







DeepLab: Semantic Image Segmentation with
Deep Convolutional Nets, Atrous Convolution,
and Fully Connected CRFs 论文学习笔记:
最近在做场景分割的时候看到的一篇文章。它的deeplab v2 在PASCAL VOC12上正确率达到了79%,暂时是正确率最高的算法。
它针对了传统方法的3个不足:
1. reduced feature resolution (repeated combination of max-pooling and down sampling )
2. existence of objects at multiple scales
3. reduced localization accuracy due to DCNN invariance.
做了以下优化:
1. DCNN 原来是用于图像分类的,但是这里用于语义分割。所以把最后几个 down sampling 改成unsampling,这个是 feature map compute at higher layers (创建了一个atrous convolution 来代表unsampleing, 可以enlarge 参数或者计算量)
2. 传统方法是把image 强行转成相同尺寸。但是这样会导致某些特征扭曲或者消失。作者motivated by spatial pyramid pooling(空间金字塔池化)这个是用来去除网络固定大小的限制,使用了ASPP (atrous SPP)来解决这个问题
3. 解决DCNN invariance 可以选择skip 一些layers。不过作者是选择 全连接的CRF
这样做的优势 是: 速度快,准确率高,结构简单(RES-101 + CRF)。
结构图如下:
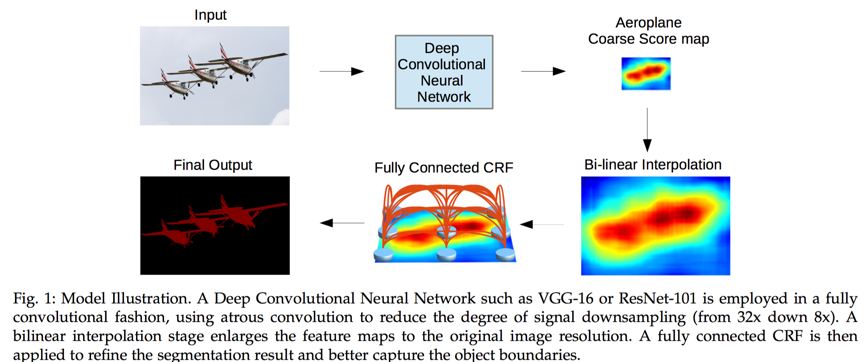
下面是上述3个改进的具体说明:
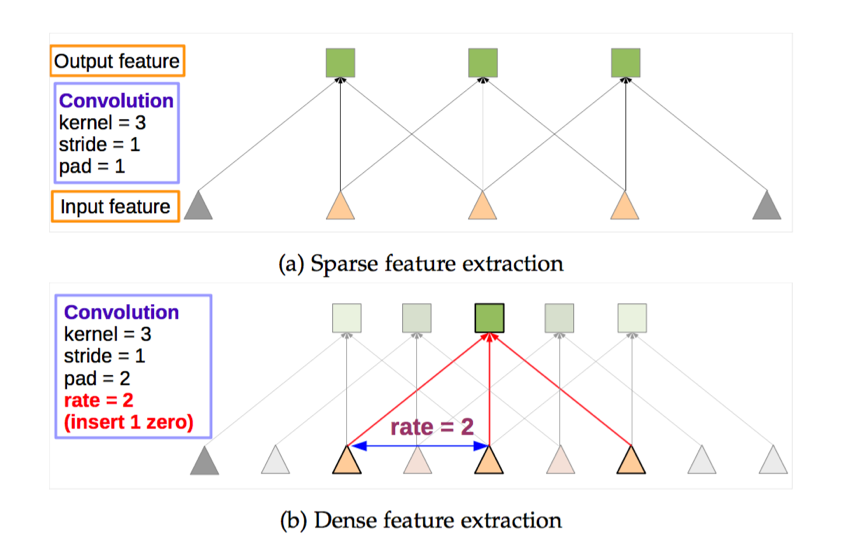
对于repeated convolution导致分辨率丢失的问题,作者采用了一个叫做atrous convolution 的卷积操作。
作者添加了一个rate 来跳过若干个相邻的卷积核。这个起到了maxpooling+ convolution的左右。
这个atrous convolution 结合了传统的downsampling,convolutio 和upsampling,得到的图像大小相同,但是特征明显清晰了很多。对于第二个问题:为了处理多尺寸图像,作者借鉴了SPP 的思路,设计了一个叫做ASPP 的网络。
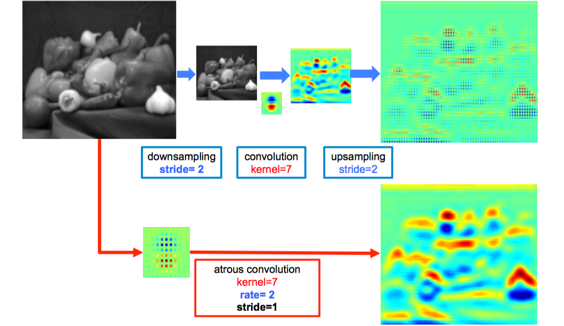
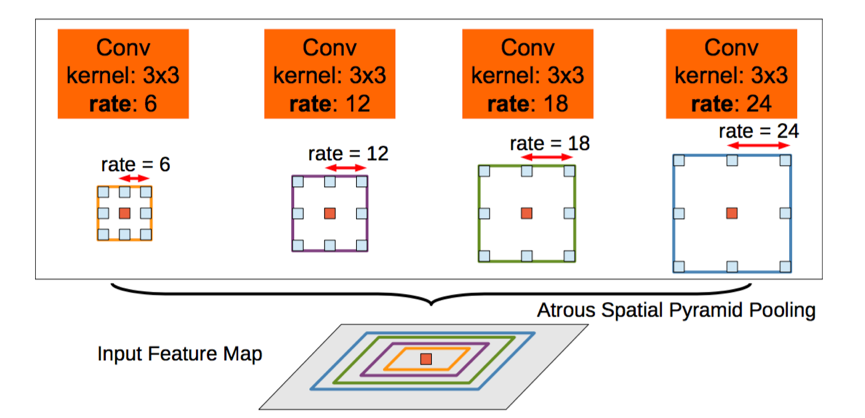
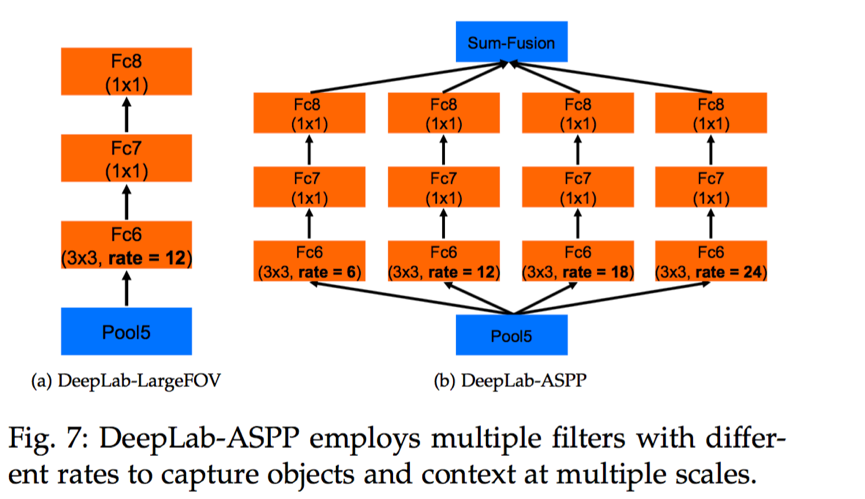
这个就是通过不同的A convolution 来对图像进行不同程度的缩放,得到不同大小的input feature map,(可以理解成SPP中使用不同大小的proposal)
这样ASPP 就保证了deeplabNet 可以处理不同尺寸的图片。
- 对于第三个问题,作者采用了CRF
CRF 就是对于相邻的相似点进行建模,是的相同的模块更加清晰。

这里直接上图对比下有无CRF 的结果对比。















 4675
4675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









