







 超级会员免费看
超级会员免费看
导学
- 基本概念:通过不断的喂养数据,让算法变的越来越聪明,就叫做机器学习

- 核心是算法
- 机器学习算法:特指通过一次次的数据积累经验,能够在既定任务处理上越来越聪明的计算流程
- 本质上是多次给机器反馈,最终做出我们想要的反应
- 算法参数:就是后面经常要调的东西,例如两个变量的权重
- 学习流程
- 学会算法:基础理论,基本框架
- 训练算法:评估方法,优化途径,竞赛案例
- 解决实际问题:在线评估,线上部署
- 算法岗
- 需要技术的沉淀,经历理性期和攀升期
- 目前已经过了泡沫阶段
- 不必自卑,不必标榜
- 经典机器学习模型,随着应用的深化,可解释性增强(实证)

- 推荐书籍
- 《终极算法》《暗知识》
- 《数据挖掘导论》《机器学习-西瓜书》,但是这些书出版较早,涉及的算法很广,不太适合当下情况
- 推荐:《集成学习—周志华》《机器学习实战—Aurelien》《阿里云天池大赛赛题解析》
- 环境准备
- Python基础(pycharm)
- 安装anaconda,更新pip/numpy/pandas/sk-learn
建模流程
- 用一个入门级的例子搭建
- 基本概念补充
- 经典统计分析方法与机器学习

- 经典统计分析需要掌握的基础数学知识较多,而在机器学习中流程比较简单
- 经典统计分析方法与机器学习
- 线性回归
- 概念

- 数据集——鸢尾花
- 读取数据
import pandas as pd iris = pd.read_csv('./datasets/iris.csv') print(iris) # sepal_length sepal_width petal_length petal_width species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa - 特征与标签,一般会把标签放在最后一列

- 连续与离散

- 读取数据
- 模型类型:分类 or 回归,看标签
- 也不是绝对的,边界模糊
- 比如年龄作为label,但是如果取值非常多且连续,可以作为回归预测问题

- 数据集—abalone.txt,预测鲍鱼年龄
- 每一列的含义(header)
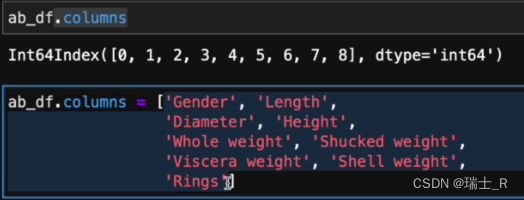
- 每一列的含义(header)
- 概念
- 继续线性回归(属于回归预测问题),准备数据,搭建模型(简单线性回归)
- 选取abalone数据集中的一小部分
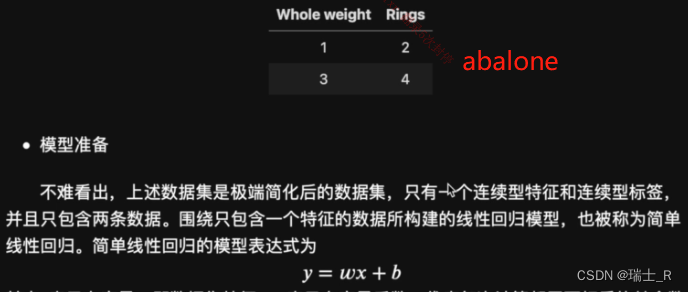
- 还有其他线性回归模型

- 模型训练:对参数进行有效调整(反馈 – 改动)
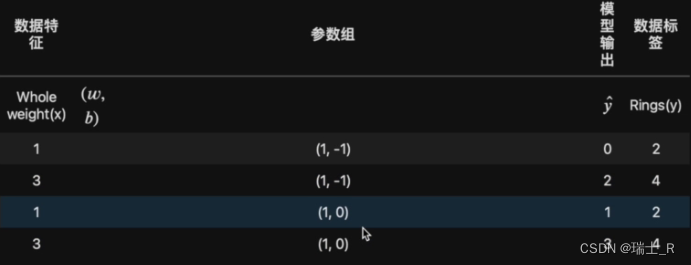
- 我们发现参数
(1,0)的结果相对更好,怎么把这个好坏有效的反馈给模型呢?需要用到模型评估指标和损失函数

- 第二组参数的SSE更小,说明更好;SSE是关于输出和标签的,也是比较通用的指标

- 怎么把这个结果传递给模型,就要用到Loss function,关于模型参数的
- 仍然使用SSE的方式,得到这个函数(方程),我们直接把参数(w,b)代进去

- 这里的SSE和SSELoss function计算过程是一样的,这并不是一定的,只是这个模型是这种情况
- 模型现在的目标就是:通过学习,调整参数,减小损失,得到最优参数;

- 如何求解损失函数?需要用到一些优化理论
- 绘出3D函数图像,我们可以发现这是一个凸函数(向下凸)
- 全域最小值明显存在,可以通过最小二乘法得到

- 偏导函数计算,再建立方程组求参数解

- 还有一些其他的模型评估指标,MSE可以避免因为数据累积造成的求和结果过大(最常用)

- 选取abalone数据集中的一小部分
- 建模流程总结
- 一般根据数据的情况会预设大致的模型结构,虽说基本模型就那些,但这一步选的好坏会直接影响后续问题的求解

- 损失函数包含所有参数,而且一定要能在一定程度上衡量模型性能,不同的构建会极大影响模型计算效率,最终目标也是针对这个Loss Function

- 最小二乘法其实适用面比较窄

- 有可能并没有最小值点,需要在周围确认相对最优的点

- 一般根据数据的情况会预设大致的模型结构,虽说基本模型就那些,但这一步选的好坏会直接影响后续问题的求解
矩阵运算
- 需要掌握的基础知识

- 使用numpy进行矩阵计算
- 安装:
pip install jupyter notebookpip install numpy scipy matplotlib - jupyter这个工具用起来比较方便,因为他的内核时IPython,所以文件名是
.ipynb
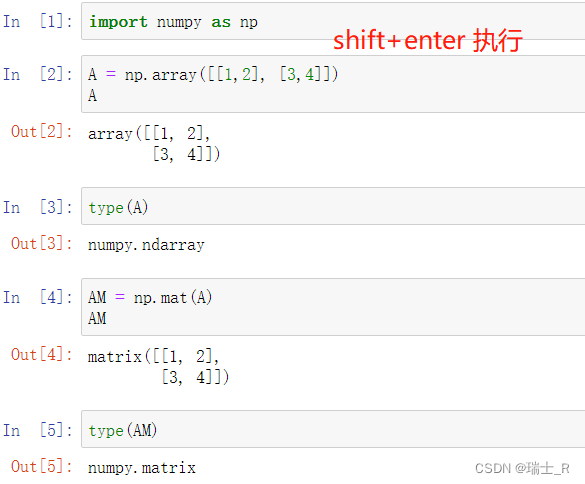
- 推荐使用array

- 新版特性
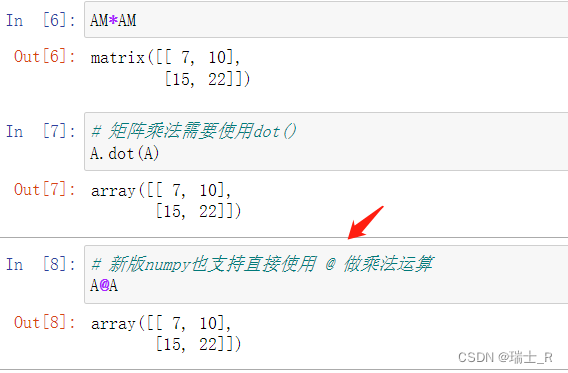
- 安装:
- 矩阵的常见操作
- 转置

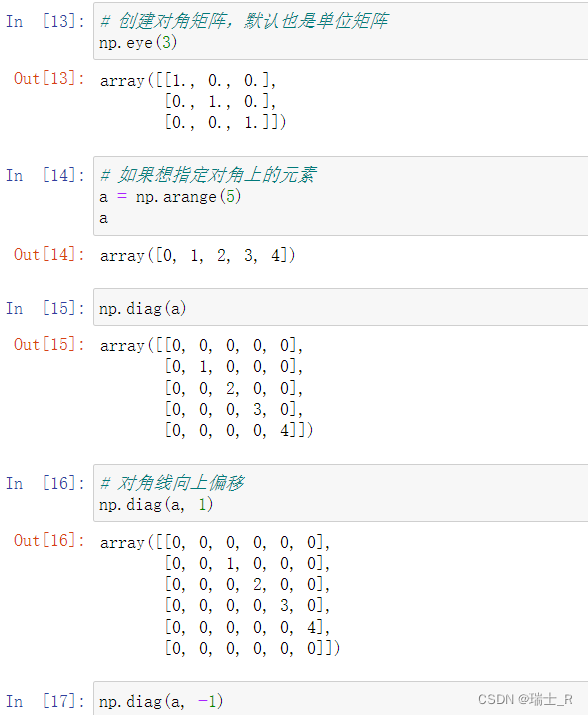
- 对角矩阵及偏移
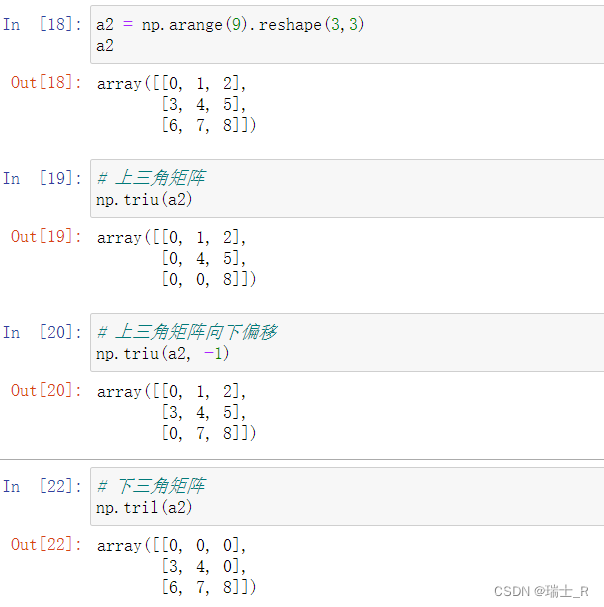
- 上下三角矩阵及偏移
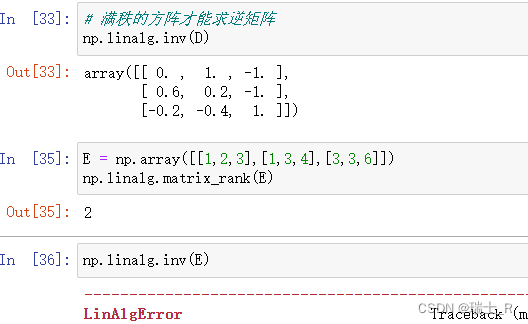
- 矩阵的逆:对于满秩的方阵,可求其逆矩阵;如果矩阵B与A相乘,能得到单位矩阵,则B称为A的逆
- 转置
基础运算
- 使用array表示矩阵,让矩阵带有了数组和矩阵的两重属性
- 一维数组在这里也叫向量,二维数组也叫矩阵,向量和矩阵的核心的区别在于乘法运算
- 线性代数运算将在后面讨论
- 对于向量和矩阵这种有结构的对象,这里对乘法计算做一下分类(上下看)

- 逐元素相乘:每个对应位置元素相乘,矩阵和向量都一样

- 点积(内积):相乘再相加,这个不太一样

- 矩阵乘法:这个只有矩阵才有,向量没有;因为是代数学意义上的,和结构有关系(双中括号),向量只有逐元素相乘和点积;只有一列的矩阵(列向量)和向量也是不一样的!

- 这里也可以用
A1.dot(A2)哦~
- 这里也可以用
- OK,以上就是向量和矩阵在乘法运算上的一些区别,掌握矩阵更重要;但他们都是在数组的基础上
- 注意这几个说法,不能混淆
代数运算
- 矩阵的代数运算
linalg是numpy中负责线性代数计算的模块,全称:linear algebra
- 矩阵的迹

- 矩阵的秩:不一定是方阵

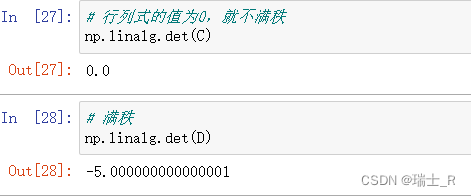
- 矩阵的行列式:必须是方阵,才可以算行列式;可以看做是矩阵的某个性质;可以通过此值看出方阵是否满秩

- 对于满秩的方阵,可以求其逆矩阵(inverse)
矩阵方程
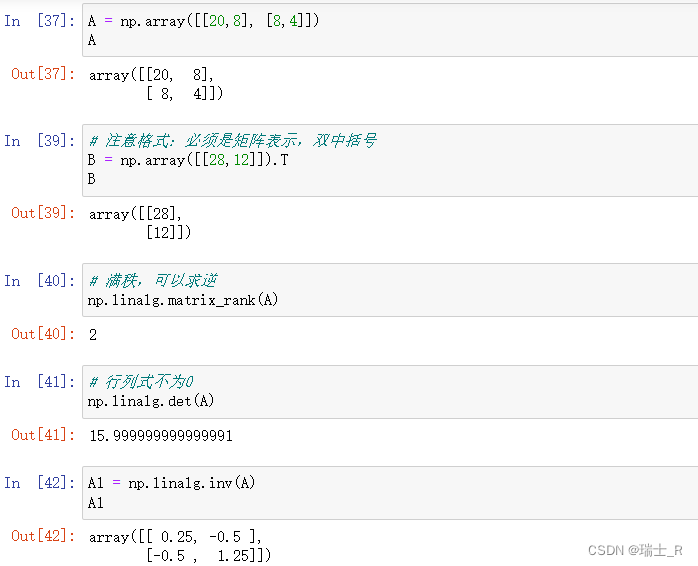
- 将之前优化损失函数的最小二乘法得到的方程组用矩阵表示并运算(没有T)

- 接下来,就可以两边同时乘A的逆矩阵求解X
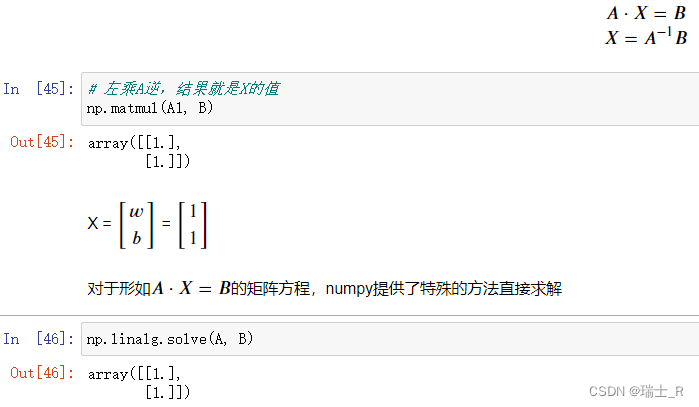
- 如何在jupyter写公式
矩阵求导
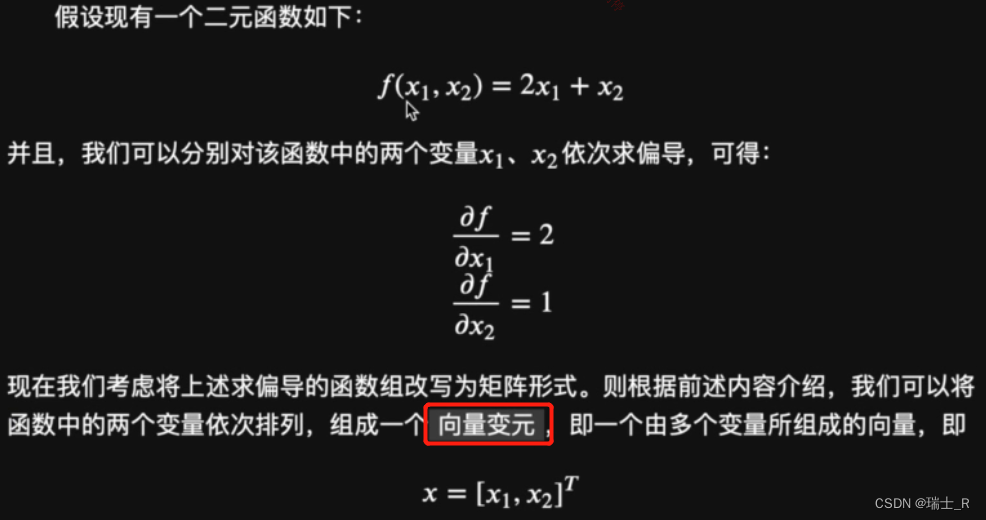
- 先看一下向量求导的推导过程
- 向量变元就是原函数里的元组成的向量
- 注意这个形式,f(x)对向量变元求导,类似对应元素相乘,结果还是向量(向量求导结果),位置对应;本质还是逐个变量求偏导

- 该结论可以推导至一般情况,注:这个推导,为了证明向量/矩阵求导是可行的,我们将求导式子转化为了只包含变量;不是什么公式

- 向量变元就是原函数里的元组成的向量
- 很多时候并不区分向量方程还是矩阵方程;所有变量为向量或矩阵的方程,一般统一称为矩阵方程(矩阵表达式)
- 总结上面的步骤,得到向量求导的定义法;梯度向量在后面会经常遇到

- 多元函数一定能够求得梯度向量;但梯度向量(向量求导结果)能否由一些已经定义的向量表示,则不一定(可能无解)
- 补充一些常见的求导公式
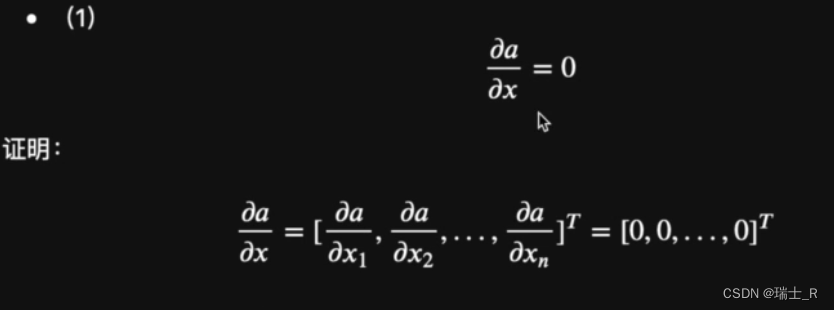






- 上面都是采用直接用定义计算的方式证明,后面也会学到一些证明相关的技巧
- 矩阵方程和矩阵函数

- 小结:
- 向量变元 x
- 梯度向量 A’
最小二乘法
- 以多元线性回归为例,还是用最小二乘法原理,求矩阵的解,得到系数值

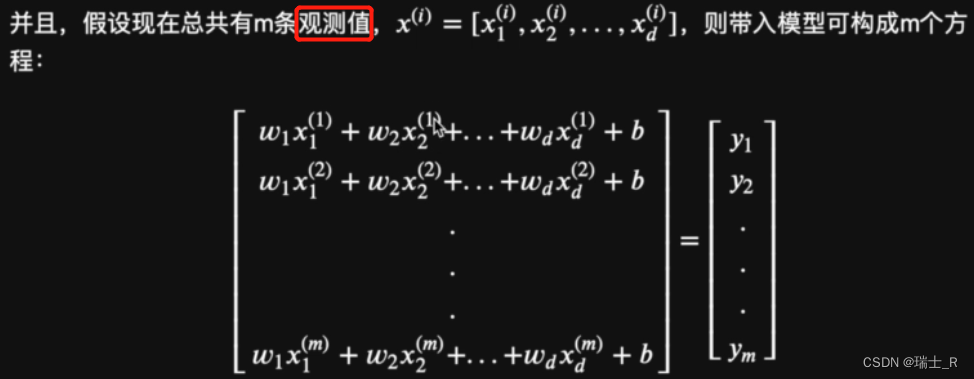

- So,特征矩阵也叫数据特征矩阵


- 构造关于
w
^
\hat{w}
w^ 的损失函数
- 如何在CSDN插入公式,因为也是Markdown,所以和jupyter类似,
$ $包裹即可 - 损失函数还是SSE,这里引入二范数
- 矩阵乘法中,相同矩阵的乘积(交叉乘积:转秩和自身的乘积)= 对应元素相乘再相加(点积),这里用矩阵简化向量的二范数计算
- 之所以是向量的二范数,是因为这个式子的结果是一个向量,虽然里面用了矩阵(列向量/行向量)

- 接下来先用最小二乘法求解矩阵,得到最优解;会用到前面证明了的公式

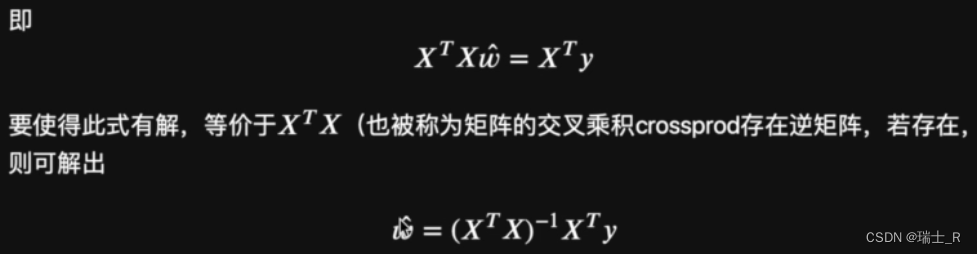
- 从这里可以看出,最小二乘法求解必须有一个强条件:特征矩阵的交叉乘积必须可逆
- 之前也是一样的思路,只不过是求偏导用方程求解,这里直接用矩阵,但还是以导数为0建立等式
- 用之前只有一个特征的简单线性回归试一下
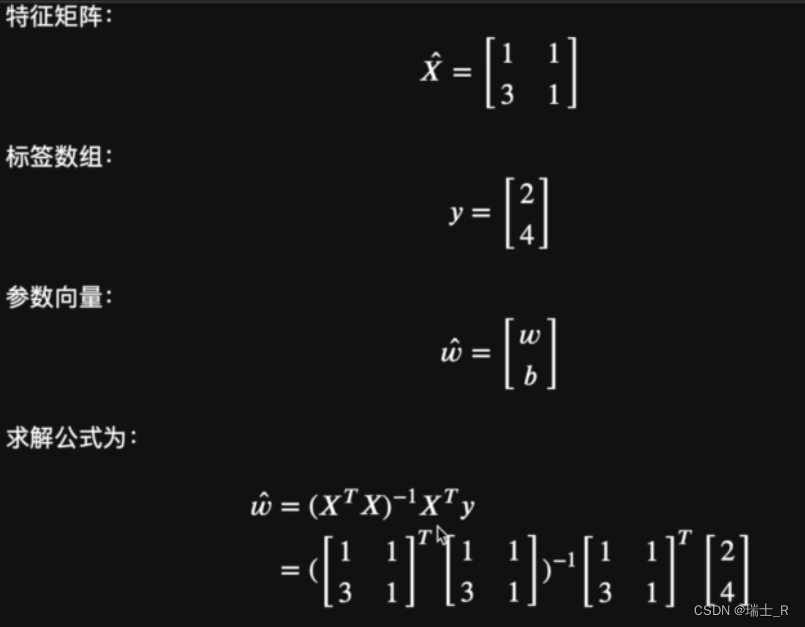
- 结果是肯定的,得到矩阵 [ 1 1 ] \begin{bmatrix} 1\\ 1\\ \end{bmatrix} [11]
- 因为这个结论很普适,很多问题都适用多元线性回归并使用最小二乘优化SSE,numpy也推出了直接计算的函数
lstsq;先不管奇异值分解


- 如何在CSDN插入公式,因为也是Markdown,所以和jupyter类似,
小结
- 本节了解了机器学习的基本概念和常规的建模流程
- 使用SSE作为损失函数,使用最小二乘法作为优化方法
- 从建立方程求解到使用矩阵运算,我们推导出了求多元线性回归的系数向量 w ^ \hat{w} w^ 的公式;结合numpy提供的函数比较方便的得到模型的最优解
- numpy使用数组作为基本的数据结构,一维数组可看做向量,二维数组看做矩阵,但矩阵中的列向量/行向量也需用二维数组表示,不能与向量混淆,最显著的差异体现在乘法运算,但在表示一般结果时,效果是等价的~
















 8471
8471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











