



前瞻
调用大模型并本地化部署非代码操作上需要获取API的url地址以及API的key密钥
常见可选的大模型包括:
OpenAI GPT系列
LLaMA (Meta)
Claude (Anthropic)
国内大模型如文心一言、通义千问等
这里以deepseek为例进行演示,同时将获取的全过程进行简要展示
获取API
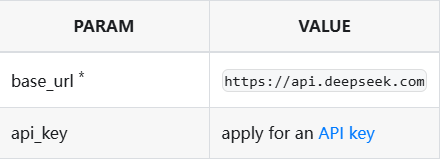
我们要获取某一模型的API,首先是可以从官网的提供的API,如deepseek的doc内容中
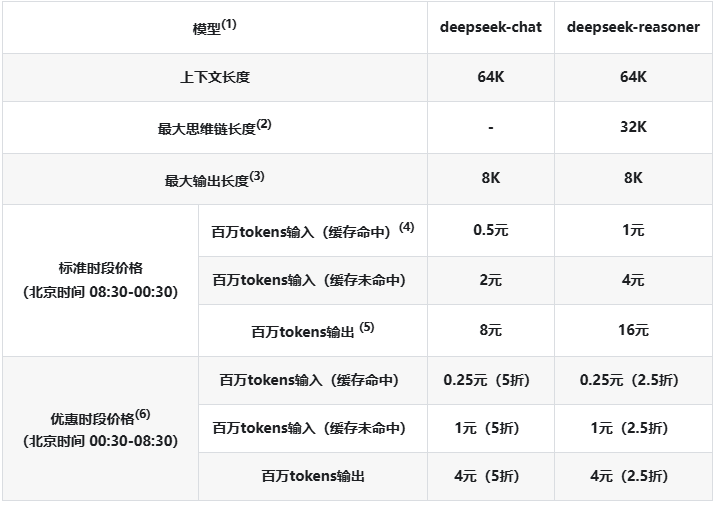
本地部署会根据耗费token数量进行一定程度扣费:
但由于deepseek的官网并未为民间公开获取API的key密钥的方式,因此我们可以用以下方法进行获取:
华为云ModelArts
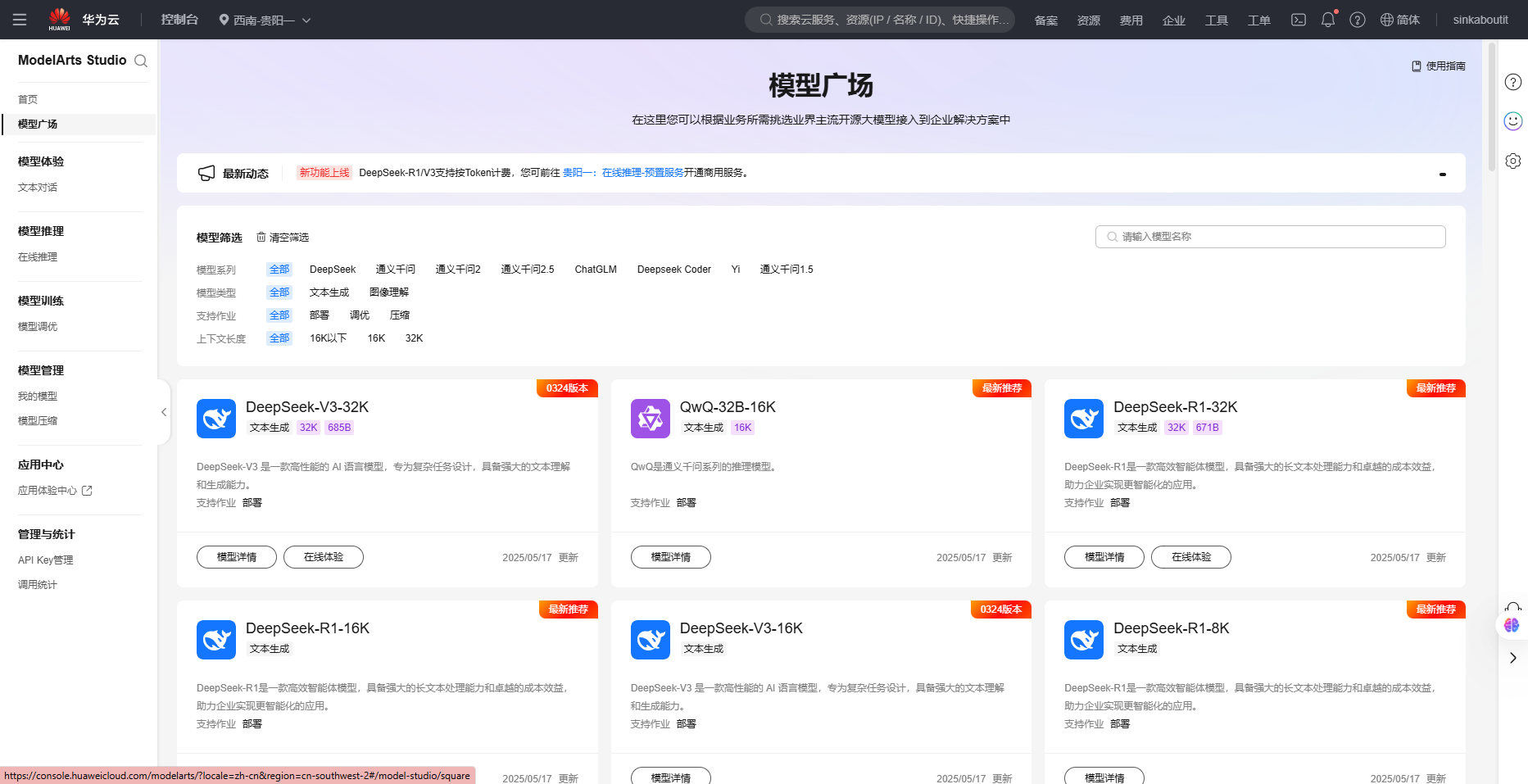
选择一种模型进入详细并部署,部署成功后点击左侧在线推理将展示现待使用的模型:
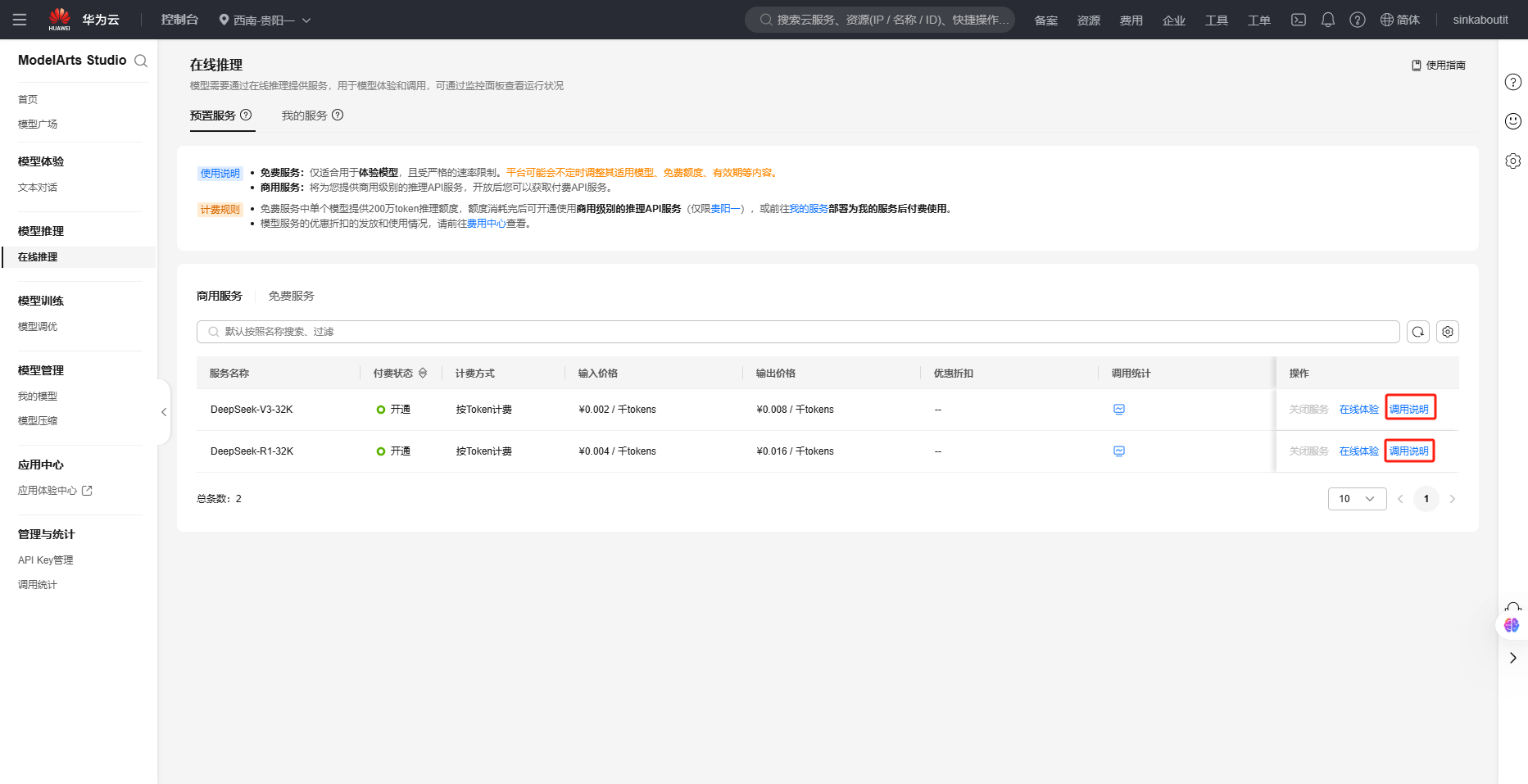 选择这里的调用说明,将会呈现相应的API的url,若未预设API的密钥根据提示先去配置key
选择这里的调用说明,将会呈现相应的API的url,若未预设API的密钥根据提示先去配置key
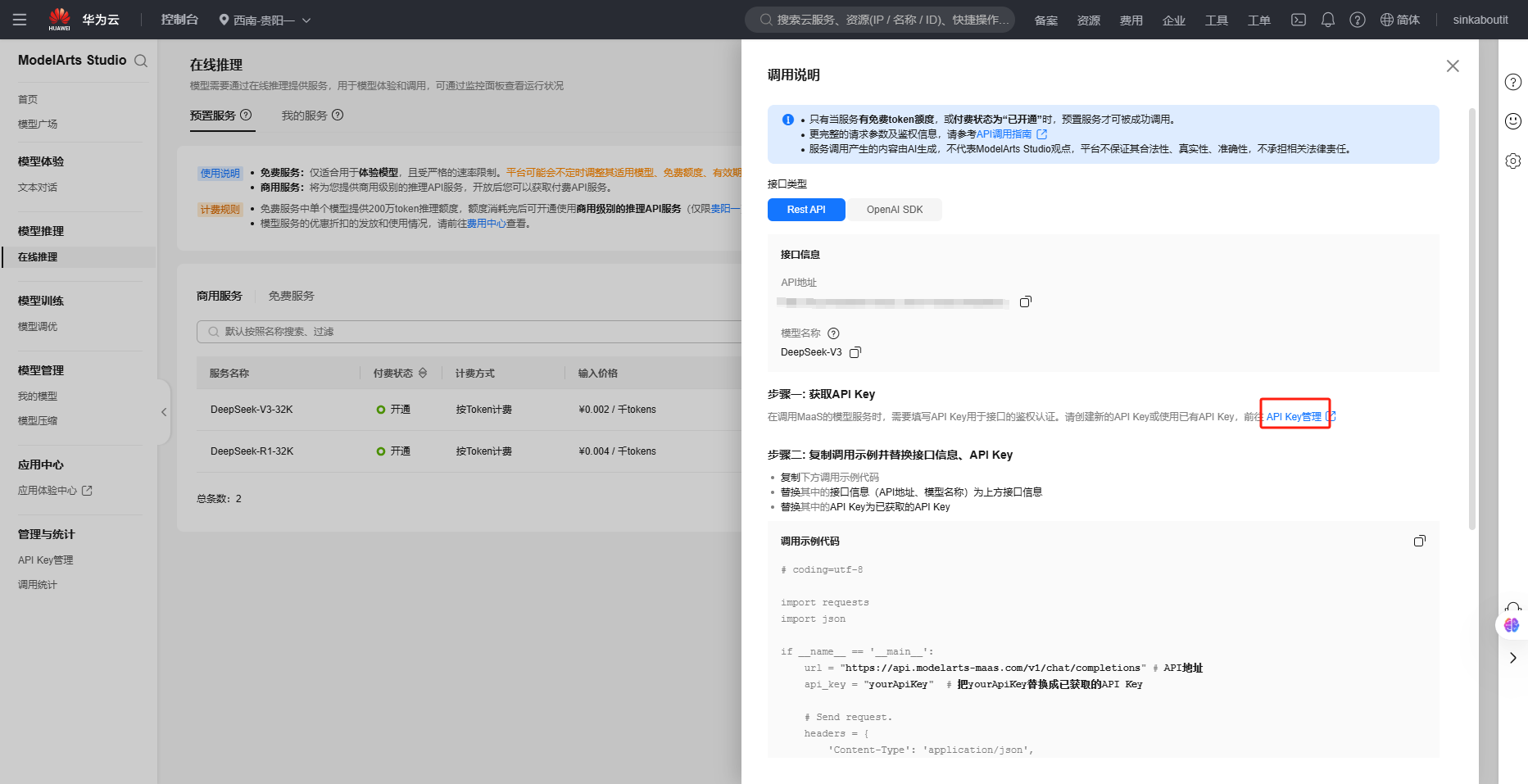
若API的url与key皆已获取,可以尝试以下代码验证是否可以正常使用
# coding=utf-8
import requests
import json
if __name__ == '__main__':
url = "yourURL" # API地址
api_key = "yourApiKey" # 把yourApiKey替换成已获取的API Key
# Send request.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model": "DeepSeek-V3", # 模型名称
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好"}
],
# 是否开启流式推理, 默认为False, 表示不开启流式推理
"stream": True,
# 在流式输出时是否展示使用的token数目。只有当stream为True时改参数才会生效。
# "stream_options": { "include_usage": True },
# 控制采样随机性的浮点数,值较低时模型更具确定性,值较高时模型更具创造性。"0"表示贪婪取样。默认为0.6。
"temperature": 0.6
}
response = requests.post(url, headers=headers, data=json.dumps(data), verify=False)
# Print result.
print(response.status_code)
print(response.text)

若出现此问题,请检查API的key或是url是否正确。
通义千文中获取deepseekAPI
百炼控制台![]() https://bailian.console.aliyun.com/?spm=a2c4g.11186623.0.0.7fb960e99VtQeN&tab=model#/api-key
https://bailian.console.aliyun.com/?spm=a2c4g.11186623.0.0.7fb960e99VtQeN&tab=model#/api-key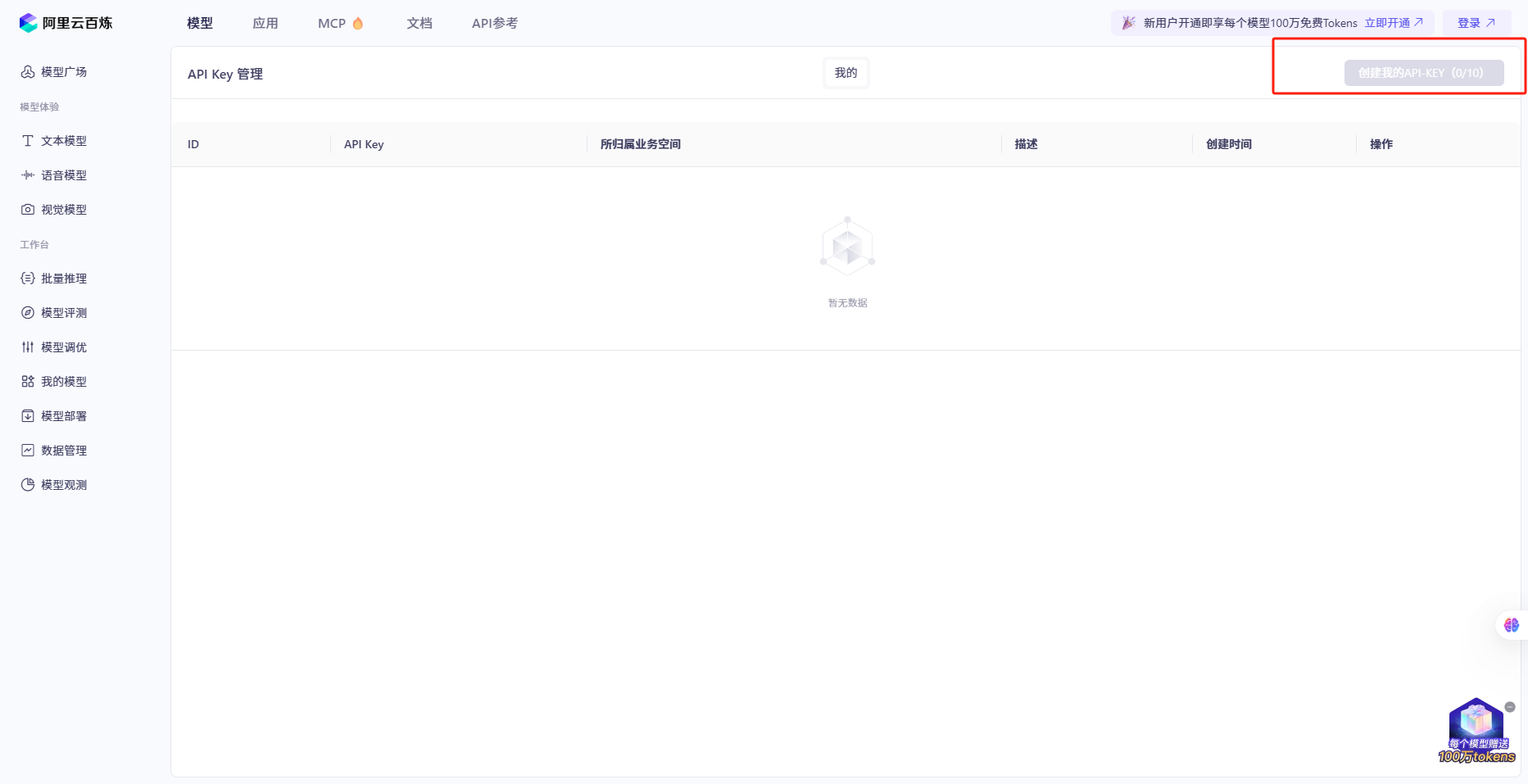
首先获取API的密钥key
获取完毕后需要将API密钥配置到环境变量,这里以Windows系统进行演示
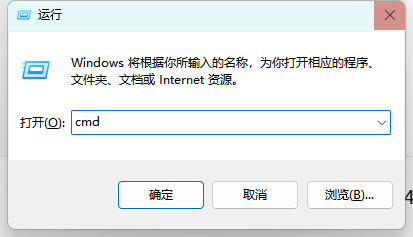
使用win+R后输入cmd进入终端,输入以下命令:
# 用您的百炼API Key代替YOUR_DASHSCOPE_API_KEY
setx DASHSCOPE_API_KEY "YOUR_DASHSCOPE_API_KEY"届时,将YOUR_DASHSCOPE_API_KEY换为自己获取的API密钥。配置完毕
阿里云百炼官方提供了 Python 与 Java 编程语言的 SDK,也提供了与 OpenAI 兼容的调用方式(OpenAI 官方提供了 Python、Node.js、Java、Go 等 SDK)。本文为您介绍如何安装 OpenAI SDK
通过运行以下命令安装OpenAI Python SDK:
# 如果运行失败,您可以将pip替换成pip3再运行
pip install -U openai以下将您可以通过 OpenAI SDK 兼容的HTTP方式快速体验DeepSeek模型。
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
completion = client.chat.completions.create(
model="deepseek-r1", # 此处以 deepseek-r1 为例,可按需更换模型名称。
messages=[
{'role': 'user', 'content': '9.9和9.11谁大'}
]
)
# 通过reasoning_content字段打印思考过程
print("思考过程:")
print(completion.choices[0].message.reasoning_content)
# 通过content字段打印最终答案
print("最终答案:")
print(completion.choices[0].message.content)这里的url可以直接使用代码中的地址,但API的key需要配置成自己所创设的密钥。这里模型以deepseekR1为例:
返回结果:
思考过程:
嗯,用户问的是9.9和9.11谁大。首先,我需要确认这两个数字的数值到底是多少。表面上看起来都是小数,但可能用户有不同的表示方式需要注意。
首先,9.9应该就是平常的小数,也就是9加9/10,等于9.9。而9.11可能有两种解读:一种是直接的小数,即9加11/100,也就是9.11;另一种可能是版本号或者某种编号,比如软件版本中的9.9和9.11,这时候可能需要按顺序比较,比如9.9之后是9.10,再是9.11,所以9.11会比9.9大。不过通常情况下,数学问题中的数字还是按照数值来比较的,所以应该排除版本号的解释,直接比较数值大小。
...
总结一下,正确的数值比较中,9.9等于9.90,而9.11等于9.11,所以9.90大于9.11,也就是9.9大于9.11。不过为了避免混淆,可能用户需要更详细的步骤解释。
最终答案:
9.9比9.11大。
**详细比较步骤:**
1. **统一小数位数**:将9.9写成9.90,使其与9.11的小数位数一致。
2. **逐位比较**:
- **整数部分**:两者均为9,相等。
- **小数部分**:比较0.90(9.9的小数部分)和0.11(9.11的小数部分)。由于0.90 > 0.11,因此9.90 > 9.11。
**结论**:9.9的数值大于9.11。
若涉及版本号(如软件版本),通常按顺序排列为9.9 → 9.10 → 9.11,此时9.11较新。但按纯数学数值比较,9.9更大。常见问题
在调用API若未能成功进行预期效果,则一般会报出以下问题:
1. 400 Bad Request(错误请求)
-
原因:请求语法错误、参数缺失或格式无效(如JSON解析失败)。
-
示例:
-
缺少必填字段。
-
提交的数据类型错误(如传字符串而非数字)。
-
2. 401 Unauthorized(未授权)
-
原因:缺少或无效的身份验证凭证(如Token、API Key)。
-
与403的区别:401表示“未认证”,403表示“已认证但无权访问”。
3. 403 Forbidden(禁止访问)
-
原因:身份验证通过,但权限不足(如普通用户访问管理员接口)。
-
常见场景:
-
IP被拉黑。
-
文件/目录权限限制。
-
4. 404 Not Found(资源不存在)
-
原因:请求的资源未找到(如URL路径错误、资源已删除)。
-
注意:有时API故意返回404以隐藏敏感资源(避免暴露403)。
5. 405 Method Not Allowed(方法不允许)
-
原因:HTTP方法不被支持(如用POST访问只允许GET的接口)。
-
解决方案:检查API文档,确认支持的请求方法(GET/POST/PUT等)。
6. 406 Not Acceptable(无法接受)
-
原因:服务器无法返回客户端要求的响应格式(如请求
Accept: application/xml,但API仅支持JSON)。
7. 408 Request Timeout(请求超时)
-
原因:服务器等待请求时间过长(如网络延迟或客户端未及时发送数据)。
-
常见场景:大文件上传时超时。
8. 409 Conflict(冲突)
-
原因:请求与服务器当前状态冲突(如重复创建同一资源)。
-
示例:
-
并发修改同一数据导致版本冲突(如Git合并冲突)。
-
注册已存在的用户名。
-
9. 410 Gone(资源已永久删除)
-
原因:资源曾存在,但已被永久删除(比404更明确)。
-
与404的区别:410明确告知资源不可恢复,404可能是临时不存在。
10. 413 Payload Too Large(请求体过大)
-
原因:请求数据超过服务器限制(如上传文件大小超限)。
-
解决方案:检查服务器的
max_body_size配置。
11. 414 URI Too Long(URL过长)
-
原因:请求的URL超出服务器限制(如GET请求携带过多参数)。
-
解决方案:改用POST传递参数。
12. 415 Unsupported Media Type(不支持的媒体类型)
-
原因:请求的Content-Type不被支持(如服务器仅接受JSON,但客户端发送XML)。
-
示例:
-
未设置
Content-Type: application/json。
-
13. 429 Too Many Requests(请求过多)
-
原因:触发了API的速率限制(Rate Limiting)。
-
解决方案:降低请求频率或联系API提供商调整配额。
14. 451 Unavailable For Legal Reasons(因法律原因不可用)
-
原因:因法律要求拒绝访问(如政府审查的内容)。
-
参考:HTTP标准扩展状态码,源自小说《华氏451度》。

















 1441
1441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









