







文件
什么是文件?

文件的打开方式:

打开文件:
f = open('F:\\record.txt') # 默认打开方式为只读
print(f)
## 结果为<_io.TextIOWrapper name='F:\\record.txt' mode='r' encoding='cp936'>
文件对象方法:

文件对象方法关于读文件的示例:
f = open('F:\\record.txt')
print(f)
print(f.read()) # 结果为zhai
print(f.tell()) # 返回当前文件指针位置,一共有4个英文字符,所以指向4。中文字符每个占2字节。
# print(f.read(3)) # 结果为zha
print(f.seek(2, 0)) # 在文件中移动指针,使得指针偏移2个字节
print(f.readline()) # 结果为ai
文件对象方法关于写文件的示例:
f = open('F:/test.txt', 'w') # 将文件打开模式设置为可写w
print(f)
f.write('I love zhangyixing!')
f.close() # 关闭之后立即将上述东西写入文件,不然只是放在其缓冲区内
【例】将record.txt文件中的对话内容按照======分割成3段对话,在每段对话中提取不同角色的说话内容并保存到相应的新文件中去。

将其划分为对应的文件,如下所示:

每个文件里保存相应角色在不同对话中的谈话内容。(如consultant1.txt保存了客服在第一段对话中的谈话内容)。consultant1.txt文件内容如下所示:
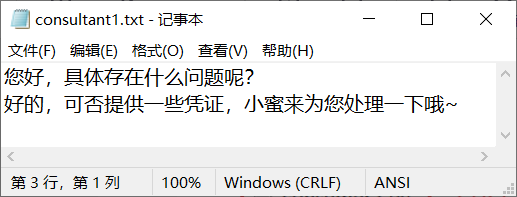
具体代码如下所示:
f = open('F:\\record.txt', encoding='UTF-8')
consumer = [] # 保存顾客语句
consultant = [] # 保存客服语句
count = 1
for each_line in f:
if each_line[:6] != '======': #分割字符串:无需判断那么长,只需要判断前6个是否为=
# 按照======字符串进行分割
(role, line_spoken) = each_line.split(':', 1) # 按照:区分人物及语句
if role == '顾客':
consumer.append(line_spoken) # 当冒号前面的字符为“顾客”时,将冒号后面的字符添加到consumer = []中
if role == '客服':
consultant.append(line_spoken) # 当冒号前面的字符为“客服”时,将冒号后面的字符添加到consultant = []中
else:
# 文件的分别保存操作
file_name_consumer = 'consumer' + str(count) + '.txt'
file_name_consultant = 'consultant' + str(count) + '.txt'
consumer_file = open(file_name_consumer, 'w')
consultant_file = open(file_name_consultant, 'w')
consumer_file.writelines(consumer) # 多个语句按序列写用writelines
consultant_file.writelines(consultant)
consumer_file.close() # 关闭文件才能保存之前写入的内容
consultant_file.close()
consumer = [] # 为了下一次循环初始化
consultant = []
count += 1
# 因为上述分割过程是按“======”分割的,而原本的文档中是用两行“======”分成三个对话,最后一段对话需要单独处理
file_name_consumer = 'consumer' + str(count) + '.txt'
file_name_consultant = 'consultant' + str(count) + '.txt'
consumer_file = open(file_name_consumer, 'w')
consultant_file = open(file_name_consultant, 'w')
consumer_file.writelines(consumer)
consultant_file.writelines(consultant)
consumer_file.close()
consultant_file.close()
f.close() # 关闭record文件
注意:文件操作执行完记得close,避免忘记关闭文件导致资源的占用。
上述代码重复部分太多,代码可读性差,我们需要对它进行优化。很容易的就可以想到,我们可以定义几个函数来对一些重复操作进行封装,优化后的代码如下所示:
# 分别保存文档操作
def save_file(consumer, consultant, count):
file_name_consumer = 'consumer' + str(count) + '.txt'
file_name_consultant = 'consultant' + str(count) + '.txt'
consumer_file = open(file_name_consumer, 'w')
consultant_file = open(file_name_consultant, 'w')
consumer_file.writelines(consumer) # 多个语句按序列写用writelines
consultant_file.writelines(consultant)
consumer_file.close() # 关闭文件才能保存之前写入的内容
consultant_file.close()
# 分割文档操作
def split_file(file_name):
f = open(file_name, encoding='UTF-8')
consumer = [] # 保存顾客语句
consultant = [] # 保存客服语句
count = 1
for each_line in f:
if each_line[:6] != '======':
# 按照======字符串进行分割
(role, line_spoken) = each_line.split(':', 1)
if role == '顾客':
consumer.append(line_spoken)
if role == '客服':
consultant.append(line_spoken)
else:
# 文件的分别保存操作
save_file(consumer, consultant, count)
consumer = [] # 为了下一次循环初始化
consultant = []
count += 1
save_file(consumer, consultant, count) # 单独处理最后一段对话
f.close() # 关闭file_name文件
# 对record.txt进行分割
split_file('F:\\record.txt')
以上代码同样能够实现任务要求,在与该python文件的同目录下建立好了任务所需的文档。
















 8877
8877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









