









最近发现了一个基于pandas的第三方库pandas_profling,其作用是基于pandas的DataFrame中的数据内容,一次性生成关于该DataFrame数据的描述性统计报告,该报告对于我们了解这个数据的基本特点和一些统计特性很有帮助,根据该报告可以让我们对该数据具有一个基本的认识和感知。本文先讲一下该报告包括了哪些内容,然后再讲一下使用方法。
该报告是html格式的,是一个交互式的网页报告,对用户很友好,页面布局也很清晰。该报告分成五个部分:Overview, Variables, Correlations, Missing values, Sample,可以从报告页面的右上角上看到,并可以进行点击。
Overview是对DataFrame的一个简单描述,包括变量个数(列数),行数,缺失值个数以及数据内存大小等信息,还有变量的数据类型。
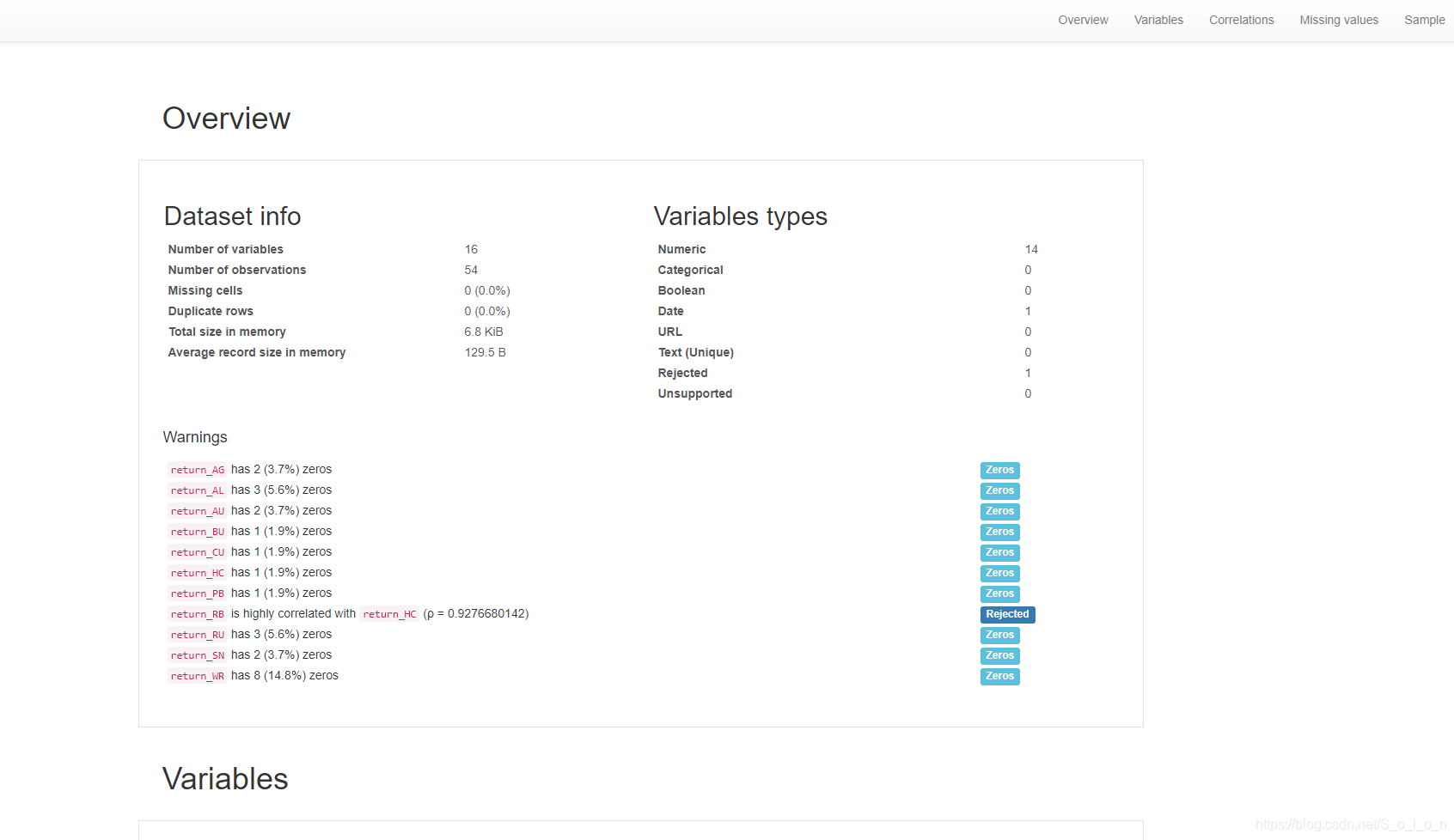
Variables部分是对每个变量,也即每列的统计描述、柱状图以及极端值等信息,统计描述包括最小值、最大值、四分位数Q1,Q2,Q3,5%分位数和95%分位数,还有数据的范围和四分位距(Q1和Q3的距离),还有标准差、变异系数、超值峰度(减去3之后的峰度)、偏度、均值、绝对离差、方差以及和等信息。
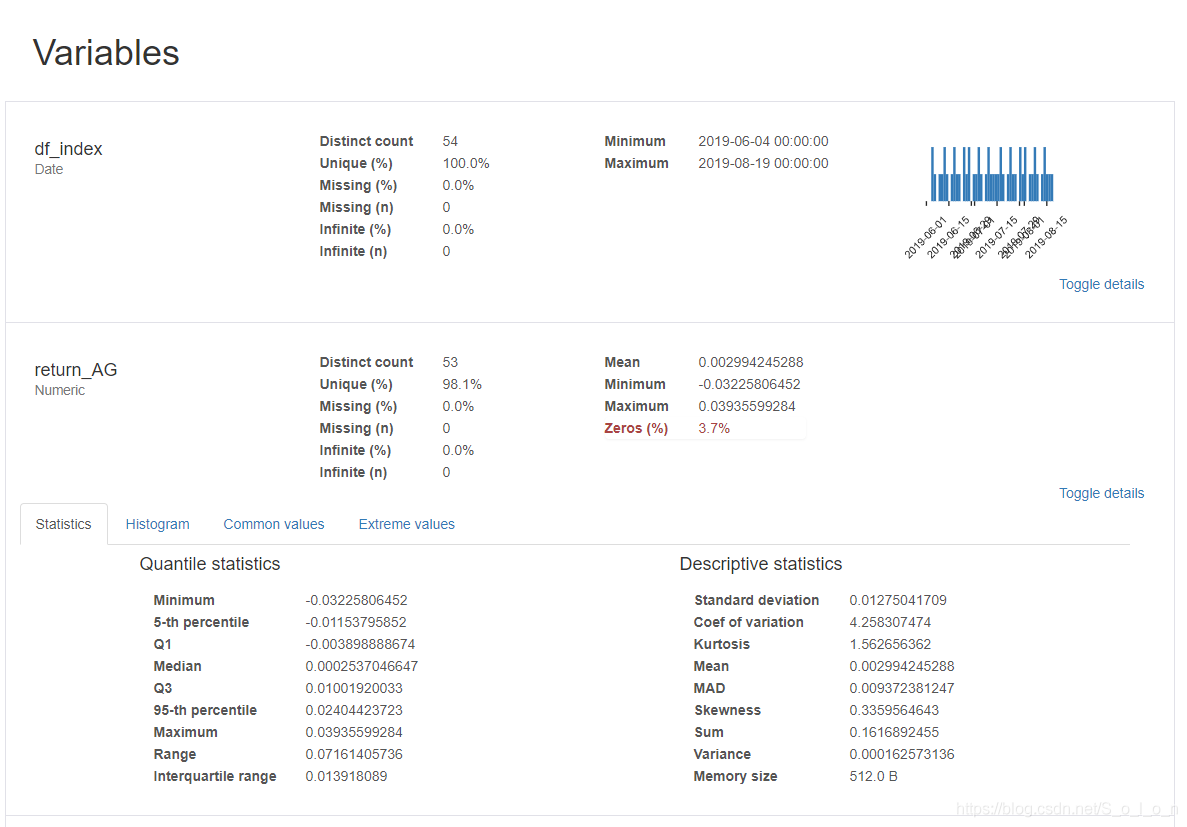
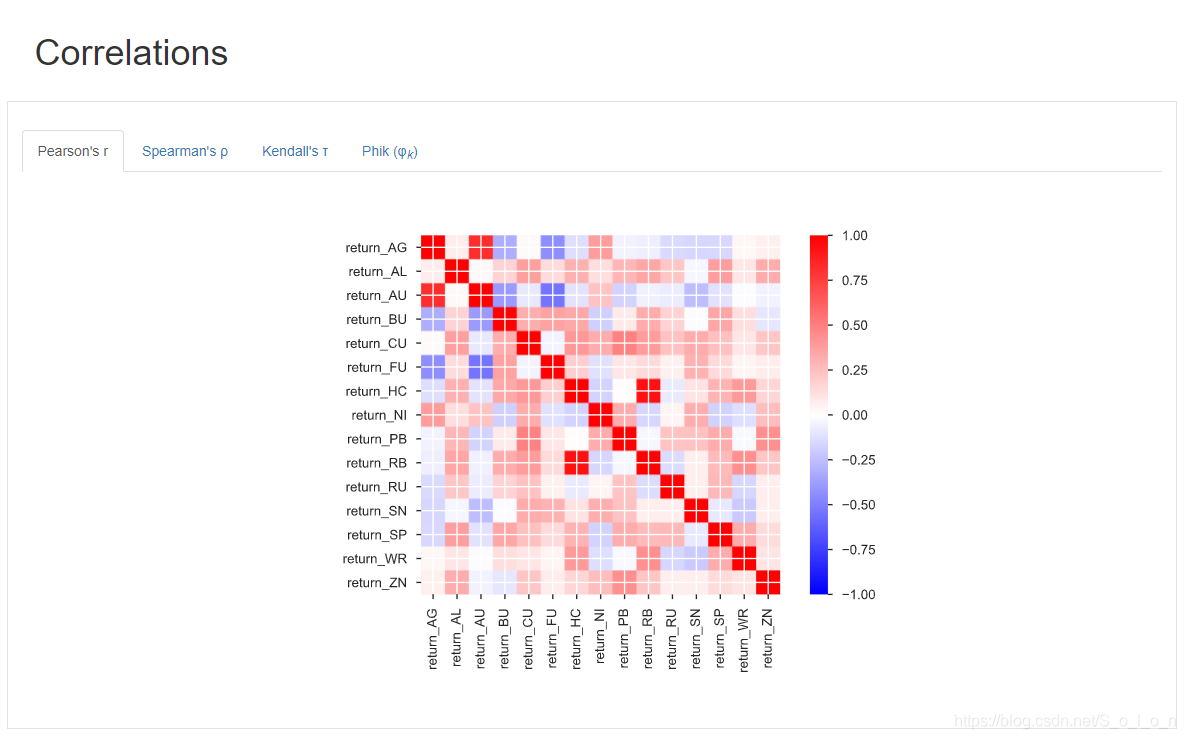
Correlations部分是关于各个变量之间的相关系数矩阵热力图,该报告提供了四个不同的相关性测度。
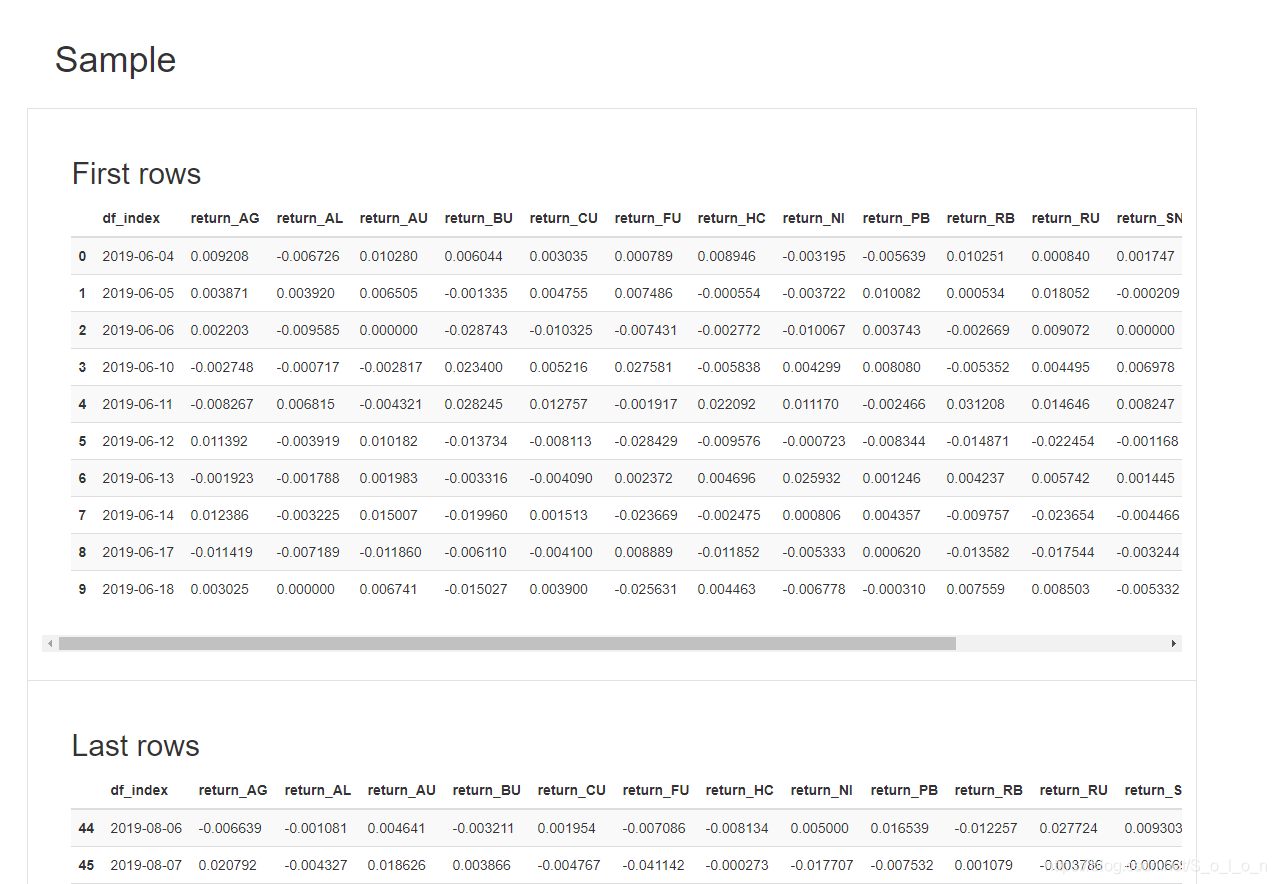
Missing values部分是关于缺失值的描述;Sample部分展示了该DataFrame的前十行和最后十行的数据,相当于df.head(10)和df.tail(10)。
该报告呈现的内容其实只是一些基础的内容,但是pandas_profiling的好处在于,其只用了一行代码帮我们一次性生成了,而且交互式的页面和清晰的页面布局让我们可以很直观的了解这些信息,通过以上呈现的内容,我们可以对该数据有一个基本了解,这是一个可以提高我们对数据进行预分析效率的工具。
但是使用该工具的一个问题在于,由于其是纯python代码实现的,而且由于生成的内容也比较多,所以如果数据量比较大,那么会花费比较久的时间,需要耐心等待一会儿。
安装
直接从PyPI上安装:pip install pandas-profiling
或者直接从github上安装:pip install <https://github.com/pandas-profiling/pandas-profiling/archive/master.zip>
conda安装: conda install -c conda-forge pandas-profiling
从源安装:下载好源文件后,直接运行命令行python setup.py install
使用方法
直接导入即可:import pandas_profiling
导入之后,pandas的DataFrame便有了profile_report方法,可以直接调用,返回一个HTML对象,然后再生成html文件即可。
代码实例
import pandas as pd
import jqdatasdk as jd
import pandas_profiling
jd.auth('********','********')
products_SHFE=['AG','AL','AU','BU','CU','FU','HC','NI','PB','RB','RU','SN','WR','ZN','SP']
contracts=[x+'9999.XSGE' for x in products_SHFE]
df=pd.DataFrame()
for contract in contracts:
product=contract.split('9999')[0]
df_tmp=jd.get_price(contract, start_date='2019-06-01', end_date='2019-8-19', frequency='daily', fields=None, skip_paused=False, fq='pre')
df['return_%s'%product]=df_tmp['close'].pct_change()
df=df.dropna()
profile=df.profile_report(title='SHFE RETURN DATA')
profile.to_file(output_file='SHFE_ANALYSIS.html')该代码示例是去分析上期所所有品种主力合约的收益率数据,获取的df是所有品种的近两个多月的收益率数据,对于pandas_profiling的使用,只需要看最后两行即可:调用profile_report方法,然后用to_file方法生成html文件即可。当然也可以参考文档进行更个性化的设置。















 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









