






本文提出了一种名为**溯因反思(Abductive Reflection, ABL-Refl)**的方法,旨在解决神经符号(Neuro-Symbolic, NeSy)人工智能中神经网络输出与领域知识不一致的问题。该方法受到人类认知反思机制的启发,通过在训练过程中引入一个“反思向量”,快速检测神经网络输出中的潜在错误,并调用符号推理进行修正,从而生成与领域知识一致的输出。
研究背景与动机
神经符号人工智能结合了神经网络的快速模式识别能力(类似人类的直觉系统)和符号推理的逻辑性(类似人类的理性系统)。然而,现有方法在处理复杂任务时,神经网络的输出常常与领域知识不一致,导致推理结果不可靠。此外,以往的神经符号方法在整合神经网络和符号推理时,往往牺牲了符号推理的完整性,导致推理效率低下或难以扩展到大规模问题。
溯因反思(ABL-Refl)的核心思想
ABL-Refl 基于溯因学习(Abductive Learning, ABL)框架,通过以下方式改进神经符号推理:
-
反思向量:在神经网络输出的同时生成一个二值向量,标记可能与领域知识不一致的输出位置。
-
符号推理修正:利用符号推理对被标记的位置进行修正,生成符合领域知识的最终输出。
-
高效训练:通过无监督学习从领域知识中直接生成反思向量,避免了以往方法中复杂的组合优化步骤,显著提高了推理效率。
方法优势
-
高效性:ABL-Refl 通过减少符号推理的搜索空间,显著降低了推理时间,同时保持了高准确率。
-
多功能性:该方法能够处理多种类型的数据(如符号、图像、图数据)和不同形式的领域知识(如命题逻辑、一阶逻辑、数学公式)。
-
资源节约:在实验中,ABL-Refl 显著减少了训练时间,并且在标记数据有限的情况下仍能保持高准确率。
实验验证
作者通过以下实验验证了 ABL-Refl 的有效性:
-
数独问题:在符号和视觉形式的数独任务中,ABL-Refl 的准确率显著高于现有方法,同时推理时间更短。
-
图组合优化问题:在寻找最大团和最大独立集的任务中,ABL-Refl 在多个数据集上实现了接近完美的结果,优于其他神经符号方法。
-
与符号求解器的比较:与仅使用符号求解器的方法相比,ABL-Refl 通过缩小搜索空间,显著加速了推理过程。
结论
ABL-Refl 通过引入反思机制,有效地解决了神经符号推理中的不一致性问题,同时在效率和准确性上优于现有方法。该方法在多种任务和数据类型上的成功应用表明其具有广泛的应用潜力,未来可以扩展到更复杂的场景,如大型语言模型的输出修正。
研究贡献
-
提出了一种新的神经符号推理框架,解决了神经网络输出与领域知识不一致的问题。
-
通过引入反思向量,显著提高了推理效率,同时保留了符号推理的完整性。
-
在多个基准任务上验证了方法的有效性,展示了其在不同数据类型和领域知识形式上的适用性。
这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
神经符号(NeSy)人工智能可以类比于人类的双重加工认知,用神经网络模拟直觉化的系统1,用符号推理模拟算法化的系统2。然而,对于复杂的任务目标,NeSy系统常常会产生与领域知识不一致的输出,且修正这些输出是一个挑战。受人类认知反思的启发,这种反思能够快速检测我们直觉反应中的错误,并通过调用系统2的推理来修正这些错误,我们提出通过基于溯因学习(Abductive Learning, ABL)框架的溯因反思(Abductive Reflection, ABL-Refl)来改进NeSy系统。ABL-Refl利用领域知识在训练过程中溯因出一个反思向量,该向量可以在推理过程中标记神经网络输出中潜在的错误,并调用溯因来修正这些错误,从而生成与领域知识一致的输出。与以往的ABL实现相比,ABL-Refl具有更高的效率。实验表明,ABL-Refl优于现有的NeSy方法,在使用更少的训练资源和更高的效率的同时,能够实现卓越的准确率。
1. 引言
人类决策通常被认为是两个系统之间的交互:系统1快速生成直觉反应,系统2进行进一步的算法化和缓慢推理(Frederick 2005;Kahneman 2011)。在神经符号(NeSy)人工智能中,神经网络通常类似于系统1,用于快速模式识别,符号推理则类似于系统2,利用领域知识并以一种更缓慢、更可控的方式处理复杂问题(Bengio 2019)。然而,与人类系统1的推理类似,神经网络在面对复杂任务时常常会产生不可靠的输出,导致与领域知识的不一致。这些不一致可以通过符号推理的对应部分来调和(Hitzler 2022)。为了实现上述过程,一些方法将符号领域知识放松为神经网络的约束(Xu et al. 2018;Yang, Lee, 和 Park 2022),一些方法尝试在神经网络中通过分布式表示近似逻辑演算(Wang et al. 2019)。然而,在这些放松或近似过程中,往往会失去完整的符号推理能力,从而阻碍了可靠输出的生成。溯因学习(Abductive Learning, ABL)(Zhou 2019;Zhou 和 Huang 2022)是一个在保留每一方完整表达能力的同时,连接机器学习和逻辑推理的框架。在ABL中,机器学习组件首先将原始数据转换为原始符号输出,这些输出可以被符号推理组件利用,后者利用领域知识并执行溯因以生成更可靠、经过修订的输出。然而,以往的ABL实现需要在应用溯因之前进行高度离散的组合一致性优化,这种优化的复杂性很高,从而严重限制了其在大规模场景中的效率和适用性。人类推理自然地高效利用这两者,一个假设性的模型被称为认知反思,快速的系统1思维被用来快速生成一个大致的解决方案,然后无缝地将复杂部分交给系统2(Frederick 2005)。这一过程的关键在于反思机制,它能够及时检测直觉反应中可能与领域知识不一致的部分,并调用系统2来修正这些错误。这种反思通常与系统2的能力密切相关,因为两者都与个体对领域知识的掌握密切相关(Sinayev 和 Peters 2015)。在反思之后,系统2的逐步形式推理过程变得不那么复杂:由于搜索空间大幅减少,为系统2推导出正确解决方案变得直接。受这一现象的启发,我们提出了一个通用的增强方法,即溯因反思(Abductive Reflection, ABL-Refl)。基于ABL框架,ABL-Refl保留了神经网络和符号推理的完整表达能力,同时用反思机制取代了耗时的一致性优化,从而显著提高了效率和适用性。具体而言,在ABL-Refl中,反思向量与神经网络的直觉输出同时生成,它标记输出中的潜在错误,并调用符号推理来执行溯因,从而修正这些错误并生成更符合领域知识的新输出。在模型训练过程中,反思的训练信息来自领域知识。本质上,反思向量是从领域知识中溯因而来的,它作为一种注意力机制,用于缩小符号推理的问题空间。反思可以无监督地进行训练,只需要与现有的NeSy系统相同数量的领域知识,而不需要生成额外的训练数据。我们在符号形式和视觉形式的数独NeSy基准测试中验证了ABL-Refl的有效性。与以往的NeSy方法相比,ABL-Refl表现显著更好,能够以更少的训练资源高效地实现更高的推理准确率。我们还将我们的方法与符号求解器进行了比较,并表明ABL-Refl中减少的搜索空间提高了推理效率。进一步的实验表明,ABL-Refl能够处理多种类型的数据,并在不同维度中利用不同形式的知识库。
2. 相关工作
最近,在增强神经网络的可靠符号推理方面取得了显著进展。一些方法使用可微分模糊逻辑(Serafini 和 Garcez 2016;Marra 等人 2020)或将符号领域知识放松为神经网络训练的约束(Xu 等人 2018;Yang, Lee 和 Park 2022;Hoernle 等人 2022;Ahmed 等人 2022),而另一些方法通过在神经网络中近似逻辑推理来学习约束(Amos 和 Kolter 2017;Selsam 等人 2018;Wang 等人 2019)。这些模型倾向于软化符号推理的要求,从而影响输出生成的可靠性。像 DeepProbLog(Manhaeve 等人 2018)和 NeurASP(Yang, Ishay 和 Lee 2020)这样的模型将神经网络的输出解释为符号分布,然后应用符号求解器,这带来了巨大的计算成本。溯因学习(Abductive Learning, ABL)(Zhou 2019;Zhou 和 Huang 2022)试图以一种平衡且相互支持的方式整合机器学习和逻辑推理。它具有一个易于使用的开源工具包(Huang 等人 2024),并有许多实际应用(Huang 等人 2020;Cai 等人 2021;Wang 等人 2021;Gao 等人 2024)。然而,一致性优化的复杂性很高。另一类与我们的研究相关的工作也遵循预测、错误识别和推理的类似过程(Nair 等人 2020;Nye 等人 2021;Han 等人 2023)。这些方法通常受限于狭窄的领域知识范围,局限于特定的数学问题,或者被限制在一个最小世界模型内。Cornelio 等人(2023)生成了一个选择模块来识别需要符号推理修正的错误。与他们的方法相比,我们的方法在模型训练过程中自动溯因出反思向量,而他们的方法需要提前准备大量的合成数据集。
3. 溯因反思
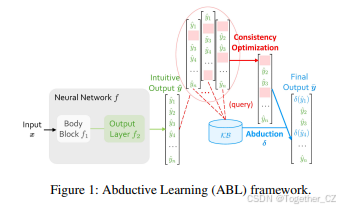
本节介绍问题设置和溯因反思(Abductive Reflection, ABL-Refl)方法。
3.1 问题设置
本文的主要任务如下:输入是原始数据 x,它可以是符号形式或次符号形式,目标输出是 y=[y1,y2,…,yn],其中每个 yi 是来自符号集合 Y 的符号,该集合包含所有可能的输出符号。我们假设拥有两个关键组件:神经网络 f 和领域知识库 KB。f 可以直接将 x 映射到 y,而 KB 包含 y 中符号之间的约束。KB 可以有多种形式,包括命题逻辑、一阶逻辑、数学或物理方程等,并且可以通过利用相应的符号求解器执行符号推理操作。输出 y 应遵循 KB 中的约束,否则它将不可避免地包含错误,导致与领域知识不一致和错误的推理结果。这种问题类型有广泛的应用。例如,它可以用于解决数独谜题,其中输出 y 由 81 个符号组成,来自集合 Y={1,2,…,9},而 KB 中的约束是数独的规则。它还可以应用于部署生成模型进行文本生成、基因预测、数学问题求解等,生成符合 KB 中复杂常识、生物学或数学逻辑的输出。
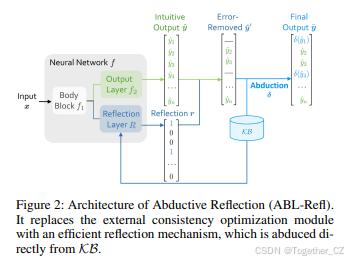
3.2 溯因学习简介

挑战。在以往的 ABL 中,一致性优化一直是计算瓶颈。它作为一个外部模块运行,使用零阶优化方法,独立于 f 和 KB(Dai 等人 2019;Zhou 和 Huang 2022)。对于每次推理,它涉及反复选择各种可能的位置,并查询 KB 以查看是否可以推断出一致的结果。每次查询都涉及调用 KB 进行缓慢的符号推理。此外,由于它是一个具有高度离散性质的复杂组合问题,随着数据规模的增加,所需的查询次数呈指数级增长。这种大量的查询导致时间消耗显著增加,因此将 ABL 的适用性限制在只有小数据集上,通常是输出维度 n 小于 10 的数据集。
3.3 架构

溯因而来的,直接利用领域知识中的信息(稍后在第 3.4 节讨论)。它可以被视为一种由神经网络生成的注意力机制,可以帮助快速将符号推理集中在它识别为错误的特定区域,从而大幅缩小刻意符号推理的问题空间(Zhang 等人 2020)。
优势。与以往的 ABL 实现相比,ABL-Refl 用反思机制取代了零阶一致性优化模块,以解决计算瓶颈问题。通过这种方式,减少了对大量查询 KB 的需求:在快速识别系统 1 输出中的不一致之处后,无论数据规模如何,只需要对 KB 进行一次调用,即可获得修正后且更一致的输出。另一个值得注意的是,在架构中,反思层直接连接到主体块,这有助于利用嵌入中的信息,并与原始数据建立更紧密的联系。因此,反思向量 r 在原始数据和领域知识之间建立了一个更直接、更紧密的桥梁。
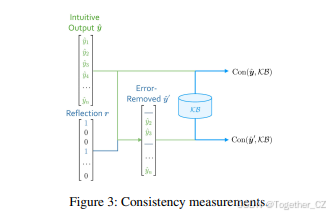
3.4 训练范式


4. 实验
在本节中,我们将进行几项实验。首先,我们将在解决数独的神经符号基准任务上测试我们的方法,以全面验证其有效性。接下来,我们将数独的输入从符号形式改为图像形式,这需要同时整合和推理符号与次符号元素,是该领域最具挑战性的任务之一。最后,我们将解决图上的组合优化问题,这些问题属于 NP-hard 问题,仅使用数学定义作为知识库,以展示我们方法的多功能性。通过这些实验,我们旨在回答以下问题:
Q1:与现有的神经符号学习方法相比,ABL-Refl 是否能在需要复杂推理的任务中实现更好的性能?
Q2:ABL-Refl 是否能减少所需的训练资源?
Q3:ABL-Refl 是否能缩小符号推理的问题空间以实现加速?
Q4:ABL-Refl 是否具备广泛的应用能力,例如处理多样化数据场景或各种形式的领域知识?
所有实验均在配备 Intel Xeon Gold 6226R CPU 和 Tesla A100 GPU 的服务器上进行。在我们的实验中,我们将超参数 α 和 β 在公式 (3) 中简单地设置为 1,因为调整它们对结果没有显著影响。对于公式 (2) 中的超参数 C,我们将其设置为 0.8,并在附录 C 中进行了讨论,表明将其设置在较宽的适中范围内(例如,0.6-0.9)始终是一个推荐的选择。所有实验均重复 5 次。
4.1 解决数独问题

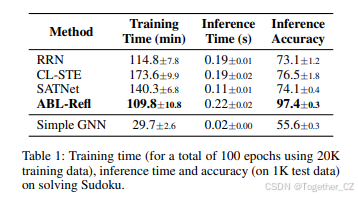
比较方法和结果。我们将 ABL-Refl 与以下基线方法进行比较:1)循环关系网络(Recurrent Relational Network, RRN)(Palm, Paquet, 和 Winther 2018),一种纯神经网络方法;2)CL-STE(Yang, Lee, 和 Park 2022),一种逻辑正则化损失的代表性方法;3)SATNet(Wang 等人 2019)。这些方法的详细描述在附录 A 中提供。我们还报告了简单 GNN 的结果,它与我们设置中使用的神经网络完全相同,但直接将直觉输出 y^ 视为最终输出。我们在表 1 中报告训练时间(使用 20K 训练数据进行 100 个 epoch 的总时间)、推理时间(在 1K 测试数据上)和准确率(测试数据上完全准确的数独解的百分比)。可以看出,我们的方法显著优于基线方法,准确率提高了 20% 以上,同时保持了相当的推理时间。这表明 ABL-Refl 能够实现更好的推理性能,主要归功于在推理过程中使用溯因修正神经网络的输出。此外,我们的方法仅需几个 epoch 就能达到高准确率(训练曲线见附录 B),显著减少了训练时间。即使在相同的训练 epoch 下,我们的总训练时间也少于基线方法,尽管我们的方法涉及了一个耗时的符号求解器。这在一定程度上源于我们方法中的神经网络比基线方法中的神经网络更简单,但仍然能够实现高准确率。总体而言,这表明 ABL-Refl 能够减少所需的训练时间。
| 方法 | 训练时间 (min) | 推理时间 (s) | 推理准确率 |
|---|---|---|---|
| RRN | 114.8±7.8 | 0.19±0.01 | 73.1±1.2 |
| CL-STE | 173.6±9.9 | 0.19±0.02 | 76.5±1.8 |
| SATNet | 140.3±6.8 | 0.11±0.01 | 74.1±0.4 |
| ABL-Refl | 109.8±10.8 | 0.22±0.02 | 97.4±0.3 |
| 简单 GNN | 29.7±2.6 | 0.02±0.00 | 55.6±0.3 |
表 1:在解决数独问题上的训练时间(使用 20K 训练数据进行 100 个 epoch)、推理时间(在 1K 测试数据上)和准确率。
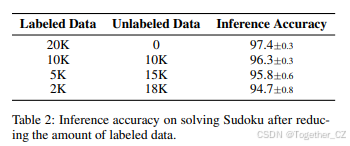
我们还尝试减少标记数据的数量,分别移除 50%、75% 和 90% 的训练数据标签。我们在表 2 中记录了推理准确率。可以看出,即使只有 2K 标记训练数据,我们的方法仍然比基线方法使用 20K 标记训练数据时的准确率高得多。这从另一个方面表明 ABL-Refl 能够减少所需的标记训练数据。
| 标记数据 | 未标记数据 | 推理准确率 |
|---|---|---|
| 20K | 0 | 97.4±0.3 |
| 10K | 10K | 96.3±0.3 |
| 5K | 15K | 95.8±0.6 |
| 2K | 18K | 94.7±0.8 |
表 2:在减少标记数据后解决数独问题的推理准确率。
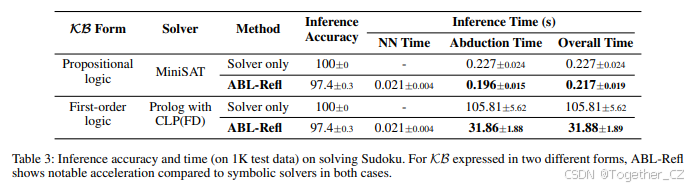
与符号求解器的比较。接下来,我们将我们的方法与从头开始仅使用符号求解器进行比较,以展示其加速符号推理的能力。我们在 1K 测试数据上进行推理,并记录准确率和时间,结果见表 3。从表中的前两行可以看出,我们的方法在溯因过程中显著加速,从而减少了整体推理时间,仅在准确性上略有妥协。这种效率提升的原因在于,在 ABL-Refl 中,通过神经网络快速生成直觉后,溯因只需要关注反射向量识别为必要的区域,而仅使用符号求解器则需要对数独中的所有空白进行推理。总体而言,这表明 ABL-Refl 能够快速生成反射,从而缩小符号推理的搜索空间,提高推理效率。我们还与 Prolog 的 CLP(FD) 求解器(Triska 2012)进行了比较,通过一阶约束逻辑程序表达相同的 KB。如表中所示,我们观察到溯因时间和整体推理时间显著减少,这进一步证明了我们之前对 Q3 的回答,并且也表明 ABL-Refl 能够有效利用符号知识表示中最常用的两种形式:命题逻辑和一阶逻辑。
| KB 形式 | 求解器 | 方法 | 推理准确率 | 推理时间 (s) |
|---|---|---|---|---|
| 命题逻辑 | MiniSAT | 求解器仅 | 100±0 | 0.227±0.024 |
| ABL-Refl | 97.4±0.3 | 0.217±0.019 | ||
| 一阶逻辑 | Prolog | 求解器仅 | 100±0 | 105.81±5.62 |
| ABL-Refl | 97.4±0.3 | 31.88±1.89 |
表 3:在解决数独问题上的推理准确率和时间(在 1K 测试数据上)。对于 KB 表达的两种不同形式,与符号求解器相比,ABL-Refl 显示出显著的加速效果。
4.2 解决视觉数独
数据集和设置。在本节中,我们将输入从 81 个符号数字改为 81 个 MNIST 图像(手写数字 0-9)。我们使用 SATNet(Wang 等人 2019)提供的数据集,并使用 9K 数独棋盘进行训练,1K 进行测试。为了处理图像数据,我们首先将每个图像通过 LeNet 卷积神经网络(CNN)(LeCun 等人 1998),以获得每个数字的概率。其余设置与第 4.1 节中描述的相同。
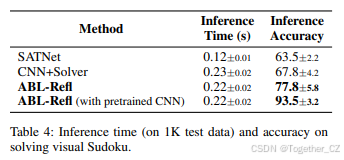
比较方法和结果。我们将 ABL-Refl 与 SATNet 进行比较,因为这两种方法都允许从视觉输入进行端到端训练。我们在表 4 中报告结果,并在附录 B 中提供训练曲线。与 SATNet 相比,ABL-Refl 在仅需几个训练 epoch 的情况下显示出显著的推理准确率提升。然后,我们考虑使用自监督学习方法(Chen 等人 2020)预先训练 CNN,发现这可以进一步提高准确率。总体而言,这些结果进一步支持了对 Q1 和 Q2 的积极回答。我们还与 CNN+求解器进行了比较:每个图像首先通过一个完全训练好的 CNN(在 MNIST 数据集上准确率为 99.6%)映射为符号形式,然后直接输入到符号求解器中以填充空白并得出最终输出。在这种情况下,符号求解器的问题空间包括数独中的所有空白,并且由于符号求解器无法修正 CNN 的错误,CNN 输出中的任何不准确都可能导致符号求解器崩溃(即,输出无解)。因此,推理准确率和时间受到不利影响。这证实了对 Q3 的积极回答。最后,第 4.1 节和第 4.2 节的概述也表明 ABL-Refl 能够处理符号和次符号形式的输入数据。
| 方法 | 推理时间 (s) | 推理准确率 |
|---|---|---|
| SATNet | 0.12±0.01 | 63.5±2.2 |
| CNN+求解器 | 0.23±0.02 | 67.8±4.2 |
| ABL-Refl | 0.22±0.02 | 77.8±5.8 |
| ABL-Refl(预训练 CNN) | 0.22±0.02 | 93.5±3.2 |
表 4:在解决视觉数独问题上的推理时间(在 1K 测试数据上)和准确率。
4.3 解决图上的组合优化问题
在本节中,我们将进一步扩展我们方法的应用领域。我们将 ABL-Refl 应用于解决图上的组合优化问题。我们在本节中进行的实验是寻找最大团,我们将在附录 E 中提供另一个实验。

比较方法和结果。我们将我们的方法与以下基线方法进行比较:1)Erdos(Karalias 和 Loukas 2020);2)Neural SFE(Karalias 等人 2022),这两种方法都是解决图组合问题的领先方法。它们的详细描述在附录 A 中提供。我们在表 5 中报告近似比率。近似比率表示结果集大小相对于实际最大集大小的比例,越接近 1 表示越好。我们可以看到,我们的方法优于基线方法,在所有数据集上都取得了接近完美的结果。这证实了对 Q1 的积极回答。此外,随着数据规模的增加,我们的方法保持了高准确率,并且与基线方法相比,改进更加显著。这表明 ABL-Refl 能够处理可扩展的数据场景,即使在对以往方法具有挑战性的高维设置中也能保持高效。最后,本节的总体概述从另一个方面证实了 Q4:ABL-Refl 能够利用广泛的知识库,不仅限于逻辑表达式,还可以有效利用基本的数学公式。
| 方法 | 数据集(图数量/平均每个图的节点数/平均每个图的边数) |
|---|---|
| ENZYMES (600/33/62) | 0.991±0.017 |
| PROTEINS (1113/39/73) | 0.985±0.020 |
| IMDB-Binary (1000/19/97) | 0.979±0.029 |
| COLLAB (5000/74/2457) | 0.982±0.015 |
5. 反思机制的效果
本节进一步分析反思机制的效果。在 ABL-Refl 中,反思是从领域知识中溯因而来的,并作为高效的注意力机制,引导符号搜索的焦点。这种反思是我们方法中实现神经符号推理修正流程的关键,即检测神经网络中的错误,然后调用符号推理来修正这些位置。为了验证反思的有效性,我们在第 4.2 节中提到的视觉数独任务上,将其与其他能够实现相同流程的方法进行了直接比较:1)ABL,通过外部零阶一致性优化模块最小化直觉输出与知识库之间的一致性;2)神经网络置信度,保留神经网络结果中置信度最高的 80% 的输出(还探索了其他保留阈值,见附录 D),并将剩余部分传递给符号推理;3)NASR(Cornelio 等人 2023),使用基于 Transformer 的外部选择模块来检测错误,该模块需要提前在大型合成数据集上进行训练。为了公平比较,所有方法都采用了相同的神经网络、KB 和 MiniSAT 求解器设置。我们在表 6 中报告了召回率(识别神经网络错误的百分比)、推理时间和准确率(在 1K 测试数据上)。需要注意的是,“召回率”直接评估检测模块本身的有效性。以下是对结果的分析:
-
ABL 中的一致性优化在大规模数据(输出维度 n=81)面前面临显著的效率挑战。在这种情况下,潜在的修正可能达到 281,从而导致一致性优化的搜索空间极为庞大。此外,作为一个外部模块,它与 KB 交互的唯一方式是将其视为黑箱,并反复提交一致性评估查询。因此,它可能需要超过 109 次查询来识别每个数独示例中的错误,导致在 1K 测试数据上完成推理需要数小时。
-
神经网络置信度在识别错误输出方面表现不佳。由于纯数据驱动的神经网络训练没有明确地整合 KB 信息,低置信度并不一定表示与领域知识的不一致。这随后导致符号求解器频繁崩溃,从而阻碍了整体的推理时间和准确率。这一结果与人类认知反思能力相呼应,后者与系统 1 的直觉没有太多正相关性(Pennycook 等人 2016)。为了进一步说明这一点,我们在附录 D 中提供了额外的分析,包括一个案例研究。
-
我们的方法还优于 NASR,值得注意的是,我们的方法不需要合成数据集。这可能是由于 NASR 的错误选择模块是独立于其他组件训练的,并且在推理过程中是顺序且单独运行的。因此,它只能依赖于输出标签的信息,而与我们的方法相比,我们的方法可以直接利用神经网络主体块的信息,与原始数据建立更紧密的联系。此外,在 NASR 中,遍历单独的选择模块需要额外的时间,而在 ABL-Refl 中,反思是与神经网络输出同时生成的,避免了效率损失。
| 方法 | 召回率 | 推理时间 (s) | 推理准确率 |
|---|---|---|---|
| ABL | 超时 | 超时 | 超时 |
| 神经网络置信度 | 82.64±2.78 | 0.24±0.03 | 64.3±6.2 |
| NASR | 95.86±0.96 | 0.26±0.02 | 82.7±4.4 |
| ABL-Refl | 99.04±0.85 | 0.22±0.02 | 93.5±3.2 |
表 6:召回率、推理时间和准确率。“超时”表示推理时间超过 1 小时。
6. 结论
在本文中,我们提出了溯因反思(Abductive Reflection, ABL-Refl)。它利用领域知识来溯因一个反思向量,该向量标记神经网络输出中的潜在错误,然后调用溯因,作为符号推理的注意力机制,专注于更小的问题空间。实验表明,ABL-Refl 显著优于其他神经符号方法,能够以更少的训练资源实现卓越的推理准确率,并且显著提高了推理效率。ABL-Refl 保留了机器学习和逻辑推理的完整性,具有更快的推理速度和高度的多功能性。因此,它具有广泛的应用潜力。在未来,它可以应用于大型语言模型(Mialon 等人 2023),以帮助识别其输出中的错误,并利用符号推理来增强其可信度和可靠性。



















 2187
2187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











