







说明:跟着learnopengl的内容学习,不是纯翻译,只是自己整理记录。
强烈推荐原文,无论是内容还是排版。 原文链接
本文地址: http://blog.csdn.net/aganlengzi/article/details/50448453
坐标系统 Coordinate Systems
在上一次教程中,我们学习了怎样利用转换矩阵来帮助我们完成基于点的转换(缩放、平移和旋转)。前面已经说过,OpenGL只对在标准化设备坐标系中的点进行处理。标准化设备坐标系,也就是x,y和z轴上的坐标都在-1到1之间的一个立方体中。超出标准化设备坐标系范围内的坐标都是不能显示的。通常来说,我们都是在vertex shader中将我们的坐标转换到标准化坐标系中的坐标的。然后符合标准化坐标取值范围的坐标才会被传递给光栅化等阶段,最终将它们转换成我们屏幕上的像素点显示出来。
上面说的转换过程:坐标–>标准换坐标系–>屏幕坐标系的转换过程是一步一步完成的。其中,在最终将对象上的点转换到屏幕坐标系之前,我们需要将它们逐步转换到一些中间的坐标系。之所以要进行这样的转换,是因为在特定的坐标系中,相应的操作或者计算能够得到简化。在整个过程中,主要有5种不同的坐标系需要我们着重理解:
- 局部坐标系或者叫做对象坐标系
- 世界坐标系
- 视口坐标系
- 裁剪坐标系
- 屏幕坐标系
我们绘制对象上的点在最终被显示到屏幕上之前都会被转换到这些坐标系中。
你现在可能不知道它们具体是什么,不要紧,下面我们将采用一种便于理解的方式对它们进行解释。首先我们先看一张总体流程的图片: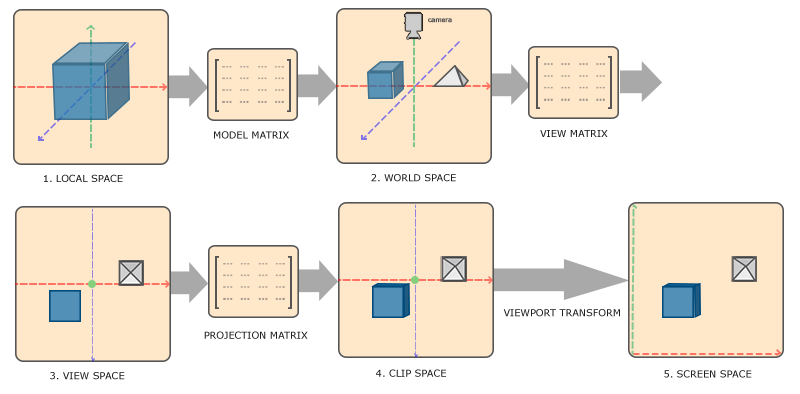
在不同的坐标系之间转换的方法是通过不同的转换矩阵进行作用(就像前一个教程中讲的那样),齐总最重要的是以下三个转换矩阵:模型矩阵,视口矩阵和投影矩阵(如上图中所示)。上面的整个过程可以描述为:顶点坐标首先是在局部坐标系中的,然后通过模型矩阵转换到世界坐标系中,谈后通过视口矩阵转换到视口坐标系中,谈后又通过投影矩阵作用后转换到裁剪坐标系统,最终转换到屏幕坐标系中。
-
局部坐标系是以方便描述对象本身为目的的坐标系,原点选择可能是对象的中心。完全是对象本身的表示。与其它外界因素全都没有关系。局部坐标系(实际叫做对象坐标系更好理解)是为了方便利用坐标描述对象本身。
-
世界坐标系就是将所有的对象都放到一个空间中进行描述,所有的对象有公共的原点。那么从世界坐标系中的每个对象来说,处在世界坐标系中应该以世界坐标系的原点为原点,那么相应的描述自身点的坐标值都会有相应的变化(主要是局部坐标系或者说是对象坐标系的原点与世界坐标系原点之间的相对位置)。世界坐标系是为了统一描述更多的对象。对象的相对位置。
-
视口坐标系主要为了将世界坐标系中的对象呈现给二维视口做准备。比如空间中的物体有其相对位置,但是我们看到的只可能是视觉范围内的物体和我们所处的位置和看的角度决定的一个范围。并不是其精确相对位置关系。
-
裁剪坐标系紧接着视口坐标系,因为在视口中我们已经知道我们所在的位置和角度能够看到什么,裁剪坐标系主要将我们看不到的内容从要渲染的画面中裁剪掉,裁剪坐标系将坐标归一化到标准化设备坐标系,即每个维度的坐标取值都是[-1,1]。
-
最终将裁剪坐标系中的坐标转换到实际的屏幕坐标系中。在这个转换的过程中,要依赖glViewport的参数设置。转换后的坐标被发送到光栅化器将它们转换成一个个片段。
通过上图和以上的解释,你可能能够有一点点理解整个过程了。之所以要进行这样的转换,主要是相关的操作在特定的坐标系中更好操作。另外采用分阶段的方法,这个过程也变得更加灵活。比如,当我们只是对我们绘制的对象进行修改的时候我们并不像考虑其它的对象。所以在局部坐标系中就很方便进行操作。
下面,我们将对每个坐标系进行更加细致地讨论。
局部坐标系(对象坐标系)
上面说过,局部坐标系是单独服务于一个对象的。比如,你想创建一个立方体,可能它的中心是原点坐标(0,0,0),你想创建一个球体,它的中心也是原点坐标(0,0,0)。这是两个完全不需要知道彼此的对象。之所以将它们的原点定在其中心,是为了创建的时候方便。当然,最终这两个对象显示的位置可能是不确定的。而这并不是我们建立模型应该考虑的问题,当我们将它们放到世界坐标系的时候再考虑它们的相对位置就好了嘛!
实际上,在前面的教程中,我们创建的矩形和三角形等等对象的坐标都是局部坐标系中的坐标,也就是局部坐标。
世界坐标系
在局部坐标系中我们创建的各个对象(如上面所说的三角形或者矩形)都有相同的坐标原点,当它们都显示在屏幕上的时候会是什么样的情况呢?是的,它们都会重叠堆放到一起。这样肯定不是我们需要的结果。世界坐标系中的坐标就是来指定其中不同对象之间的相对位置的。它通过模型矩阵来完成这项工作。
模型矩阵是一个转换矩阵,它就是我们上次教程中讲到的不同的转换(缩放、平移和旋转)的组合,它的作用是将不同的对象放到它们应该在的位置上。
视口坐标系
视口坐标系就是将空间中的对象转换成你观察范围内所见的情形。它以设定的观察点和观察范围(角度)以及与具体对象的位置来决定可见的场景。这主要是通过视口矩阵来完成的,其中也主要涉及的是平移和旋转操作。在下一次教程中将会对视口矩阵做进一步说明。
实际上,视口坐标系又叫做照相机坐标系或者人眼坐标系。完成的功能就是模仿人眼的功能,将世界坐标系中的对象转换到人眼的视觉范围。
裁剪坐标系
在顶点处理程序完成时,OpenGL都会将不在能够显示范围内的坐标丢弃掉(因为即使做了渲染也不会显示出来)。这也正是裁剪坐标系名称的由来。剩下的坐标最终都是要转换成在屏幕上要显示的像素的片段。
OpenGL处理标准化设备坐标系,但是坐标值都在[-1,1]的三维空间对我们来说并不是太直观。实际上我们可以自己指定我们的坐标范围,只要在OpenGL处理的时候将其转换成[-1,1]范围内就好了。
为了将顶点坐标从视口转换到裁剪坐标系,我们定义了一个投影矩阵将指定坐标的范围,比如说在每个维度上都是从-1000到1000,内的坐标转换到标准化设备坐标系规定的范围(-1,1),所有在指定范围外的坐标都将会被裁剪掉。比如说在我们指定的范围内,坐标(1250,500,750)都不会被显式出来,因为x坐标超出了设定的坐标值范围。
需要注意的是,如果对象的一部分在裁剪域中而另一部分不在裁剪域中,那么OpenGL就会将这个对象,比如说三角形,重新划分成更小的三角形来保证将外部的裁剪而将内部的保留。
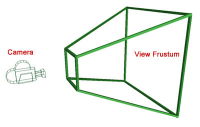
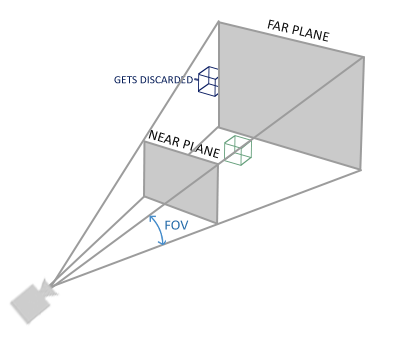
投影矩阵作用产生的矩形体叫做视口截头椎体,如下图所示。所有在这个截头椎体中的坐标最终都会显示在用户屏幕上。所有将指定范围内的坐标转换为标准化设备坐标系范围内二维平面坐标值的操作叫做投影。而投影矩阵就是完成这个功能的。
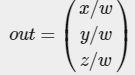
当所有的顶点都被转换到裁剪坐标系,一种叫做透视除法点的操作就会被执行。也就是用前面讲过的齐次坐标w来对位置向量的x,y和z分量进行操作。这个操作实际上是将四维的裁剪坐标系转换成三维的标准化设备坐标系,而且这个步骤是在每个顶点处理程序结束时自动完成的(不需要我们做任何操作)。
在这个阶段之后,生成的坐标才会被映射到屏幕坐标系中(需要用到glViewport函数的参数设置)并且生成最后的片段(还记得片段是什么吗?就是要生成显示在屏幕上的一个像素点的所有相关数据)。
投影矩阵实际上有两种投影方式,一种是正交投影,另一种是透视投影,我们可以选择两种中的任意一种来完成我们的投影操作(将视口坐标转换成裁剪坐标)。以下将对这两种投影方式进行介绍:
正交投影
正交投影矩阵产生的截头椎体实际上是一个类似于立方体的截头椎体,即其前面和后面是相同大小的,它的同方向的线时平行的,如下图所示。同样的,超出这个立方体的所有的坐标都会被裁剪掉。为了定义一个正交裁剪矩阵,我们需要指定这个截头椎体的宽度、高度和长度。实际上就是指定了可见的三维空间范围。
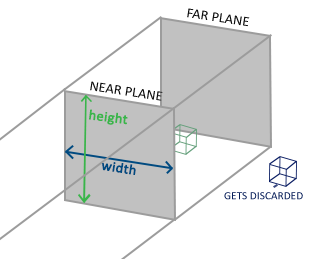
在正交矩阵中,因为我们并不需要做透视除法,所以w的值是无关紧要的。如果w的值是1.0,那么转换后的坐标和转换前的坐标值实际上是一致的。
我们可以通过GLM内置的函数glm::ortho来创建一个正交矩阵:
glm::ortho(0.0f, 800.0f, 0.0f, 600.0f, 0.1f, 100.0f);前两个参数指定了这个椎体的左边和右边的坐标;第三个和第四个参数指定了椎体的上表面和下表面;最后两个参数指定了前面(near)和后面(far)的位置。这个正交矩阵将所有在指定范围内的对象的坐标全部转换成标准化设备坐标系中的坐标值。
实际上正交投影产生的效果是失真的,因为它直接将在椎体内的坐标值都投影到屏幕上。对于人的视觉来说,为了得到更逼真的效果,需要考虑透视。
透视投影
在实际生活中,我们应该有这样的体会:离我们远的物体看上去更小,离我们近的物体看上去更大。实际上这种奇怪的效果就是透视。以下这张图实际上很好体现了透视的效果:一张火车道的延伸图:

如你所见,因为透视,火车道原本平行的线在远处好像交汇了。透视投影想要模仿的功能就是这样。像正交投影以下,透视投影也是规定了一个椎体,但是它还对齐次坐标w进行操作:离观察点越远的点坐标中,w值越大。当坐标值转换到裁剪坐标系中的时候,它们的坐标值实际上是在[-w,w]之间的,所有不在这个范围内的坐标都会被裁剪掉。当然为了将最终的坐标值都转换成标准化设备坐标系中的坐标值,在最后生成OpenGL能够处理的坐标值的时候,所有的坐标都要做如下的处理:
顶点的每一个分量都被其次坐标w除。因为w的值是越远越大,所以造成的结果是越远的对象的坐标值就越小。这也是齐次坐标w比较重要的一个原因,因为它帮助我们处理透视投影。所有转换和计算的结果得到的是标准化设备坐标系中的坐标(和正交投影一样)。
投影矩阵可以利用GLM通过以下方式生成:
glm::mat4 proj = glm::perspective(45.0f, (float)width/(float)height, 0.1f, 100.0f);它的样子是这样的:
函数glm::perspective的作用还是创建一个锥体,所有不在其中的坐标都会被裁剪掉而不会在屏幕上显示。第一个参数指定了视角,为了得到逼真的效果,这个值通常被设置为45.0f。第二个参数设定了纵横比,它是宽度和高度的比值。第三个和第四个参数设置了近处距离和远处距离为0.1f和100.0f。这样就指定了可见空间内的所有坐标,这些坐标将会被处理和渲染。
当近处距离值设置太高的话,比如说10.0f,OpenGL就会将所有在0.0f到10.0f范围内的坐标都裁剪掉,它们可能是一个对象的表面,表面被裁剪掉了,我们就可能看到对象的内部构造了。
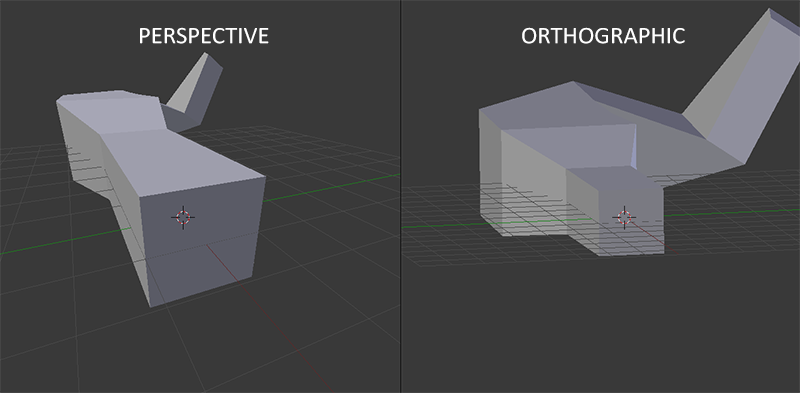
当使用正交投影的时候,每个顶点的坐标都会被直接映射到裁剪坐标系,不会有任何的透视除法操作(实际上是进行了透视除法,只是w值并没有备操作,所以并不会产生透视的效果)。因为没有透视效果,远处的对象实际上也不会显得比较小,和近处的对象一样按照原来的大小进行显示。所以就会造成失真的现象。因此,正交投影是不适合用在三维对象上的,而用在二维平面图形的生成或者一些结构或者工程应用中,因为在其中,我们不想让透视效果破坏我们的图形的形状。但是在三维图形、模型或者场景中,我们通常都是要使用透视投影来增加其真实效果的。两者之间的对比可以看一下下面这两张图:
把所有的过程串联起来!
我们为上述提到的每个过程都定义了一个转换矩阵:模型矩阵、视口矩阵和投影矩阵。顶点坐标转换成裁剪坐标的过程如下所示:
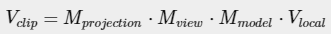
需要注意的是上面的顺序不能改变,同时需要注意的是对向量的操作是从右向左来看的。生成的顶点将会被传递到顶点处理程序中的gl_Position,OpenGL将会自动进行透视除法和裁剪操作。
接下来呢?
顶点处理程序的输出应该是在裁剪坐标系中的坐标,这正是我们上面做的事情。然后OpenGL对裁剪坐标进行透视除法操作,把这些坐标转换成标准化设备坐标系中的坐标。再然后,OpenGL利用glViewport函数的参数来将标准化设备坐标系中的坐标映射到屏幕坐标系中。在屏幕坐标系中,每一个坐标对应的是屏幕中的一个像素点(比如说你的屏幕分辨率是800x600)。这个过程就叫做视口转换。
3D!3D!
到目前为止,我们知道了怎样将3D坐标转换成2D坐标。我们可以使用3D而不是平面的2D来绘制和展示我们创建的图形了!
首先我们需要做的是创建一个模型矩阵,模型矩阵包含缩放和/或旋转等操作以完成我们想要对我们创建的对象进行的操作,以使得它们在世界坐标系中的合适位置。让我们先来把我们的平面绕着x轴旋转一下使它看上去像是在平铺在地上的,那么模型矩阵应该是向下面这个样子的:
glm::mat4 model;
model = glm::rotate(model, -55.0f, glm::vec3(1.0f, 0.0f, 0.0f)); 接下来我们需要创建一个视口矩阵。我们想要把我们的平面稍微向后移动一下,以便于我们能够在视口中看到这个看上去像平铺在地面上的平面。我们可以采用下面的两种方式来进行移动:
- 把摄像机向后移就相当于把整个场景向前移。
这就是一个视口矩阵的任务,将整个场景而不是将摄像机进行移动。
因为我们想要向后移动,而OpenGL是一个右手系统,所以我们应该把所有的物体向z轴正方向移动,这样产生的效果是:我们正在把物体向后移动。
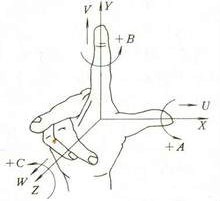
右手系统
根据约定,OpenGL是一个右手系统。也就是说x轴正方向是右,y轴正方向是上,z轴正方向是后。可以伸出右手,想象右手的中心是原点,下图这样,拇指,食指和中指分别制定的就是坐标轴方向。
我们将在下一次教程中详细介绍怎样在屏幕上移动对象,在本次教程中,视口矩阵像下面设置的样子:
glm::mat4 view;
// Note that we're translating the scene in the reverse direction of where we want to move
view = glm::translate(view, glm::vec3(0.0f, 0.0f, -3.0f)); 最后,我们还需要定义一个投影矩阵。我们使用的投影方式是透视投影,我们的投影矩阵定义如下:
glm::mat4 projection;
projection = glm::perspective(45.0f, screenWidth / screenHeight, 0.1f, 100.0f);像之前一样,在利用glm时,传递参数的时候可能会遇到角度和弧度使用约定不一致的情况。比如说45度角度如果转换成弧度是1/4 PI。
好的,现在我们已经创建了各个转换矩阵。现在我们应该把它们传递给我们的处理程序(shader)。首先让我们在vertex shader中声明uniform类型的这些转换矩阵。并且按照上面所示的矩阵和向量相乘的顺序完成相应的计算:
#version 330 core
layout (location = 0) in vec3 position;
...
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main()
{
// Note that we read the multiplication from right to left
gl_Position = projection * view * model * vec4(position, 1.0f);
...
}当然在vertex中只是声明了相关的矩阵,为了使用我们真正创建的矩阵,我们还需要将这些矩阵值传递到vertex shader中:
GLint modelLoc = glGetUniformLocation(ourShader.Program, "model"));
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model));
... // Same for View Matrix and Projection Matrix经过上面的所有的模型、视图和投影矩阵的转换后,我们最终的对象应该是:
- 向地板平面倾斜的
- 稍微离我们应该远一点
- 以透视方式呈现在我们面前(更远处显得更小)
让我们来看一下效果吧:
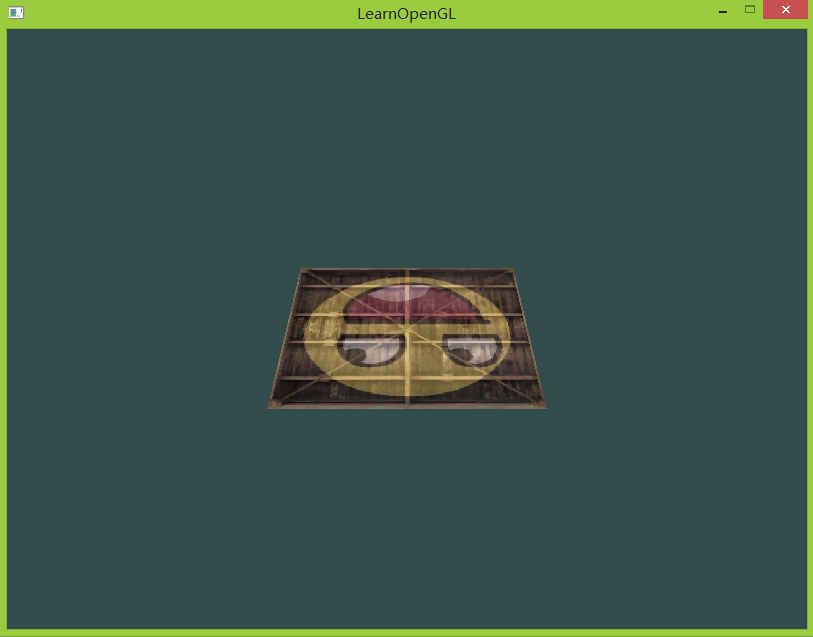
基本上是我们想象的样子吧,只是这里因为没有做将OpenGL坐标轴和屏幕坐标轴相统一,还记得怎么统一吧^_^,所以头像感觉是倒过来的。源码main.cpp和vertex shader。源码中需要注意的是上面提到的glm关于角度和弧度坐标的规定,我的版本中是以弧度为准的。
更加3D一点!
到目前为止,我们还只是对二维的平面进行操作,虽然我们的操作是在三维空间中的。下面就然我们更冒险意一点!让我们从二维平面中跳出来,跳到真正的三维空间中!让我们来创建一个三维的立方体。为了创建一个立方体,我们需要总共36个点(6个面 * 2个三角形 * 3个顶点),这是一个难题啊,不过原教程中给我们提供了已经写好的坐标数组。有了坐标实际上就有了立方体的骨架,这样我们就可以专心于创建3D立方体的其它方面了。
为了更加有趣,我们还要让这个立方体旋转!这个旋转矩阵应该不陌生了。
model = glm::rotate(model, (GLfloat)glfwGetTime() * 50.0f, glm::vec3(0.5f, 1.0f, 0.0f)); 因为已经写好的数组指定了36个顶点的坐标(包括重复的)所以我们将采用glDrawArray来渲染这些点,而不是glDrawElement。
glDrawArrays(GL_TRIANGLES, 0, 36);利用上面的顶点数组和旋转矩阵以及绘制函数,当然还需要将OpenGL解读数据的方式进行重新的格式指定。我们会得到下面的样子的效果:

看上去好像是一个立方体但又好像不是,很奇怪的一个东西。这个“立方体”的某些面会覆盖其它的面。这种现象的原因是,OpenGL在绘制三角形的时候是一个接一个绘制的,虽然前面已经绘制了三角形,在轮到某个三角形绘制的时候还是会在那个地方再绘制一次,所以就会有重复绘制进而覆盖的现象。
所以问题已经知道了——重复绘制造成的覆盖。那么怎么解决这个问题呢?幸运的是。OpenGL的Z-buffer(深度缓存)为我们提供了很好的解决方法。它记录了绘制的深度信息并且允许OpenGL根据这些深度信息来决定是否在一个像素上进行绘制(深度检测)。所以,我们可以启用OpenGL的深度缓存来进行深度检测,在不该绘制的时候不要绘制就好了。
深度缓存 Z-buffer
OpenGL利用Z-buffer保存了所有的深度信息,也叫作深度缓存。GLFW自动创建了这么一个缓存(就像颜色缓存保存要输出图像的颜色值一样)。深度缓存保存了每个片段的深度信息。每当轮到一个片段进行处理的时候,OpenGL就会比较它的深度值。如果当前的片段是在其他片段的后面,那么它就会被丢弃(不进行渲染,因为渲染了也不会显示出来),否则就会将当前的片段覆盖掉。这个过程就叫做深度检测,如果启用的话,它由OpenGL自动完成。
为了使OpenGL能够运行深度检测,我们应首先启用深度检测,因为默认情况下它是不进行深度检测的。我们利用状态设置函数glEnable来使能OpenGL的深度检测,这个状态的宏名称是GL_DEPTH_TEST:
glEnable(GL_DEPTH_TEST); 因为我们使用了深度缓存,所以我们需要在每次绘制之前都应该清空深度缓存,否则深度缓存中还保留着可能过时的深度信息。像清空颜色缓存一样,我们利用clear函数来清空深度缓存,通过下面方式完成:
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);让我们来测试一下我们的程序并且检查OpenGL是否已经启用了深度检测(如果启用了深度检测,我们应该能够看到一个正常的立方体在旋转了):
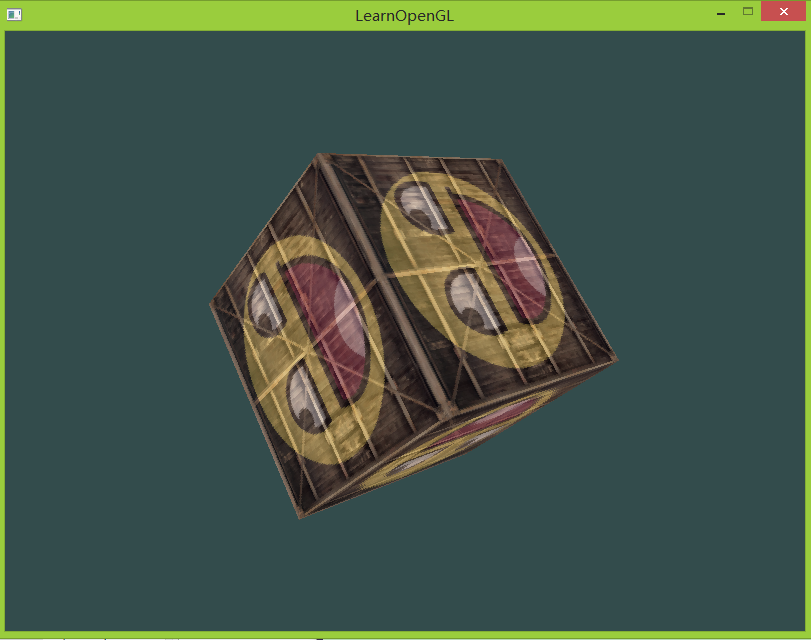
就是这样,能够得到一个正常的立方体!源码main.cpp。(但是好像立方体旋转越来越快好像)。
更多立方体!
加入我们想要在屏幕上显示10个立方体。每一个立方体都是我们上面已经创建出来的样子,但是在屏幕中的位置不同,而且有不同的旋转角度,应该怎么做呢?每一个立方体的样子都已经固定了,就是我们上面创建出来的样子。我们实际只需要改变这些立方体在世界坐标系中的排布和数量就好了!让我们来完成它。
首先,我们来为每一个立方体定义一个变换向量,来指定其在世界坐标系中的位置。因为我们要显示10个立方体,我们将定义一个包含10个位置坐标向量的数组:
glm::vec3 cubePositions[] = {
glm::vec3( 0.0f, 0.0f, 0.0f),
glm::vec3( 2.0f, 5.0f, -15.0f),
glm::vec3(-1.5f, -2.2f, -2.5f),
glm::vec3(-3.8f, -2.0f, -12.3f),
glm::vec3( 2.4f, -0.4f, -3.5f),
glm::vec3(-1.7f, 3.0f, -7.5f),
glm::vec3( 1.3f, -2.0f, -2.5f),
glm::vec3( 1.5f, 2.0f, -2.5f),
glm::vec3( 1.5f, 0.2f, -1.5f),
glm::vec3(-1.3f, 1.0f, -1.5f)
};现在,在game loop的循环中,我们可以调用glDrawArrays函数10次,但是每次传给顶点处理程序的模型矩阵都是不同的。这样我们就能够得到分布在我们设定位置处的10个立方体。我们通过一个循环来完成调用:
glBindVertexArray(VAO);
for(GLuint i = 0; i < 10; i++)
{
glm::mat4 model;
model = glm::translate(model, cubePositions[i]);
GLfloat angle = 20.0f * i;
model = glm::rotate(model, angle, glm::vec3(1.0f, 0.3f, 0.5f));
glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model));
glDrawArrays(GL_TRIANGLES, 0, 36);
}
glBindVertexArray(0);通过上面的绘制,我们能够得到有不同的旋转角度的10个立方体。如下面的图所示:















 3867
3867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









