






 本文提出了一种用于多保真度建模的分层回归框架,该框架包括LF、DC、DR和HF四个模块,用于双保真建模。LF模块利用AdaBoost变换LF样本,DC模块连接LF信息,DR模块通过PCA降维,HF模块采用SVR等训练HF模型。此外,还介绍了一种递归方法将双保真模型扩展到多保真模型,通过迭代更新LF和MF样本响应,逐步提高模型准确性。
本文提出了一种用于多保真度建模的分层回归框架,该框架包括LF、DC、DR和HF四个模块,用于双保真建模。LF模块利用AdaBoost变换LF样本,DC模块连接LF信息,DR模块通过PCA降维,HF模块采用SVR等训练HF模型。此外,还介绍了一种递归方法将双保真模型扩展到多保真模型,通过迭代更新LF和MF样本响应,逐步提高模型准确性。
目录
一、概括
本文提出了一个用于多保真度建模的分层回归框架,该框架结合了用于双保真度建模的分层回归器和将得到的双保真模型扩展到多保真度情况的递归方法。
二、方法
本节首先介绍用于双保真建模的层次回归函数,然后提出了一种递归方法将得到的双保真模型扩展到多保真模型的情况。
2.1. 用于双保真建模的分层回归函数
符号设置如下:
,
。
目的:学习一个y,使得对于任意x,都有y(x)与相对应的高保真数据尽可能地近似。
为此,作者提出了一个分层回归器的双保真建模来解决这个问题。该回归器包含四个模块:低保真(LF)模块、数据拼接(DC)模块、降维(DR)模块和高保真(HF)模块(见图1)。这些模块的详细信息如下所示。
2.1.1. 低保真(LF)模块
为了从不同的角度获取输入的LF信息,LF模块将原始LF样本集转换为K个新的样本集
,然后根据每个转换后的样本集
学习LF模型
这里作者提出了一种确定性的样本分布变换方法——AdaBoost。AdaBoost提供了一个非常合理的方法来将原始LF样本集转换为新的,并且在每次迭代中更新的样本分布编码不同的LF信息。具体来说,原始样本集
以迭代的方式被转换成
,对于任意k,样本
的概率根据下式更新:
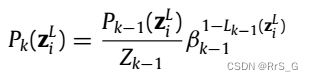
其中是第i个样本
的损失
的函数,
。
是一个归一化因子。另外,
通常用以下形式:
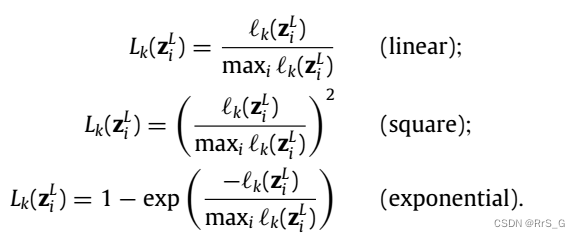
然后,利用变换后的样本集分别对LF模型
进行训练。本文将LF模型
设置为随机森林(RFs),也可以根据应用需求将其设置为其他类型的回归器。
2.1.2. 数据连接(DC)模块
DC模块连接输入x和其对应的LF模块输出g1(x), g2(x),…, gK (x)得到一个新向量:
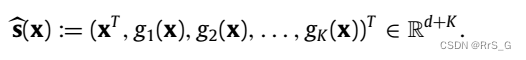
因此上式的维度一般是很高的,这导致HF模块在高保真数据很少的情况下很难被训练好,因此要先对其进行降维。
2.1.3. 降维(DR)模块
利用PCA降维:表示降维后的输入。
2.1.4. 高保真(HF)模块
利用产生的高保真样本训练HF模型,由于HF样本的大小有限,作者采用了对大样本容量需求相对较小的回归器,如SVR、Lasso和梯度boosting (GB)。
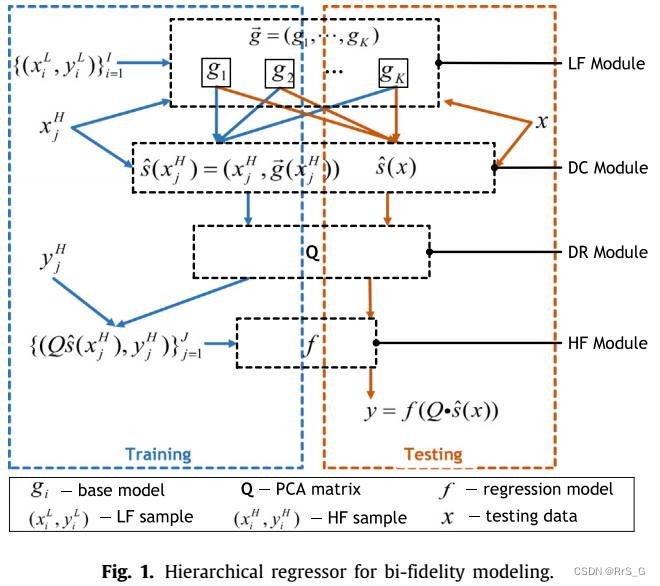
在算法1和2分别概述了用于双保真建模的分层回归器的训练和测试工作流程:

2.2. 多保真度建模的递归方法
递归方法利用得到的双保真模型来解决不少于三个保真级别的多重保真问题。在不丧失一般性的前提下,本文只考虑三保真度建模问题,保真度更高的建模问题也可以用类似的方法求解。
符号设置:

三保真建模的递归方法如下所述,从第t次迭代开始(t ≤ T):
step 1:使用算法1基于和
生成一个MF模型
,然后得到一个新的LF样本集
。也就是说,对于
中的每个
,其原始的LF响应
被替换为
.
step 2:通过再次使用算法1,基于得到HF模型
,然后更新原始MF样本集
为
。具体来说,对于在
的每个
,它的原始MF响应
被替换为
,其中
为控制MF响应变化的学习率。
step 3:增加迭代次数:t = t + 1。
当满足终端条件(即t = T)时,这个迭代过程将停止,最终的就是得到的HF模型(参见图2)。
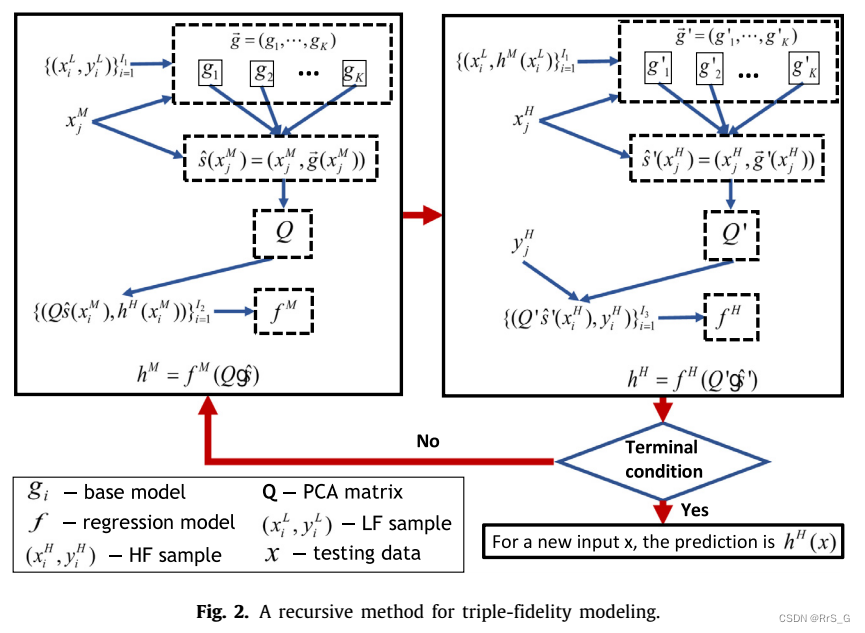
该方法利用每次迭代得到的HF(MF)模型迭代更新MF(LF)样本的响应。通过这种方式,HF信息以相对较低的保真度传播到样本中,从而提高样本质量,最终得到准确的HF模型。

















 263
263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









