







应该是21 Oct 2021那一版(有些pdf下出来是27 May 2021的,两者有些出入):学习具有时空注意力的大脑连接组的动态图表示 – arXiv虚荣心 (arxiv-vanity.com)
OpenReview:基于时空注意力的脑连接组学习动态图表示 |OpenReview的
作者提供代码:GitHub - egyptdj/stagin: STAGIN: Spatio-Temporal Attention Graph Isomorphism Network
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用!
目录
2.3.1. Graph neural network on dynamic graphs
2.3.2. Attention in graph neural networks
2.4.2. Graph Isomorphism Network
2.4.3. Encoder-decoder understanding of GNNs
2.5. STAGIN: Spatio-Temporal Attention Graph Isomorphism Network
2.5.1. Dynamic graph definitio
2.5.2. Spatial attention with attention-based READOUT
2.5.3. Temporal attention with Transformer encoder
2.6.3. HCP-Rest: Gender classification
2.6.4. HCP-Task: Task decoding
1. 省流版
1.1. 心得
(1)只能说最开始看到排版就挺绷不住的,表和图都放附录。会议要求吗是
(2)好难啊数学部分,而且引用了很多别人的,在他们论文里面就没有细说
1.2. 论文框架图

2. 原文逐段阅读
2.1. Abstract
①Previous work did not analyse the temporal information of brain images
②Albeit dynamic functional connectivity (FC) was used in research, their works are lack of temporal interpretation and are low in accuracy
③The authors put forward Spatio-Temporal Attention Graph Isomorphism Network (STAGIN) model which based on dynamic image and includes READOUT and Transformer. READOUT function brings spatial interpretation and Transformer brings temporal interpretion for STAGIN.
④Dataset: Human Connectome Project (HCP)-Rest and HCP-Task
2.2. Introduction
①Briefly introduce functional magnetic resonance imaging (fMRI)
②Present current trend, putting GNN in brain image analysis. Most of them adopt model to resting state and tasking state fMRI to classify phenotype or disease
③Deficiencies of other models
④Generally talking'bout their STADIN
⑤我完全没有读懂什么滥用解码??
Our work holds potential societal impact in that brain decoding methods can be linked to finding neural biomarkers of important phenotypes or diseases. However, potential negative impact related to privacy concerns that arise from abuse or misuse of accurate decoding methods should also be noted. Although our method is yet behind the decoding capability that can be abused or misused, our research cannot still be free from these ethical considerations.
isomorphism n.同构;类质同象;类质同晶型(现象);同(晶)型性
2.3. Related works
2.3.1. Graph neural network on dynamic graphs
①Dynamic networks might bring changes of nodes and edges, which causes a big challenge
②Unique node encoding and edge feature are what authors want
2.3.2. Attention in graph neural networks
①Attention mechanism presents great in edge computing and scaling node features. Moreover, pooling mechanism is also an application of attention mechanism in brain maps
②Randomly initializing parameters or local graph structures for attention scoring, the authors challenge their effectiveness
vertice n.顶点
2.4. Theory
2.4.1. Problem definition
①Define is at time
, where
is
nodes set and
is edges set.
represents the neighborhood of the vertex
②They define a mapping function:
where stores
timepoints graphs,
is a vector with
dimensions;
, which represents GNN;
, which represents Transformer encoder.
③The authors reckon this function explain the important areas of brain
disentangle vt.使解脱;使摆脱;分清,清理出(混乱的论据、想法等);理顺;解开…的结;使脱出
2.4.2. Graph Isomorphism Network
①A Graph Isomorphism Network (GIN), which is the variant of the GNN, includes AGGREGATE and COMBINE. The authors set AGGREGATE function to extract features from neighbors and COMBINE function to obtain features from the next layer:
where denotes feature vector of node
at layer
and
is a learnable parameter initialized with 0.
②Reformulated to matrix
:
where is identity matrix,
is the adjacency matrix between the node features,
is the weights of the MLP layer,
is the nonlinearity function.
③The READOUT function calculates all features in the whole graph
where denotes calculating the mean value of matrix and reforming the matrix to a vector (mean of rows). Or sometimes
can also be used as a pooling vector.
can be regarded as decoder.
2.4.3. Encoder-decoder understanding of GNNs
①The whole method (a) and READOUT module (b):

②Input encoder in -th layer:
where denotes Kronecker product
③Then node feature:
(为什么又来一个H啊我不是很明白了)
where is diagonal matrix with its elements are 0 or 1. This value depends on specific activation pattern.
④The authors prove is decoder:
Firstly we know,
Then assuming is the
-th column of the encoder matrix
,
is is the
-th column of the decoder matrix
;
Change the expression of :
;
Obviously, the is a constant, hence this encoder-decoder is reasonable.
(???可能是我注意力机制的数学没学精,常数就代表可以?)
2.5. STAGIN: Spatio-Temporal Attention Graph Isomorphism Network
①(a) presents how to extract features, (b) is a example of dynamic graph structure
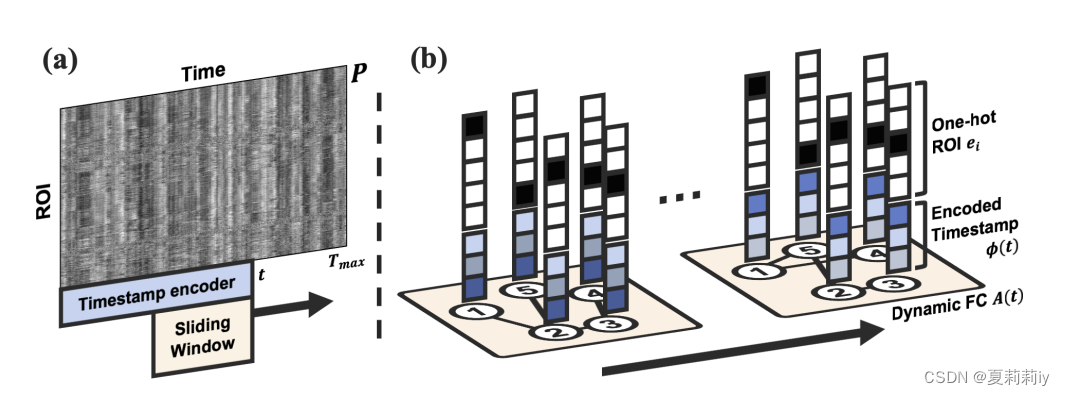
2.5.1. Dynamic graph definitio
①They use 4D fMRI data with 3D voxels across time
②ROI-timeseries matrix : mean values of
ROIs at each timepoint
③Stride of sliding-window with length is
.
windowed matrices can be gotten.
④Correlation coefficient matrix of FC at time :
where and
are from (a),
,
and
are row and column indices respectively,
is cross covariance,
represents standard deviation of
.
⑤Lastly change to
by only retaining the top 30% values
⑥To achieve temporal variation, they concatenate encoded timestamp , which is a Gated Recurrent Unit (GRU), to spatial one-hot encoding
⑦Node features are with learnable parameter matrix :
2.5.2. Spatial attention with attention-based READOUT
①The spatial attention:
where is the attention function,
is spatially attended graph of
.
②They adopt two attention functions, Graph-Attention READOUT (GARO) and Squeeze-Excitation READOUT (SERO)
(1)GARO: Graph-Attention READOUT
Based on key-query embedding of Transformer, its computing method shows below:
where is learnable key parameter matrix,
is is learnable query parameter matrix,
is the embedded key matrix,
is the embedded query vector.
(2)SERO: Squeeze-Excitation READOUT
The SERO will not scale the channel dimension, but scale the node dimension:
where are learnable parameter matrices.
(3)Orthogonal regularization
For increasing presenting range in and decreasing possibility of null subspace within
, they use orthogonal regularization:
where .
2.5.3. Temporal attention with Transformer encoder
Single-headed Transformer encoder for acrossing time:
2.6. Experiment
2.6.1. Dataset
①Dataset: HCP S1200 releaseHCP S1200 版本现已在亚马逊云科技上推出 - Connectome (humanconnectome.org)
②Dividing of dataset: HCP-Rest and the HCP-Task
③Pre-process and ICA denoised for HCP-Rest dataset and pre-process for HCP-Task dataset
④Sample: 1093 (female: 594, male: 499) excluding for HCP-Rest and 7450 excluding short time for HCP-Task
⑤Number of classes: for Rest and
for Task
⑥Task: working memory, social, relational, motor, language, gambling, and emotion types
2.6.2. Experimental settings
①Table of two datasets:

②Loss function:
where is scaling coefficient of the orthogonal regularization
③Layers:
④Embedding dimension
⑤Window length
⑥Window stride
⑦regularization coefficient
⑧Capturing FC: 36 seconds every 2.16 seconds (standard)
⑨Dropout rate: 0.5 for and 0.1 for
and
⑩Activation function: GELU
⑪One-cycle learning rate policy: "learning rate is gradually increased from 0.0005 to 0.001 during the early 20% of the training, and gradually decreased to 5.0×10−7 afterwise"
⑫Epochs: 30 for Rest and 10 for Task
⑬Batch: 3 for Rest and 16 for Task
⑭Cross-validation: 5 fold
⑮Atlas: Schaefer atlas with 400 regions and 7 intrinsic connectivity networks (ICNs)
⑯Dimension of ROI-timeseries: randomly sliced with a fixed length (600 for HCP-Rest, 150 for HCP-Task) for reducing computing time, randomly augmenting data, reducing unwanted memorization, ensuring across different task labels
⑰Unsliced full matrix : inference at test time
2.6.3. HCP-Rest: Gender classification
①Goal: classify gender
②Comparison is in 2.6.2. ①
③"Female subjects show hyperconnectivity of the DMN and hypoconnectivity of the SMN when compared to male subjects"
④Temporal attention of the gender classification with k-means clustering:

2.6.4. HCP-Task: Task decoding
①They designed a GLM to analyze the spatially attended regions :
where is residual error
②Mean temporal attention showed in (a) and proportion of statistically significant regions within the 7 ICNs for each layers showed in (b)

2.7. Conclusion
STAGIN peforms great in gender classification through 4D-fMRI
3. 知识补充
3.1. Kronecker product
(1)Definition: two matrices with any shape are able to calculating Kronecker product
(2)Example:
given ,
(3)Further understanding: 【基础数学】克罗内克内积 Kronecker product-CSDN博客
4. Reference List
Kim, B., Ye, J. & Kim, J. (2021) 'Learning Dynamic Graph Representation of Brain Connectome with Spatio-Temporal Attention', NeurIPS 2021. doi: https://doi.org/10.48550/arXiv.2105.13495














 4883
4883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









