








RT-DETR使用教程: RT-DETR使用教程
RT-DETR改进汇总贴:RT-DETR更新汇总贴
《FCMNet: Frequency-aware cross-modality attention networks for RGB-D salient object detection》
一、 模块介绍
论文链接:https://www.sciencedirect.com/science/article/pii/S0925231222003848
代码链接:https://github.com/XiaoJinNK/FCMNet/tree/main
论文速览:
RGB-D显著性检测旨在全面利用RGB图像和深度图来检测物体的显著性。这一领域仍然面临着两个挑战:1) 如何提取具有代表性的多模态特征;2) 如何有效地将它们融合在一起。该领域的大多数先前方法都将RGB和深度信息作为两种模态来同等对待,而没有考虑两种模态在频域上的差异,可能会丢失一些互补信息。在这篇论文中,我们将频率通道注意力机制引入融合过程。首先,我们设计了一个频率感知跨模态注意力(FACMA)模块,以交织适当的通道特征并选择代表性特征。在FACMA模块中,我们还提出了一个空间频率通道注意力(SFCA)模块,以在不同通道中引入更多互补信息。其次,我们开发了一个加权跨模态融合(WCMF)模块,通过学习内容相关的权重映射来自适应融合多模态特征。
总结:文中提出FACMA、SFCA、WCMF三种模块,其中加权跨模态融合WCMF可用于平替concat模块。
⭐⭐本文二创模块仅更新于付费群中,往期免费教程可看下方链接⭐⭐
RT-DETR更新汇总贴(含免费教程)文章浏览阅读264次。RT-DETR使用教程:缝合教程: RT-DETR中的yaml文件详解:labelimg使用教程:_rt-deterhttps://xy2668825911.blog.csdn.net/article/details/143696113 ⭐⭐付费项目简介:融合上百种顶刊顶会模块的YOLO项目仅119,此外含高性能自研模型与本文模块融合进行二创三创,最快1-2周完成小论文改进实验,代码每周更新(上周更新超20+二创模块),欢迎QQ:2668825911(点击下方小卡片扫二维码)加我了解。⭐⭐
⭐⭐本项目并非简单的模块插入,平均每个文章对应4-6个二创或自研融合模块,有效果即可写论文或三创。本文项目使用ultralytics框架,兼容YOLOv3\5\6\8\9\10\world与RT-DETR。⭐⭐

已进群小伙伴可以先用下文二创及自研模块在自己的数据集上测试,有效果再进行模块结构分析或继续改进。
二、二创融合模块
2.1 相关二创模块及所需参数
-
2.2 更改yaml文件 (以自研模型加入为例)
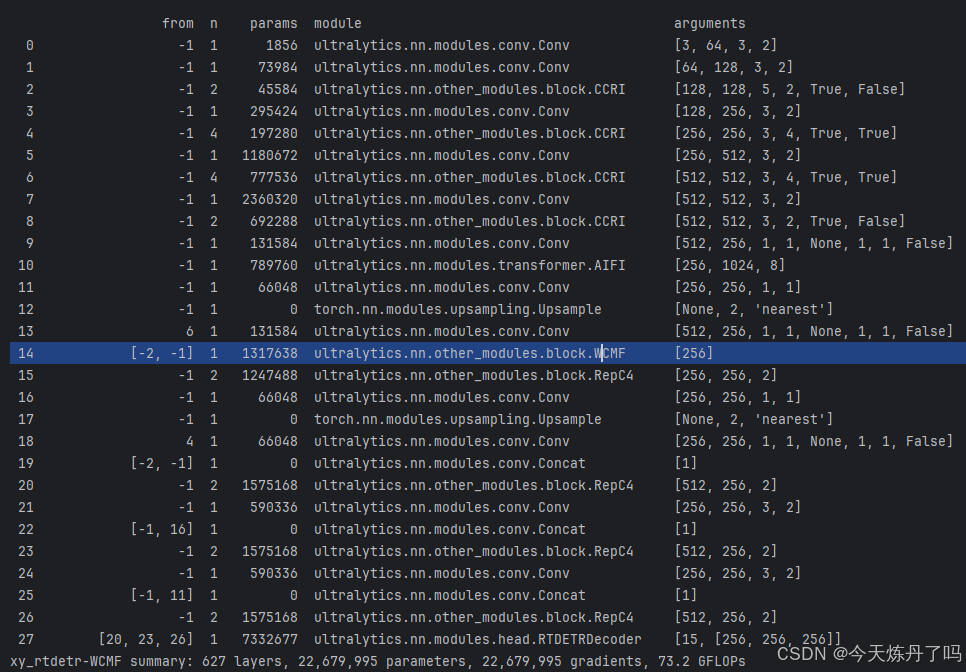
打开更改ultralytics/cfg/models/rt-detr路径下的rtdetr-l.yaml文件,替换原有模块。

# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# ⭐⭐Powered by https://blog.csdn.net/StopAndGoyyy, 技术指导QQ:2668825911⭐⭐
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 512]
# n: [ 0.33, 0.25, 1024 ]
# s: [ 0.33, 0.50, 1024 ]
# m: [ 0.67, 0.75, 768 ]
# l: [ 1.00, 1.00, 512 ]
# x: [ 1.00, 1.25, 512 ]
# ⭐⭐Powered by https://blog.csdn.net/StopAndGoyyy, 技术指导QQ:2668825911⭐⭐
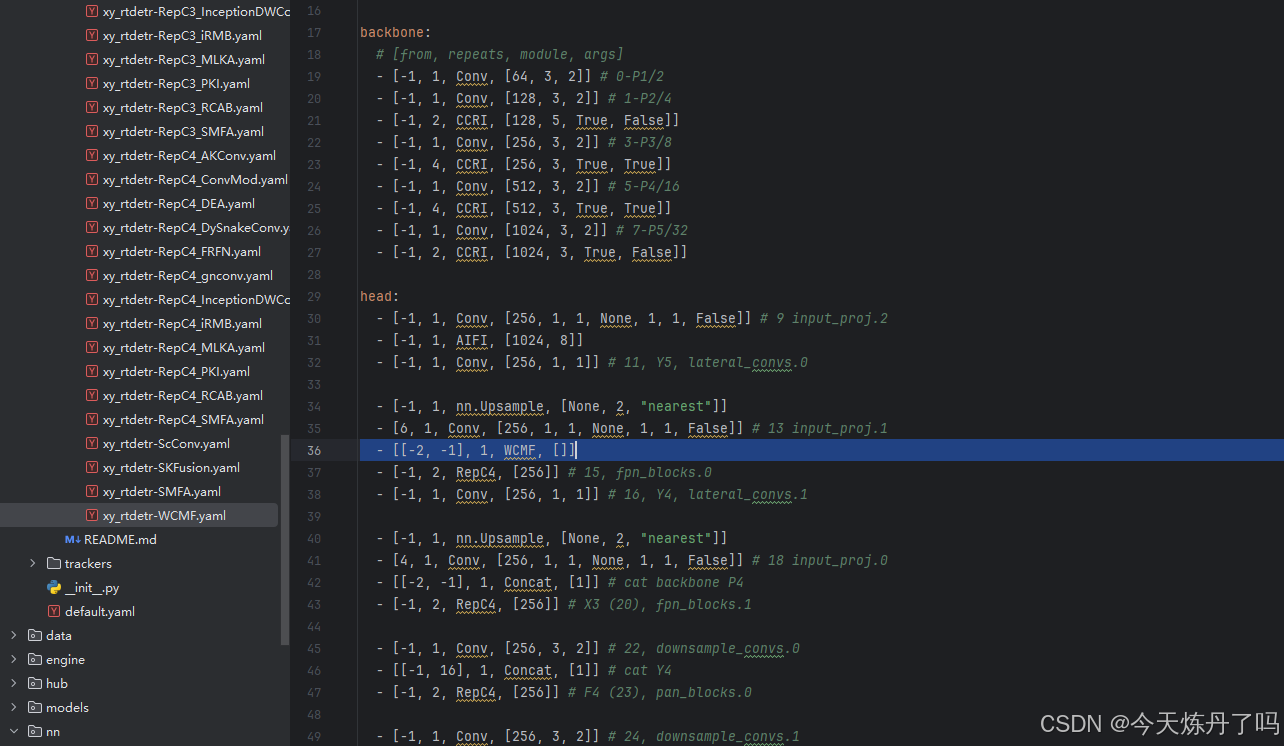
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, CCRI, [128, 5, True, False]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 4, CCRI, [256, 3, True, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 4, CCRI, [512, 3, True, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, CCRI, [1024, 3, True, False]]
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 9 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 11, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [6, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 13 input_proj.1
- [[-2, -1], 1, WCMF, []]
- [-1, 2, RepC4, [256]] # 15, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 16, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [4, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 18 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 2, RepC4, [256]] # X3 (20), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 22, downsample_convs.0
- [[-1, 16], 1, Concat, [1]] # cat Y4
- [-1, 2, RepC4, [256]] # F4 (23), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 24, downsample_convs.1
- [[-1, 11], 1, Concat, [1]] # cat Y5
- [-1, 2, RepC4, [256]] # F5 (26), pan_blocks.1
- [[20, 23, 26], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
# ⭐⭐Powered by https://blog.csdn.net/StopAndGoyyy, 技术指导QQ:2668825911⭐⭐
2.2 修改train.py文件
创建Train_RT脚本用于训练。
from ultralytics.models import RTDETR
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
if __name__ == '__main__':
model = RTDETR(model='ultralytics/cfg/models/rt-detr/rtdetr-l.yaml')
# model.load('yolov8n.pt')
model.train(data='./data.yaml', epochs=2, batch=1, device='0', imgsz=640, workers=2, cache=False,
amp=True, mosaic=False, project='runs/train', name='exp')

在train.py脚本中填入修改好的yaml路径,运行即可训。


















 2910
2910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









