








分层的优点
- 时间上的抽象(Temporal abstraction):可以考虑持续一段时间的策略
- 迁移/重用性(Transfer/Reusability):把大问题分解为小问题后,小问题学习到的解决方法可以迁移到别的问题之上
- 有效性/有意义(powerful/meaningful)-状态上的抽象(state abstraction):当前的状态中与所解决问题无关的状态不会被关注
不同的最优
- 分层最优(Hierarchically optimal):遵循分层结构,但是每一个子部件不一定是局部最优
- 回溯最优(recursively optimal):遵循分层结构,每一个子部件一定是局部最优
- 平面最优(flat optimality):不受层级限制,只用最基本的动作去找到一个最优的策略,一般可以给出最多的选择
SMDP
- 动作action可持续,持续时间(holding time/ transition time)为 τ \tau τ,此期间状态不改变
- 数学上也是用
<
S
,
A
,
P
,
R
>
<\mathcal{S},\mathcal{A},\mathcal{P},\mathcal{R}>
<S,A,P,R>表示,但是在这段持续时间内存在不同的理解
- P ( s ′ , τ ∣ s , a ) P(s',\tau|s,a) P(s′,τ∣s,a)
- R = E [ r ∣ s , a , s ′ , τ ] R=E[r|s,a,s',\tau] R=E[r∣s,a,s′,τ]
SMDP QL的基本形式
V π ( s ) = E { r t + 1 + γ r t + 2 + γ 2 r t + 3 + ⋯ ∣ s t = s , π } V^\pi(s)=\mathbb{E}\{r_{t+1}+\gamma r_{t+2}+\gamma^2r_{t+3}+\cdots|s_t=s,\pi\} Vπ(s)=E{rt+1+γrt+2+γ2rt+3+⋯∣st=s,π}
Q π ( s , a ) = E { r t + 1 + γ r t + 2 + γ 2 r t + 3 + ⋯ ∣ s t = s , a t = a , π } Q^\pi(s,a)=\mathbb{E}\{r_{t+1}+\gamma r_{t+2}+\gamma^2r_{t+3}+\cdots|s_t=s,a_t=a,\pi\} Qπ(s,a)=E{rt+1+γrt+2+γ2rt+3+⋯∣st=s,at=a,π}
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r ˉ t + τ + γ τ max a ′ Q ( s t + τ , a t + τ ) − Q ( s t , a t ) ] Q(s_t,a_t)\leftarrow Q(s_t,a_t)+\alpha[\bar{r}_{t+\tau}+\gamma^\tau\max_{a'}{Q(s_{t+\tau},a_{t+\tau})}-Q(s_t,a_t)] Q(st,at)←Q(st,at)+α[rˉt+τ+γτmaxa′Q(st+τ,at+τ)−Q(st,at)]
r ˉ t + τ = r t + 1 + γ r t + 2 + ⋯ + γ τ − 1 r t + τ \bar{r}_{t+\tau}=r_{t+1}+\gamma r_{t+2}+\cdots+\gamma^{\tau-1} r_{t+\tau} rˉt+τ=rt+1+γrt+2+⋯+γτ−1rt+τ
基于选项的学习(Option)
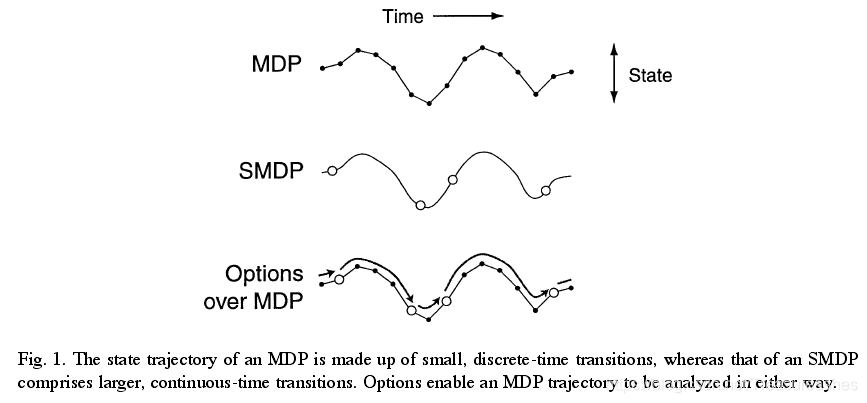
最简单,最受欢迎的分层结构
思想
- 完成一项任务或解决一个问题一般需要多个层级的步骤参与(例:做饭、去车站)
- 理论上层级可以无限多,如何划分不同的层级?
- 如何想出最初的option?
option
直到option结束的reward+到结束的带折扣因子的转移概率
- 初始集/函数:由之前的情况决定
- 选项内的policy
- 终止条件:由过去的条件决定
值函数带有依赖状态的折扣
action
即时的reward+到下一个状态的转移概率
时间差分法TD
V ( s ) ← V ( s ) + α ( R t + 1 + γ V ( s ′ ) − V ( s ) ) V(s)\leftarrow V(s)+\alpha(R_{t+1}+\gamma V(s')-V(s)) V(s)←V(s)+α(Rt+1+γV(s′)−V(s))
SMDP QL(option)
option是action的特例
一个option的Reward是多个action积累而成
值函数的更新方式:bootstrapping(利用后继状态的值函数估计当前值函数)
Q
(
s
,
o
)
←
Q
(
s
,
o
)
+
α
[
r
+
γ
k
max
o
′
∈
O
s
′
Q
(
s
′
,
o
′
)
−
Q
(
s
,
o
)
]
Q(s,o)\leftarrow Q(s,o)+\alpha[r+\gamma^k\max_{o'\in\mathcal{O}_{s'}}Q(s',o')-Q(s,o)]
Q(s,o)←Q(s,o)+α[r+γkmaxo′∈Os′Q(s′,o′)−Q(s,o)]
Intra-option QL
Q ( s 1 , a 1 ) ← Q ( s 1 , a 1 ) + α [ r 1 + γ max a Q ( s 2 , a ) − Q ( s 1 , a 1 ) ] Q(s_1,a_1)\leftarrow Q(s_1,a_1)+\alpha[r_1+\gamma\max_aQ(s_2,a)-Q(s_1,a_1)] Q(s1,a1)←Q(s1,a1)+α[r1+γmaxaQ(s2,a)−Q(s1,a1)]
Q ( s 2 , a 2 ) ← ⋯ Q(s_2,a_2)\leftarrow \cdots Q(s2,a2)←⋯
Q
(
s
1
,
o
)
←
Q
(
s
1
,
o
)
+
α
[
r
1
+
γ
Q
(
s
2
,
o
)
−
Q
(
s
1
,
o
)
]
Q(s_1,o)\leftarrow Q(s_1,o)+\alpha[r_1+\gamma Q(s_2,o)-Q(s_1,o)]
Q(s1,o)←Q(s1,o)+α[r1+γQ(s2,o)−Q(s1,o)],如果option没有在S2结束
Q
(
s
1
,
o
)
←
Q
(
s
1
,
o
)
+
α
[
r
1
+
γ
max
a
Q
(
s
2
,
a
)
−
Q
(
s
1
,
o
)
]
Q(s_1,o)\leftarrow Q(s_1,o)+\alpha[r_1+\gamma\max_{a}Q(s_2,a)-Q(s_1,o)]
Q(s1,o)←Q(s1,o)+α[r1+γmaxaQ(s2,a)−Q(s1,o)],如果option在S2结束
可以利用在S2结束的概率
β
\beta
β将两式统一:
Q
(
s
1
,
o
)
←
Q
(
s
1
,
o
)
+
α
[
r
1
+
(
1
−
β
)
γ
Q
(
s
2
,
o
)
+
β
max
a
Q
(
s
2
,
a
)
−
Q
(
s
1
,
o
)
]
Q(s_1,o)\leftarrow Q(s_1,o)+\alpha[r_1+(1-\beta)\gamma Q(s_2,o)+\beta\max_{a}Q(s_2,a)-Q(s_1,o)]
Q(s1,o)←Q(s1,o)+α[r1+(1−β)γQ(s2,o)+βmaxaQ(s2,a)−Q(s1,o)]
Option Discovery
good option
- 重用性(reusability)
- 减少探索(cut down on exploration)
- 促进迁移(transfering)
这些标准都难以实际地进行评估
surrogate measures: bottlenecks/ access states
瓶颈状态可以提供结束的概率 β \beta β
- graph partitioning ideas (Shimon):如果有一个MDP转移矩阵,可以将其分割为多个子图,里面的最弱的连接就是瓶颈;如果没有图,可以随机游走,然后根据数据产生图
- diverse density:启发式的,successful trajectories的密度会比不成功的大,option所在的概率也会更大。自然地用到了experience replay
- betweeness:跟graph partitioning ideas很像
- small world option:不需要任何的先验知识,但是需要一些数据,然后将其分为small world graph,可以大幅减少学习时间,因为其遵守一定的概率分布
基于分层局部策略的学习(HAM)
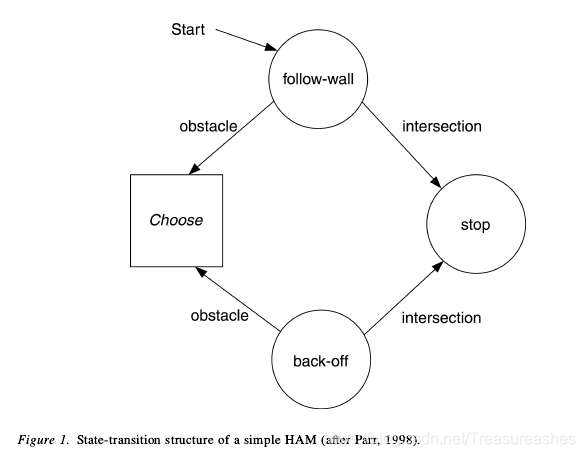
比option更为复杂,有人认为是最优雅的分层理论,较为依赖于先验知识与编程技巧
抽象机的状态
- action:执行原始的动作
- call:调用另一个抽象机
- choice:无差别地选择另一个状态
- stop:停止现在的抽象机
例子:在充满障碍的房间里探索
更新方式
在三个矩阵上更新:
- Hi:机器的调用状态(call stack)
- Si:核心的状态-对应原始动作(core MDP)
- Mi:机器的状态(machine state)
当遵循policy在不同机器、不同机器状态中转移的时候只更新Hi和Mi,调用了原始的动作的时候才会更新Si
与option的对应
option与对应的policy是绑定在一起的,也就是说option一旦开始,policy就被冻结了,内部是没有choice状态的。从这个角度来看HAM更加灵活,因为它的每个抽象机都是可以有choice状态的。
基于子任务的学习(MAXQ)
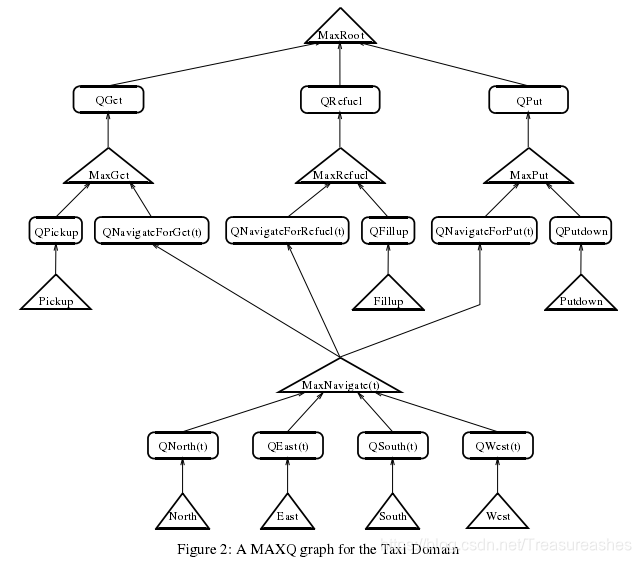
更加符合直觉的表达方式。像HAMs一样,MAXQ是编程语言中的概念如何与随机最优控制框架成功集成的一个很好的例子。
例子:出租车
任务M被分为多个子任务M0,M1,~,Mi。对于每个子任务Mi:
- Si:taxi的位置、乘客的位置、乘客的目的地
- Ai:所有子任务与原始动作的集合的子集(保持dag的结构)
- Ri:假回报-只与子任务有关
如果不存在假回报,则此种方法称为MAXQ0 Learning
SMDP
- 状态空间Si
- 动作空间Ai
- 转移矩阵-在子任务Mi中,需要 τ \tau τ步从s转移到s’: P i ( s ′ , τ ∣ s , a ) P_{i}(s',\tau|s,a) Pi(s′,τ∣s,a)~ M a M_a Ma
- 回报Ri也是积累而来: R i ( s , a ) = E { r t + γ r t + 1 + ⋯ ∣ s t = s , a t = a , π } R_i(s,a)=\mathbb{E}\{r_t+\gamma r_{t+1}+\cdots|s_t=s,a_t=a,\pi\} Ri(s,a)=E{rt+γrt+1+⋯∣st=s,at=a,π}
值函数的分解
V π ( i , s ) = V π ( π i ( s ) , s ) + ∑ s ′ , τ P i π ( s ′ , τ ∣ s , π i ( s ) ) γ τ v π ( i , s ′ ) V^\pi(i,s)=V^\pi(\pi_{i}(s),s)+\sum_{s',\tau}P_i^\pi(s',\tau|s,\pi_i(s))\gamma^{\tau}v^\pi(i,s') Vπ(i,s)=Vπ(πi(s),s)+∑s′,τPiπ(s′,τ∣s,πi(s))γτvπ(i,s′)
q π ( i , s , a ) = V π ( a , s ) + ∑ s ′ , τ P i π ( s ′ , τ ∣ s , a ) γ τ q π ( i , s ′ , π i ( s ) ) q^\pi(i,s,a)=V^\pi(a,s)+\sum_{s',\tau}P_i^\pi(s',\tau|s,a)\gamma^{\tau}q^\pi(i,s',\pi_i(s)) qπ(i,s,a)=Vπ(a,s)+∑s′,τPiπ(s′,τ∣s,a)γτqπ(i,s′,πi(s))
q π ( i , s , a ) = V π ( a , s ) + C π ( i , s , a ) q^\pi(i,s,a)=V^\pi(a,s)+C^\pi(i,s,a) qπ(i,s,a)=Vπ(a,s)+Cπ(i,s,a)
V π ( i , s ) = V^\pi(i,s)= Vπ(i,s)=
-
q π ( i , s , π i ( s ) ) q^\pi(i,s,\pi_i(s)) qπ(i,s,πi(s)) ,a是复合(composite)的
-
∑ s ′ P ( s ′ ∣ s , a ) E { r ∣ s , a , s ′ } \sum_{s'}P(s'|s,a)E\{r|s,a,s'\} ∑s′P(s′∣s,a)E{r∣s,a,s′},a是原始(primitive)的
与其它两个的不同
option和ham都是在一个SMDP里学习的,但MAXQ是在SMDP的集合(每个子任务对应一个SMDP)中学习的














 1393
1393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









