







线性模型
0. 写在前面
今天对线性模型做一个总结,围绕以下两个点理一理思路:
判别函数 - 决策函数;
线性模型 - 线性模型各类拓展
具体沿着以下几个问题展开:
1. 生成方法与判别方法
2. 判别函数与决策函数
3. 线性模型
4. 广义的线性模型
5. 解决非线性的分类问题
6. 解决多分类的问题
1. 线性模型
再谈线性模型之前,首先懂得区分一个点:
线性回归用于解决回归问题,而 LR 和 SVM等线性模型用于解决分类问题。
线性模型 (Linear Model) 是机器学习中应用最广泛的模型, 指通过样本特征的线性组合来进行预测的模型.
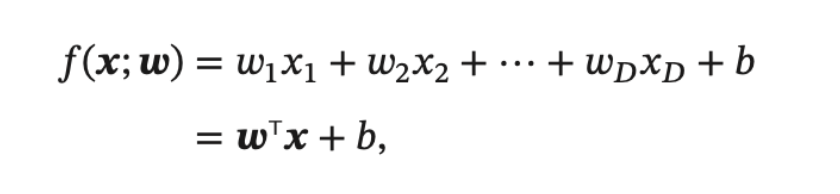
注: f(x;w) 或 f(x;θ) 表示的意思是 f 是关于 x 的一元函数,w或θ 只是参数(而不是自变量)
2. 用于回归和分类
实际上 ,可以对线性模型 f(x) 施加任何形式的变换,即引入各种形式的决策函数,来解决各种不同的问题。
例如:
f(x)为离散的值:线性多分类模型
f(x)为实数域上实值函数:线性回归模型
f(x)为对数:对数线性模式
f(x)进行sigmoid非线性变换:对数几率回归
2.1 回归问题
对于回归问题,利用 f(x;w) 就可以直接进行预测: y = f(x;w),即决策函数(Decision Function)就是它自己,即就是一个实数域上实值函数,不需要经过其他变换。
决策函数:
A decision function is a function which takes a dataset as input and gives a decision as output.
2.2 分类问题
对于分类问题,因为输出目标 y 是一些离散的标签,而 f(x;w)的值域为实值,所以需要引入非线性变换来预测输出目标: y = g( f(x;w) ),在这种情况下,决策函数即为 g(·),用于预测输出目标(给出最终结果),f(x:w)也称为判别函数 (Discriminant Function)
判别函数:
Discriminant function is a function used for finding a decision boundary.Discriminant function: a function of several variates used to assign items into one of two or more groups. The function for a particular set of items is obtained from measurements of the variates of items which belong to a known group.
区分决策函数(Decision Function)和判别函数(Discriminant Function):
决策函数:任何函数,只要是以数据集作为输入,最终给出一个 decision 作为结果,就是决策函数;
判别函数:可以简单的理解为用于分类的函数。在实际应用中,判别与分类常常混在一起。在机器学习领域,判别与分类被称为有监督的学习。
所以,不论如何,交给决策函数做最后的决策!
补:常见的非线性函数:
符号函数 Sign、Sigmoid 函数和 Relu函数,具体: 点击
将判别函数进行变换(引入非线性变换):
1. 若决策函数 g(·) 为符号函数(Sign Function)——用于二分类
符号函数:

比如,最简的神经网络模型——感知器:
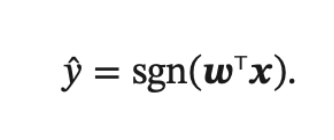
感知器是一种简单的两类线性分类模型, 其分类准则与上述公式相同。
以及最为常用的二分类模型——支持向量机(SVM):

2. 若决策函数 g(·) 为sigmoid函数——对数几率回归(Logistic回归)
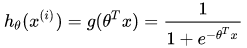
当然还有 Logistic 回归在多分类问题上的推广——Softmax 回归
(注:也可以用概率来进行解释,参考)
3. 几个问题
3.1 如何解决分类问题
上面已经说过了,通过引入非线性的决策函数g(·),使得线性模型拥有了对离散值的预测能力,使其能解决分类问题。同时,满足线性判别函数 f(x:w)= 0所组成的点组成的便是一个分割超平面,称为决策边界或决策平面。
比如,Logistic 回归的决策边界便是 Sigmoid 函数的形状,可以解决之前无法做到的分类。
3.2 如何解决多分类问题:三种解决
多分类 (Multi-class Classification) 问题是指分类的类别数大于 2. 多分类一般需要多个线性判别函数, 但设计这些判别函数有很多种方式,下面三种方式比较常见:
- “一对其余”(One VS Rest)
- ”一对一“(One VS One)
- argmax 方式:改进型的“一对其余”
或者更直白地分为两类:
- 间接法
- ”一对一“(One VS One)
任意两个样本之间训练一个分类模型,假设有k类,则需要k(k-1)/2个模型。对未知样本进行分类时,得票最多的类别即为未知样本的类别。libsvm使用这个方法。 - “一对其余”(One VS Rest)
训练时依次将某类化为类,将其他所有类别划分为另外一类,共需要训练k个模型。训练时具有最大分类函数值的类别是未知样本的类别。
- 直接法(一对其余的改进版)
直接修改目标函数,将多个分类面的参数求解合并到一个目标函数上,一次性进行求解。

“一对其余” 方式和 “一对一” 方式都存在一个缺陷: 特征空间中会存在一些难以确定类别的区域, 而 “argmax” 方式很好地解决了这个问题.
3.3 如何解决线性不可分问题
- 利用特殊核函数,比如使用核函数的非线性SVM模型
- 其它,比如扩展LR(Logistic Regression)算法,提出FM算法,点击参考
4. 线性模型的损失函数


参考:















 2421
2421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









