







数据
使用数据集courses.txt
读取数据
import pandas as pd
# 导入文本文件,原数据集是使用逗号分割的,第一行为列名
courses_ori = pd.read_csv('courses.txt', sep=',', header=0)
# 预览 DataFrame 前 5 行
courses_ori.head()
数据中有时间列,做时间序列分析。将时间列变为索引列
#时间数据变为 DatetimeIndex 格式,这样时间列就可以作为索引
i = pd.to_datetime(courses_ori['创建时间'])
i.head()
#给原始数据 courses_ori 加上时间戳索引
courses_ts = pd.DataFrame(data=courses_ori.values,
columns=courses_ori.columns, index=i)
courses_ts.head()
#去除原来的时间列
courses_ts = courses_ts.drop("创建时间", axis=1)
courses_ts.head()
可视化
查看学习人数和学习时间随着时间变化的趋势,进行绘图,时间太多,对时间序列降采样
# 按照周次频率进行降采样
courses_ts_W = courses_ts.resample('W').sum()
courses_ts_W.head()
#再使用 Matplotlib 对学习时间随着时间变化的趋势进行绘折线图
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(10, 3))
plt.plot(courses_ts_W.index, courses_ts_W['学习时间'], '-')
plt.xlabel('Time Series')
plt.ylabel("Study Time")
#上图不够清晰反映变化趋势,引入另一个绘图库 Seaborn
#使用 Seaborn 提供的 regplot 方法,它可以在绘制散点图时,对数据自动进行回归拟合。
import seaborn as sns
# 新添加一个序数列,方便绘制散点图
courses_ts_W['id'] = range(0, len(courses_ts_W.index.values))
plt.figure(figsize=(10, 3))
#用索引列和"学习时间"绘图会报错
sns.regplot("id", "学习时间", data=courses_ts_W, scatter_kws={
"s": 10}, order=8, ci=None, truncate=True)
plt.xlabel('Time Series')
plt.ylabel("Study Time")
图示要比上面折线图要好,但也有些问题
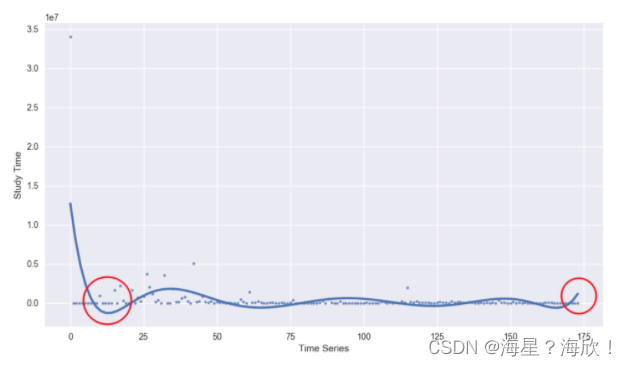
一开始数据向下凹的厉害,以及最后的翘尾。可能因为在一开始的时间上新增课程较少。而尾部的上翘,应归结于拟合偏差,你可以通过减小 order= 参数的数值,来降低这种偏差。
#通过设置 x_bins= 参数,绘制出能更加直观反映上升或下降趋势的图像
sns.regplot("id", "学习人数", data=courses_ts_W, x_bins=10)
plt.xlabel('Time Series')
plt.ylabel("Study Time")
数据分析
已知每门课程的总学习时间和学习人数,可以计算每个人的平均学习时间。
# 每次做单独分析时,最好复制一份整理好的数据,减少对原数据集影响
courses_ts_A = courses_ts.copy()
# 计算平均学习时间并添加列
courses_ts_A['平均学习时间'] = courses_ts_A['学习时间']/courses_ts_A['学习人数']
courses_ts_A.head() # 预览
#依据平均时间对数据集进行排序
courses_ts_A.sort_values(by='平均学习时间', ascending=False).head()
courses_ts_A.sort_values(by='平均学习时间', ascending=False).tail()
#查看排名前几和后几的课程后,尝试分析一下原因
#分析一下一些特殊的课程,学习人数偏多,但平均时间明显偏少的课程
# 添加新列
courses_ts_A['平均学习时间/人数'] = courses_ts_A['平均学习时间']/courses_ts_A['学习人数']
# 按照比值从小到大排序并显示前 10 条
courses_ts_A.sort_values(by='平均学习时间/人数').head(10) #升序排列
#这些课程的特点是大量人点进去学习,但学习时长不是很长,可能是课程难度大没法坚持下去
#绘制出平均学习时间和学习人数的关系图
plt.scatter(courses_ts_A["平均学习时间"], courses_ts_A["学习人数"])
plt.xlabel('Average Study Time')
plt.ylabel("Number of Users")
#重点关注靠近坐标轴的课程
聚类分析
由于数据特征很少,考虑进行数据挖掘。课程名称中包含许多关键词,进行名称分词。
在中文分词方面,比较好的开源工具有 jieba,Yaha,Genius 等。这里,我们使用 jieba 分词来针对课程名称进行处理。
# 导入 jieba 分词模块
from jieba import analyse
a = []
for i in courses_ts_A['课程名称']:
# 使用 jieba 分词并使用 TF-IDF 算法抽取两个关键词,仅返回英文、名词、动词、动名词
a.append(analyse.extract_tags(i, topK=2, withWeight=False,
allowPOS=('eng', 'n', 'vn', 'v')))
keywords = pd.DataFrame(a, columns=['关键词 1', '关键词 2'])
keywords.head()
# 复制一份数据集用于聚类
courses_ts_C = courses_ts_A.copy()
# 重置索引方便数据集拼接,加上索引列
courses_ts_C = courses_ts_C.reset_index()
# 将复制数据集与关键词数据集拼接,并删掉时间列
courses_ts_merged = pd.concat(
[courses_ts_C, keywords], axis=1).drop("创建时间", axis=1)
# 预览合并后数据集
courses_ts_merged.head()
#为了方便聚类,我们这里针对关键词进行独热编码处理
# 针对关键词进行独热编码处理
onehot = pd.get_dummies(courses_ts_merged[['关键词 1', '关键词 2']])
# 预览
onehot.head()
#由于分词产生的不相同词组太多,此处的独热编码返回了多达 527 列的特征。
#527 列的特征已经超过了数据集的 484 行。在这类小规模数据集上,非常不推荐使用过多的特征。所以,我们采用PCA 降维对特征进行降维
from sklearn.decomposition import PCA
# 将特征缩小至 5 维
pca = PCA(n_components=5)
# 返回降维后的值
feature_pca = pca.fit_transform(onehot)
feature_pca.shape
采用K-Means 算法开始聚类
#先计算轮廓系数,然后确定 K 值
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 建立模型
score = []
# 依次轮廓系数
for i in range(10):
model = KMeans(n_clusters=i+2)
model.fit(feature_pca)
score.append(silhouette_score(feature_pca, model.labels_))
# 轮廓系数绘图
plt.plot(range(2, 12, 1), score)
#从轮廓系数反映的图像来看,应该选定 K=6,即将课程聚为 6 类
# 执行聚类
model = KMeans(n_clusters=6)
model.fit(feature_pca)
# 将类别列添加到数据集中
courses_ts_final = pd.concat(
[courses_ts_merged, pd.Series(model.labels_, name='类别')], axis=1)
# 依照类别排序并预览数据
courses_ts_final.sort_values(by='类别', ascending=False)
#类别0非常杂乱,其他类别聚合效果比较好。可能原因在于1,类别设定少,2,关键词处理有待更加精确















 2898
2898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









