








英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4.1. In-Distribution Setting
2.4.2. Out-of-Distribution Setting
2.6.3. Self-Supervised Contrastive Learning
2.7. Exploring the Robustness of Vision-Language Models for VQA
2.8. Discussions and Future Directions
1. 心得
(1)宝贝你都TPAMI了我还有什么理由不看呢
(2)介绍了对学习到偏差/某个固定分布问题,数据集和模型各自的解决办法
(3)可以说总结概括都还ok但不是那种一眼惊艳的文章(人总是对TPAMI有额外的期望
2. 论文逐段精读
2.1. Abstract
①Existing visual question answering (VQA) methods is lack of generalization
2.2. Introduction
①Significance of VQA: image retrieval, intelligent virtual assistants, visual recommendation systems, autonomous driving(啊这样的吗??)
②Methods of VQA: joint embedding, attention mechanism, and external knowledge
③In distribution (ID) performance and out of distribution (OOD) performance:

(作者意思是在某个数据集里面Q是问what sports且非常多个问what sports的回答A都是tennis因此机器认为这俩东西挂钩了导致别的运动也会被回答为tennis)(这个就是学习到了偏见,是很常见的问题)
2.3. Preliminaries
2.3.1. Task Formulation
①Discriminative VQA: for dataset with
triplets
, where
denotes image,
denotes question,
denotes answer. By optimizing parameters
, models predict the answer:
②Generative VQA: for dataset , it predicts answers token by token. Thus the optimization goal is maximize the conditional probability
:
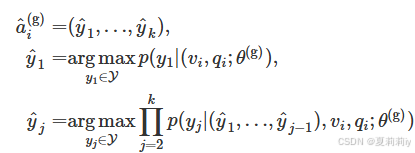
where is the set of all tokens in the corpus,
denotes the number of tokens in
2.3.2. VQA Paradigm
(1)Non-Debiasing
①Discriminative VQA: combining patch level image encoder , word-level question encoder
, multi-modality encoder
and predictor
. Just like:
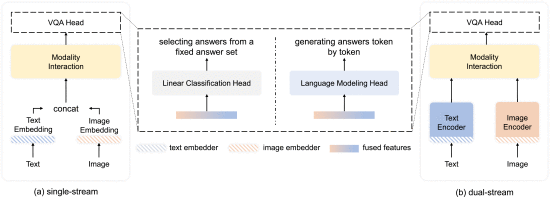
使用不同的/相同的Transformer来替换编码器被作者称为双流/单流方法:
②Generative VQA: with patch level image encoder and word-level question encoder
, the decoder directly be
. The paradigm is:
(2)Debiasing
①Fake connections: Q & key words
②The non-debiasing methods predict answers by:
⭐language bias learning is more prevalent than vision bias learning
③Multimodal bias learning:
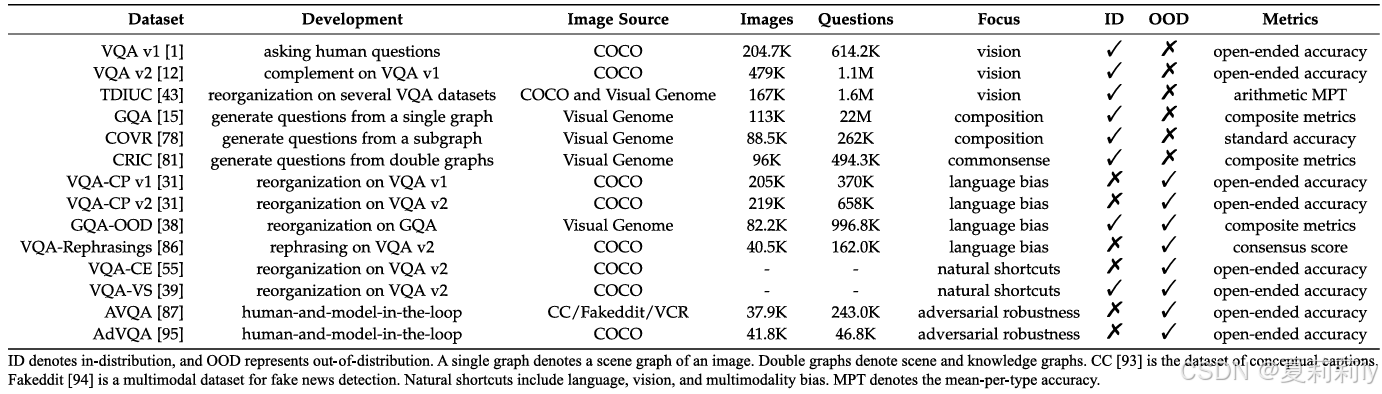
2.4. Datasets
2.4.1. In-Distribution Setting
①VQA v1: Q&A with 10 subjects:
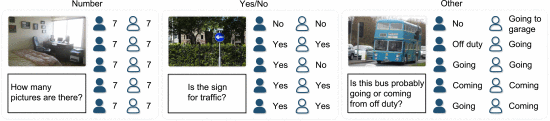
type of answers: "(number)", "Yes/No", "Other" (might be multi true answer in other option)
②VQA v2 (to solve the bias problem in v1): designed similar stimuli with different answer:

but distribution still affects
③TDIUC: COCO based, add 12 types of questions such as positional reasoning and activity recognition
④GQA: more complex question

⑤COVR: only one true answer, and add logical operators such as quantifiers and aggregations
⑥CRIC: contains annotations triples such as the commonsense knowledge “(subject: fork, relation: is used for, object: moving food)”
2.4.2. Out-of-Distribution Setting
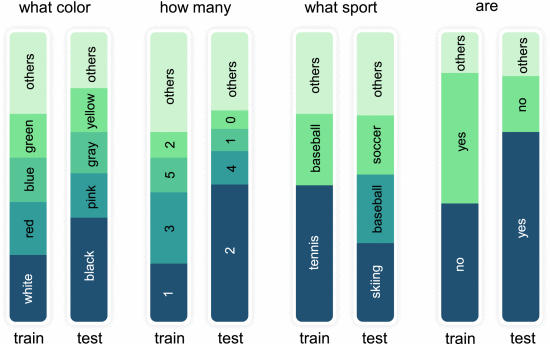
①VQA-CP v1 & VQA-CP v2: 370 K questions with 205 K images are in VQA-CP v1 and 658 K questions with 219 K images are in VQA-CP v2. ⭐There are significant distribution difference between train set and test set:
②GQA-OOD: evaluate ID and OOD performance by answer groups:
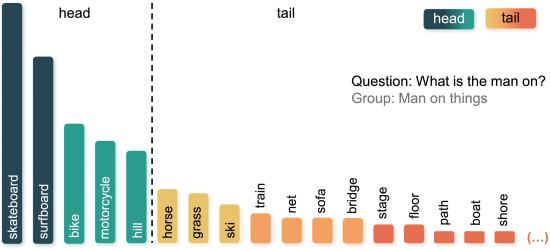
which contains 53 K questions with 9.7 K images
③VQA-Rephrasings: 162.0 K questions with 40.5 K images are used to measure answer changes when question change (just words, which causes fault prediction)

④VQACE: short-cut example:

⑤VQA-VS: provide more specific shortcut
⑥AVQA: 243.0 K questions accompanied by 37.9 K images, collects fail-predicted Q&A
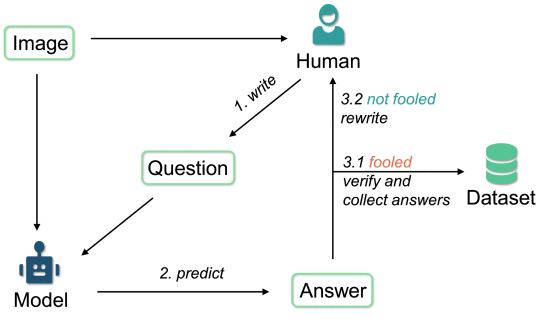
⑦AdVQA: adversarial also, contains 46.8 K questions accompanied by 41.8 K images
⑧Overview of VQA datasets:
2.5. Evaluations
①Open-Ended Accuracy:
where denotes the number of predicted answers that are identical to human-provided answers for questions and 3 is the minimum number of consensuses
②Composite Metrics: Consistency, Validity/Plausibility, Distribution, Grounding
③Arithmetic MPT: by TDIUC
④Consensus Score: proposed by VQA-Rephrasings:
where is the number of subsets with size
sampled from a set with size
,
is a group of questions contained in
that consists of
rephrasings, and
is the open-ended accuracy.
2.6. Debiasing Methods
①Categories: ensemble learning, data augmentation, self-supervised contrastive learning, and answer re-ranking
②Summarizing of existing methods:
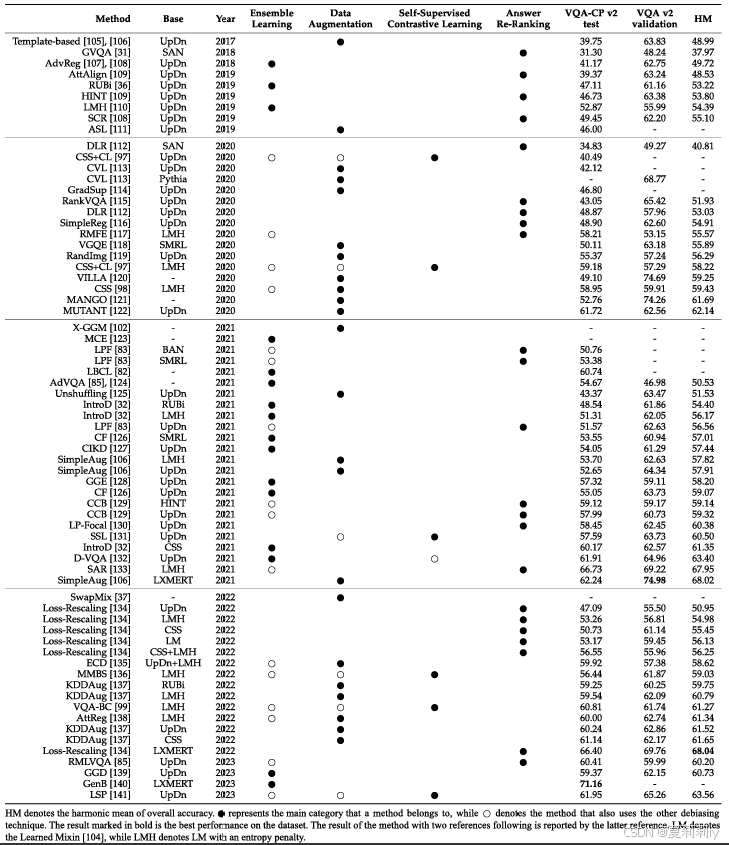
③Methods in other dataset:

2.6.1. Ensemble Learning
①Contains combination of a bias branch
:
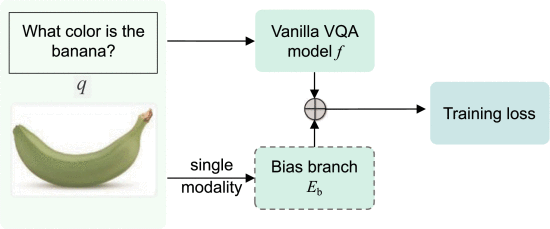
(就是一般测试的时候还是问题和图片都进去学,但这个集成学习是训练的时候用两个模态但测试的时候只用一个模态。看上去有点离谱了,测试为什么只用一个模态?我没理解错吧?↓)

2.6.2. Data Augmentation
①Generate additional ugmented question-answer pairs
②Answer prediction:
③Main methods: 1) synthetic-based: generate new training samples by modifying regions or words of the original images or questions; 2) pairing-based: generate new samples by re-matching relevant questions for images:

2.6.3. Self-Supervised Contrastive Learning
①Gather similar sample pairs and push dissimilars away
②Loss:
where 's are weights,
is the scoring function between the anchor
and the positive sample
/ negative sample
,
is augmented data,
is the index of the answer
③Schematic of this method:
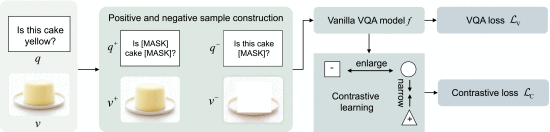
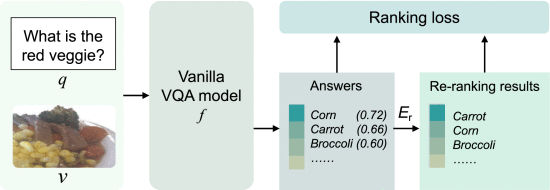
2.6.4. Answer Re-Ranking
①Process:
2.7. Exploring the Robustness of Vision-Language Models for VQA
①Single-stream and dual-stream VLM:
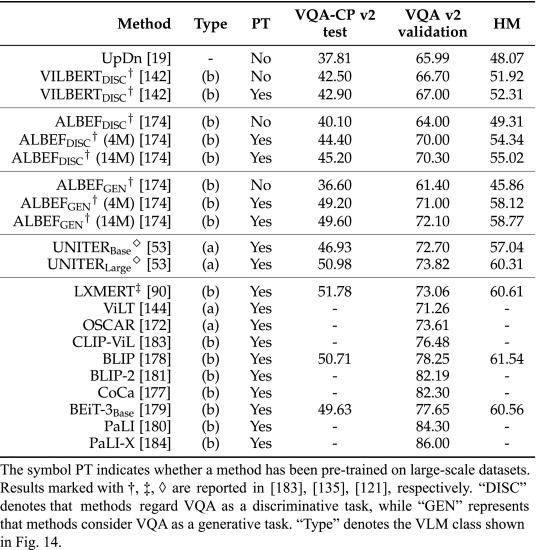
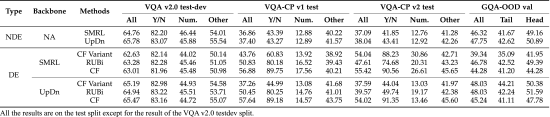
②VQA Results of VLMs in ID and OOD Situations:
2.8. Discussions and Future Directions
①Limitations: more accurate annotations, ID/OOD tasks contained, metrics of multi-hop inference, accurate evaluation, robust debiasing methods
②Robust evaluation:
2.9. Conclusion
~
3. Reference
@ARTICLE{10438044,
author={Ma, Jie and Wang, Pinghui and Kong, Dechen and Wang, Zewei and Liu, Jun and Pei, Hongbin and Zhao, Junzhou},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={Robust Visual Question Answering: Datasets, Methods, and Future Challenges},
year={2024},
volume={46},
number={8},
pages={5575-5594},
keywords={Sports;Task analysis;Robustness;Transformers;Training;Question answering (information retrieval);Knowledge engineering;Vision-and-language pre-training;bias learning;debiasing;multi-modality learning;visual question answering},
doi={10.1109/TPAMI.2024.3366154}}

















 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









