q}\left(\mathrm{s}, \mathrm{a}, \theta^*\right) Q(s,a,θ∗):算法的输出是Q函数,它预测了在状态s下采取动作a时的预期回报,其中 θ ∗ \theta^* θ∗ 是训练后的主网络权重。
训练过程:
-
初始化:
- 使用随机权重 θ \theta θ 初始化主网络,这个网络将用来预测Q值。
- 使用与主网络相同的权重 θ \theta θ 初始化目标网络,目标网络用于稳定学习过程。
- 初始化经验集E,大小为M,用于存储状态、动作、奖励和下一个状态的元组。
-
训练周期:
- 对于每个训练周期(共n_episodes个周期):
- 从 D u D_u Du 中随机选择一个初始状态 s 1 s_1 s1。
- 对于每个时间步(共n_steps步):
- 以epsilon的概率选择一个随机动作 a t a_t at(探索)otherwise 选择使Q值最大化的动作(利用)。
- 根据概率 p p p,环境返回下一个状态 s t + 1 s_{t+1} st+1,从 D l α D_{l \alpha} Dlα 随机选择 otherwise 基于自编码器的潜在空间从 D u D_u Du 选择。
- 计算外部奖励 x ( s t + 1 ) x(s_{t+1}) x(st+1) 和自编码器的内部奖励。
- 计算总奖励 r t = r t e + r t l r_t = r_t^e + r_t^l rt=rte+rtl。
- 将经验 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1) 存储到经验集E中。
- 对于每个训练周期(共n_episodes个周期):
-
经验回放:
- 从经验集E中随机采样一个minibatch的经验记录。
- 如果当前步骤是周期的终止步骤,则目标Q值 y = r y = r y=r otherwise y = r + γ max Q ∧ ( s t + 1 , a ′ , θ ′ ) y = r + \gamma \max \mathrm{Q}^{\wedge}(s_{t+1}, a', \theta') y=r+γmaxQ∧(st+1,a′,θ′)。
-
损失计算和网络更新:
- 使用均方误差计算损失: ( y − Q ( s t , a , θ ) ) 2 (y - \mathrm{Q}(s_t, a, \theta))^2 (y−Q(st,a,θ))2。
- 每N步更新一次主网络的权重参数 θ \theta θ。
- 每K步更新一次目标网络的权重参数 θ ′ \theta' θ′。

异常检测过程
输入:
- 测试数据集 T T T:包含一系列的状态 s i \mathrm{s}^i si,其中 i i i 是状态的索引。
- Q ( s , a , θ ∗ ) \mathrm{Q}\left(\mathrm{s}, \mathrm{a}, \theta^*\right) Q(s,a,θ∗):训练好的Q函数,它能够预测在给定状态下采取不同动作的预期回报,其中 θ ∗ \theta^* θ∗ 是训练后的主网络权重。
输出:
- 测试数据分类 A A A:包含对测试数据集中每个状态所采取的最佳动作的记录。
检测过程:
-
遍历测试数据集:
- 对于测试数据集
T
T
T 中的每个状态
s
i
\mathrm{s}^i
si(共
∣
T
∣
|T|
∣T∣ 个状态),执行以下操作:
- 使用训练好的Q函数 Q ( s i , a , θ ∗ ) \mathrm{Q}\left(\mathrm{s}^i, \mathrm{a}, \theta^*\right) Q(si,a,θ∗) 来评估在状态 s i \mathrm{s}^i si 下采取每个可能动作的预期回报。
- 选择使Q值最大化的动作 a i \mathrm{a}^i ai 作为当前状态 s i \mathrm{s}^i si 的最佳动作。
- 对于测试数据集
T
T
T 中的每个状态
s
i
\mathrm{s}^i
si(共
∣
T
∣
|T|
∣T∣ 个状态),执行以下操作:
-
记录最佳动作action:
- 对于每个状态,记录下计算出的最佳动作 a i \mathrm{a}^i ai。
-
返回检测结果:
- 完成所有状态的最佳动作选择后,返回检测结果 A A A。


















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









