







**
1. 相关链接
:**
原文链接:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
原文开源代码:GitHub - google-research/vision_transformer
Pytorch版本代码:GitHub - lucidrains/vit-pytorch: Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
2. 参考
2.1 B站视频:ViT论文逐段精读【论文精读】
2.2 B站视频笔记
3. 前言
过去一年在计算机视觉领域影响力最大的工作:
- 挑战了自从2012年AlexNet提出以来卷积神经网络在计算机视觉里绝对统治的地位;
- 结论:如果在足够多的数据上做预训练,也可以不需要卷积神经网路,直接使用标准的Transformer也能够把视觉问题解决的很好;
- 打破了CV和NLP在模型上的壁垒,开启了CV的一个新时代
- 目前Transformer才刚刚开始应用到计算机视觉领域,还有很大的进步空间,未来的效果可能会更佳。
-
可以查询现在某个领域或者说某个数据集表现最好的一些方法有哪些
-
图像分类在ImageNet数据集上排名靠前的全是基于Vision Transformer
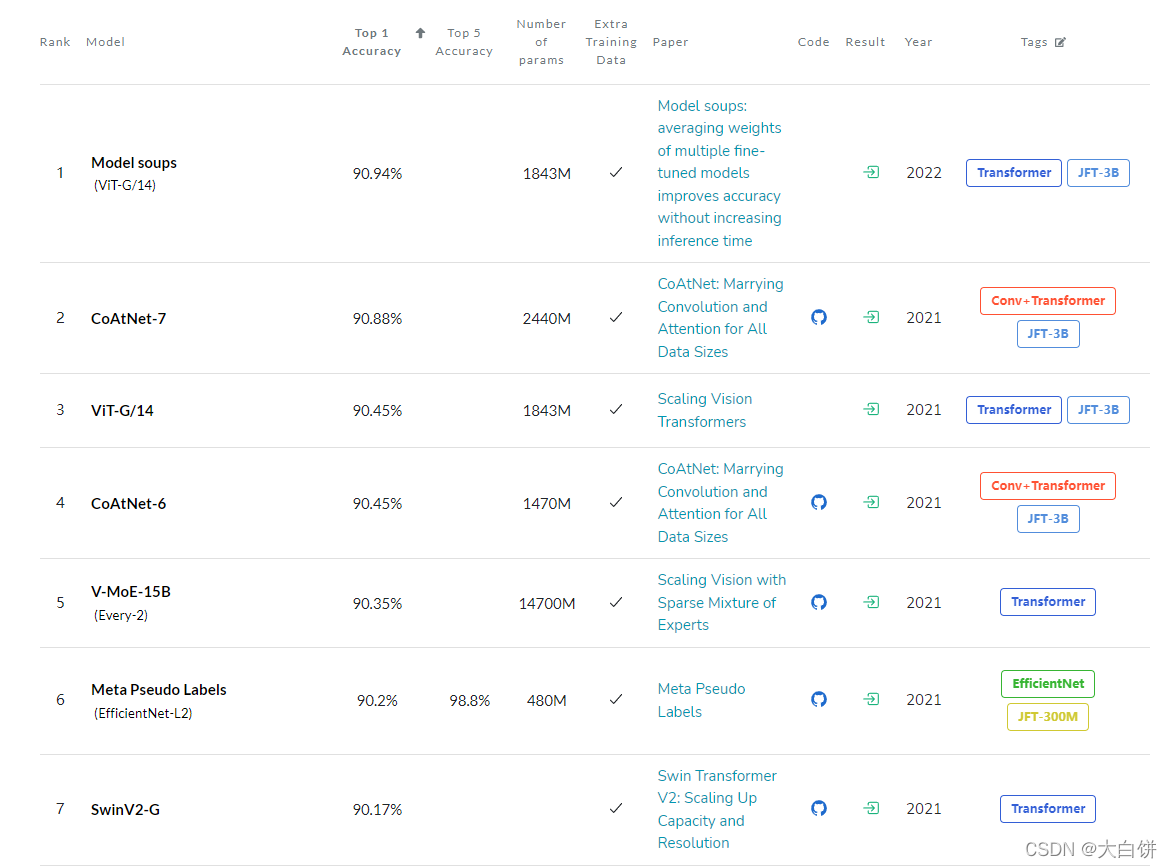
-
对于目标检测任务在COCO数据集上,排名靠前都都是基于Swin Transformer(Swin Transformer是ICCV 21的最佳论文,可以把它想象成一个多尺度的ViT(Vision Transformer))
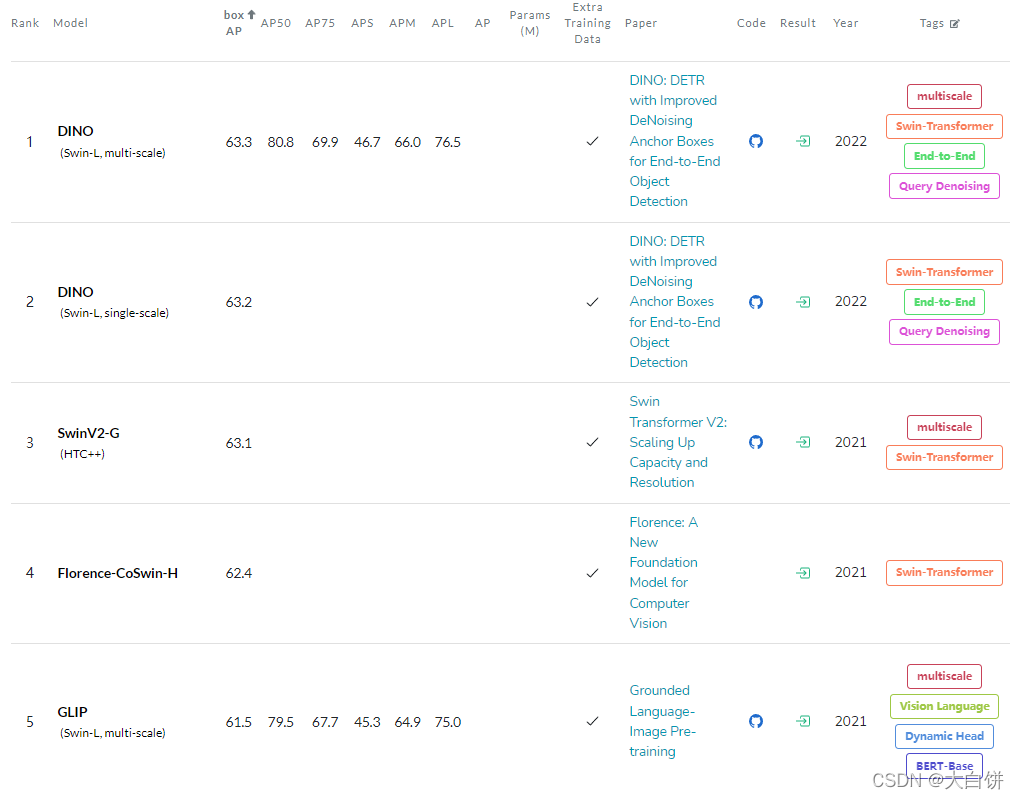 - 在其他领域(语义分割、实例分割、视频、医疗、遥感),基本上可以说Vision Transformer将整个视觉领域中所有的任务都刷了个遍
- 在其他领域(语义分割、实例分割、视频、医疗、遥感),基本上可以说Vision Transformer将整个视觉领域中所有的任务都刷了个遍
作者介绍的另一篇论文:Intriguing Properties of Vision Transformer(Vision Transformer的一些有趣特性)
如下图所示:
- 图a表示的是遮挡,在这么严重的遮挡情况下,不管是卷积神经网络,人眼也很难观察出图中所示的是一只鸟
- 图b表示数据分布上有所偏移,这里对图片做了一次纹理去除的操作,所以图片看起来比较魔幻
- 图c表示在鸟头的位置加了一个对抗性的patch
- 图d表示将图片打散了之后做排列组合
上述例子中,卷积神经网络很难判断到底是一个什么物体,但是对于所有的这些例子Vision Transformer都能够处理的很好。

4. 标题+作者
4.1 An Image is Worth 16x16 Words:
- 一张图片等价于很多16×16大小的单词(比如下图,可以将图片分成4×5=20个小块,每个小块称为一个Patch,每一个Patch又是16×16像素的)
- 为什么是16×16的单词?将图片看成是很多的patch,假如把图片分割成很多方格的形式,每一个方格的大小都是16×16,那么这张图片就相当于是很多16×16的patch组成的整体。

4.2 Transformers for Image Recognition at Scale
- 使用transformer去做大规模的图像识别
4.3 作者
- 作者团队来自于google research和google brain team
5. 摘要 Abstract
虽然说transformer已经是NLP(自然语言处理)领域的一个标准:BERT模型、GPT3或者是T5模型,但是用transformer来做CV还是很有限的
在视觉领域,自注意力要么是跟卷积神经网络一起使用,要么用来把某一些卷积神经网络中的卷积替换成自注意力,但是还是保持整体的结构不变
- 这里的整体结构是指:比如说对于一个残差网络(Res50),它有4个stage:res2、res3、res4、res5,上面说的整体结构不变指的就是这个stage是不变的,它只是去取代每一个stage、每一个block的操作
这篇文章证明了这种对于卷积神经网络的依赖是完全不必要的,一个纯的Vision Transformer直接作用于一系列图像块的时候,也是可以在图像分类任务上表现得非常好的,尤其是当在大规模的数据上面做预训练然后迁移到中小型数据集上面使用的时候,Vision Transformer能够获得跟最好的卷积神经网络相媲美的结果
这里将ImageNet、CIFAR-100、VATB当作中小型数据集
- 其实ImageNet对于很多人来说都已经是很大的数据集了
Transformer的另外一个好处:它只需要更少的训练资源,而且表现还特别好
- 作者这里指的少的训练资源是指2500天TPUv3的天数
- 这里的少只是跟更耗卡的模型去做对比(类似于先挣一个亿的小目标)
6. 引言
自注意力机制的网络,尤其是Transformer,已经是自然语言中的必选模型了,现在比较主流的方式,就是先去一个大规模的数据集上去做预训练,然后再在一些特定领域的小数据集上面做微调(这个是在BERT的文章中提出来的)
得益于transformer的计算高效性和可扩展性,现在已经可以训练超过1000亿参数的模型了,比如说GPT3
随着模型和数据集的增长,目前还没有发现任何性能饱和的现象
- 很多时候不是一味地扩大数据集或者说扩大模型就能够获得更好的效果的,尤其是当扩大模型的时候很容易碰到过拟合的问题,但是对于transformer来说目前还没有观测到这个瓶颈
- 最近微软和英伟达又联合推出了一个超级大的语言生成模型Megatron-Turing,它已经有5300亿参数了,还能在各个任务上继续大幅度提升性能,没有任何性能饱和的现象
6.1 回顾Transformer:
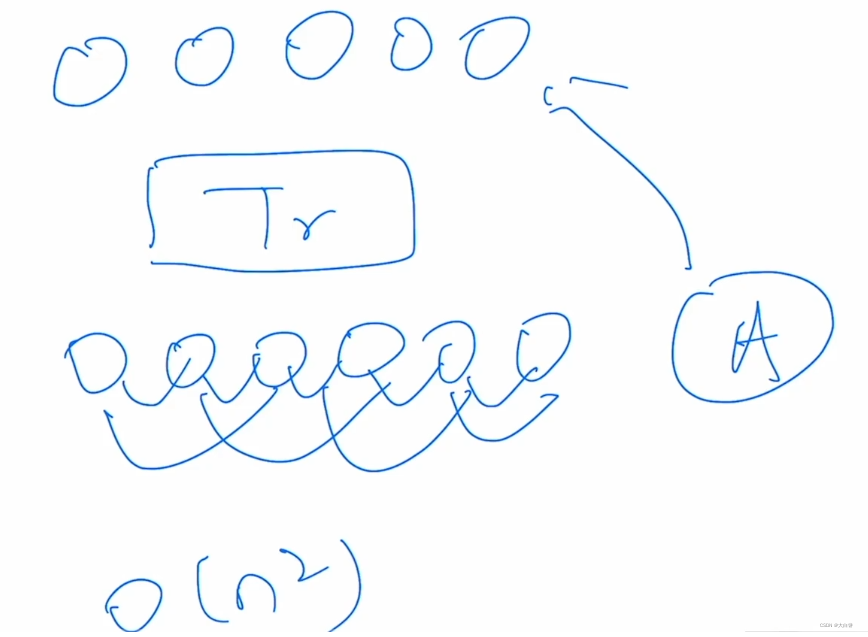
- transformer中最主要的操作就是自注意力操作,自注意力操作就是每个元素都要跟每个元素进行互动,两两互相的,然后算得一个attention(自注意力的图),用这个自注意力的图去做加权平均,最后得到输出
- 因为在做自注意力的时候是两两互相的,这个计算复杂度是跟序列的长度呈平方倍的。O(n2)
- 目前一般在自然语言处理中,硬件能支持的序列长度一般也就是几百或者是上千(比如说BERT的序列长度也就是512)
6.2 把Transformer用到视觉问题上的难处:
首先要解决的是如何把一个2D的图片变成一个1D的序列(或者说变成一个集合)。最直观的方式就是把每个像素点当成元素,将图片拉直放进transformer里,看起来比较简单,但是实现起来复杂度较高。
一般来说在视觉中训练分类任务的时候图片的输入大小大概是224×224,如果将图片中的每一个像素点都直接当成元素来看待的话,他的序列长度就是224×224=50176个像素点,也就是序列的长度,这个大小就相当于是BERT序列长度的100倍(上面说到BERT的序列长度是512),这还仅仅是分类任务,对于检测和分割,现在很多模型的输入都已经变成600×600或者800×800或者更大,计算复杂度更高,所以在视觉领域,卷积神经网络还是占主导地位的,比如AlexNet或者是ResNet。
所以现在很多工作就是在研究如何将自注意力用到机器视觉中:一些工作是说把卷积神经网络和自注意力混到一起用;另外一些工作就是整个将卷积神经网络换掉,全部用自注意力。这些方法其实都是在干一个事情:因为序列长度太长,所以导致没有办法将transformer用到视觉中,所以就想办法降低序列长度。
例1:Wang et al.,2018 (Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In
CVPR, 2018.):既然用像素点当输入导致序列长度太长,就可以不用图片当transformer的直接输入,可以把网络中间的特征图当作transformer的输入。
- 假如用残差网络Res50,其实在它的最后一个stage,到res4的时候的featuremap的size其实就只有14×14了,再把它拉平其实就只有196个元素了,即这个序列元素就只有196了,这就在一个可以接受的范围内了。所以就通过用特征图当作transformer输入的方式来降低序列的长度。
例2:Ramachandran et al., 2019(Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jon Shlens.Stand-alone self-attention in vision models. In NeurIPS, 2019.)孤立自注意力
孤立自注意力:之所以视觉计算的复杂度高是来源于使用整张图,所以不使用整张图,就用一个local window(局部的小窗口),这里的复杂度是可以控制的(通过控制这个窗口的大小,来让计算复杂度在可接受的范围之内)。这就类似于卷积操作(卷积也是在一个局部的窗口中操作的)
例3:Wang et al., 2020a(Huiyu Wang, Yukun Zhu, Bradley Green, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen.Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. In ECCV, 2020a.)轴自注意力
轴自注意力:之所以视觉计算的复杂度高是因为序列长度N=H×W,是一个2D的矩阵,将图片的这个2D的矩阵想办法拆成2个1D的向量,所以先在高度的维度上做一次self-attention(自注意力),然后再在宽度的维度上再去做一次自注意力,相当于把一个在2D矩阵上进行的自注意力操作变成了两个1D的顺序的操作,这样大幅度降低了计算的复杂度。
最近的一些模型,这种方式虽然理论上是非常高效的,但事实上因为这个自注意力操作都是一些比较特殊的自注意力操作,所以说无法在现在的硬件上进行加速,所以就导致很难训练出一个大模型,所以截止到目前为止,孤立自注意力和轴自注意力的模型都还没有做到很大,跟百亿、千亿级别的大transformer模型比还是差的很远,因此在大规模的图像识别上,传统的残差网络还是效果最好的
所以,自注意力早已经在计算机视觉里有所应用,而且已经有完全用自注意力去取代卷积操作的工作了,所以本文换了一个角度来讲故事。
本文是被transformer在NLP领域的可扩展性所启发,本文想要做的就是直接应用一个标准的transformer直接作用于图片,尽量做少的修改(不做任何针对视觉任务的特定改变),看看这样的transformer能不能在视觉领域中扩展得很大很好。
但是如果直接使用transformer,还是要解决序列长度的问题
- vision transformer将一张图片打成了很多的patch,每一个patch是16*16
- 假如图片的大小是224×224,则sequence lenth(序列长度)就是N=224×224=50176,如果换成patch,一个patch相当于一个元素的话,有效的长宽就变成了224/16=14,所以最后的序列长度就变成了N=14×14=196,所以现在图片就只有196个元素了,196对于普通的transformer来说是可以接受的。
- 然后将每一个patch当作一个元素,通过一个fc layer(全连接层)就会得到一个linear embedding,这些就会当作输入传给transformer,这时候一张图片就变成了一个一个的图片块了,可以将这些图片块当成是NLP中的单词,一个句子中有多少单词就相当于是一张图片中有多少个patch,这就是题目中所提到的一张图片等价于很多16×16的单词。
本文训练vision transformer使用的是有监督的训练
- 为什么要突出有监督?因为对于NLP来说,transformer基本上都是用无监督的方式训练的,要么是用language modeling,要么是用mask language modeling,都是用的无监督的训练方式。但是对于视觉来说,大部分的基线(baseline)网络还都是用的有监督的训练方式去训练的。
到此可以发现,本文确实是把视觉当成自然语言处理的任务去做的,尤其是中间的模型就是使用的transformer encoder,跟BERT完全一样,这篇文章的目的是说使用一套简洁的框架,transformer也能在视觉中起到很好的效果。
这么简单的想法,之前其实也有人想到去做,本文在相关工作中已经做了介绍,跟本文的工作最像的是一篇ICLR 2020的paper(Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between selfattention and convolutional layers. In ICLR, 2020.)
- 这篇论文是从输入图片中抽取2×2的图片patch
- 为什么是2×2?因为这篇论文的作者只在CIFAR-10数据集上做了实验,而CIFAR-10这个数据集上的图片都是32×32的,所以只需要抽取2×2的patch就足够了,16×16的patch就太大了
- 在抽取好patch之后,就在上面做self-attention
从技术上而言他就是Vision Transformer,但是本文的作者认为二者的区别在于本文的工作证明了如果在大规模的数据集上做预训练的话(和NLP一样,在大规模的语料库上做预训练),那么就能让一个标准的Transf
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1757
1757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









