







科技飞速发展,人工智能与工业领域的融合日益深入。NXP旗下的i.MX 8M Plus作为一款高端工业处理器,NPU算力高达2.3TOPS,正引领着工业智能化的浪潮,为众多工业场景带来了前所未有的变革潜力。

图 1
i.MX 8M Plus NPU特性
i.MX 8M Plus的NPU支持INT16/INT32/FP16/FP32等多种数据类型,兼容性卓越,与TensorFlow Lite/Arm NN/ONNX Runtime/DeepViewRT等框架无缝对接。这一特性,为开发者们打造了一个极为丰富的工具和库生态系统,更便利进行模型开发与训练工作,轻松应对各种复杂的大数据运算场景,无论是海量工业数据的分析处理,还是精准智能决策的模型构建,更加游刃有余。
i.MX 8M Plus NPU开发流程
第一步:模型开发
首先,从TensorFlow预训练模型库中选择一个合适的模型,或根据具体任务需求创建自定义模型。然后,收集和准备训练数据集。
第二步:模型训练
可通过eIQ Toolkit工具调整参数(如Weight initialization、Input size、Learning rate等)优化模型性能,配置训练参数后,开始模型训练。
第三步:模型量化
可通过量化一个训练后的模型,减少其大小,并加快在NPU上的推理时间,实现最小的精度损失。
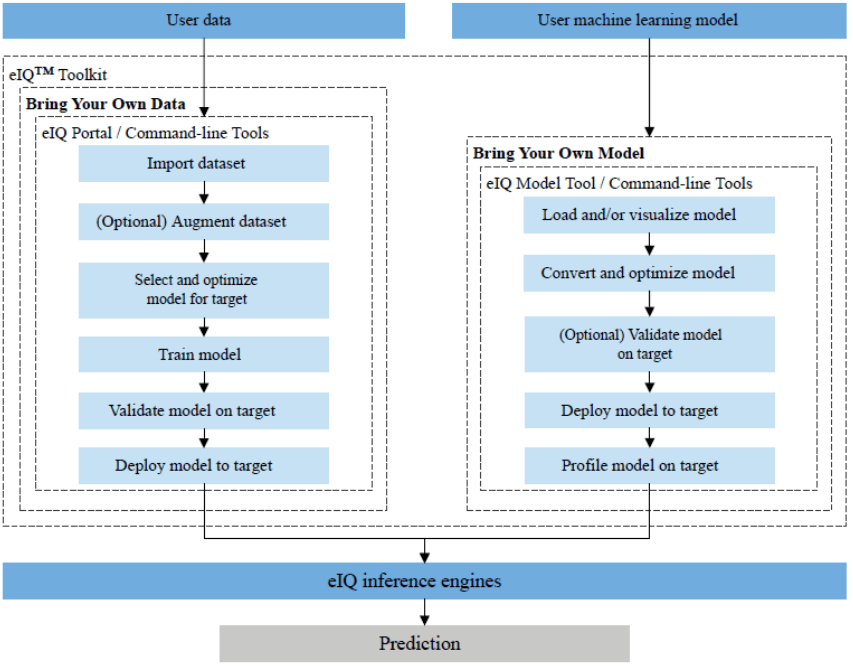
图 2 开发流程示意图
i.MX 8M Plus 典型工业应用

图 3
NPU开发案例演示
本文主要介绍基于i.MX 8M Plus的NPU开发案例,适用开发环境如下。
Windows开发环境:Windows 7 64bit、Windows 10 64bit
虚拟机:VMware15.5.5
开发环境:Ubuntu20.04.6 64bit
U-Boot:U-Boot-2022.04
Kernel:Linux-5.15.71-rt51
LinuxSDK:Real-Time Edge Software 2.5
硬件平台:创龙科技TLIMX8MP-EVM工业评估板(基于i.MX 8M Plus)
为了简化描述,本文仅摘录部分方案功能描述与测试结果,详细产品资料请扫描文末二维码下载。
案例说明
案例基于预训练的TensorFlow Lite模型实现对图片中目标对象的分类。TensorFlow Lite模型循环测试10次,统计出推理的平均处理耗时和帧率,获取模型输出的前五个标签及置信度打印至串口终端并通过HDMI显示屏绘制标签及置信度概率最大的对象结果。
程序处理流程图如下:
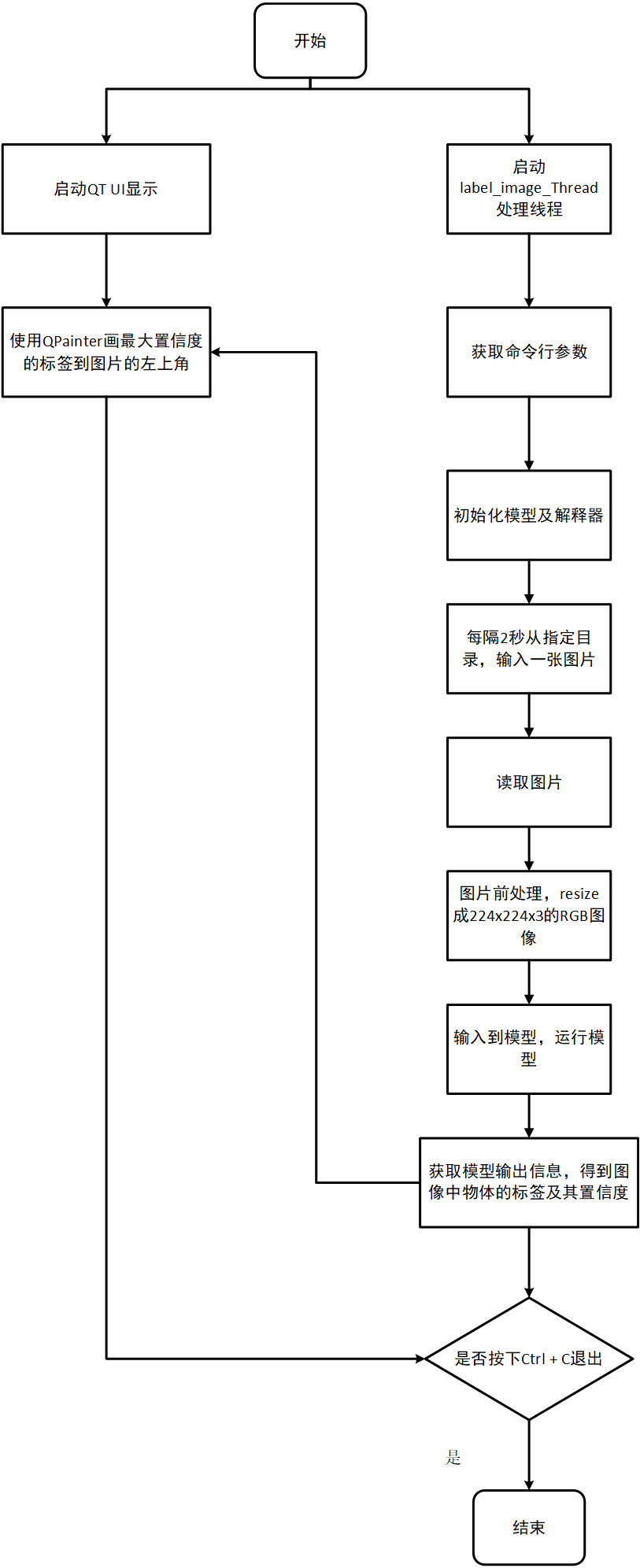
图 4
案例演示
通过网线将评估板千兆网口ETH0连接至路由器,将HDMI显示器与评估板HDMI2 OUT接口(CON22)连接。

图 5
在可执行文件所在目录,执行如下命令,对图片目标对象进行推理。
Target#./mobilenetv1_label_image -m mobilenet_v1_1.0_224_quant.tflite -y ./bmp_image -l labels.txt -c 10 --external_delegate_path=/usr/lib/libvx_delegate.so
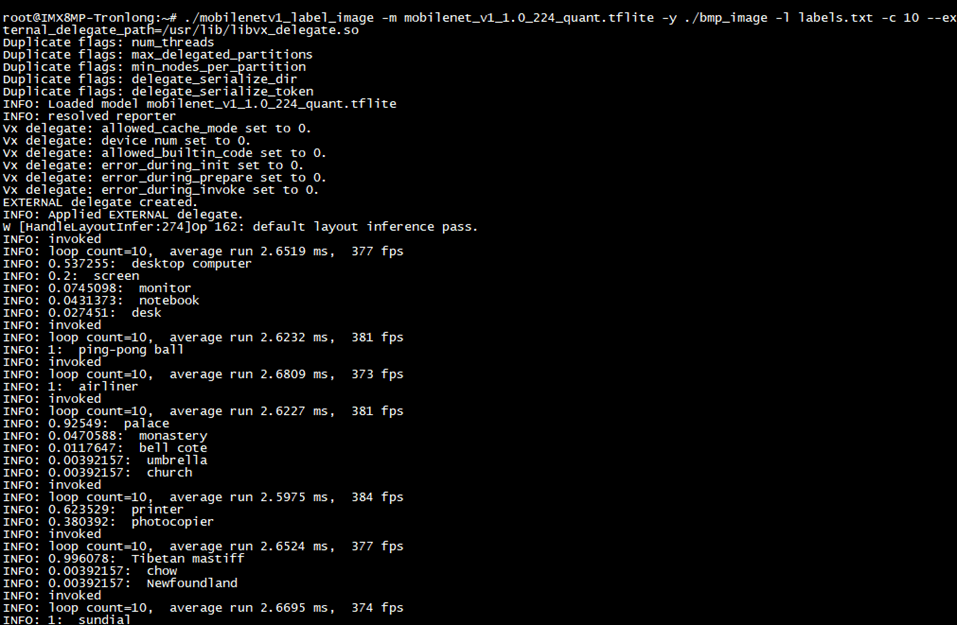
图 6
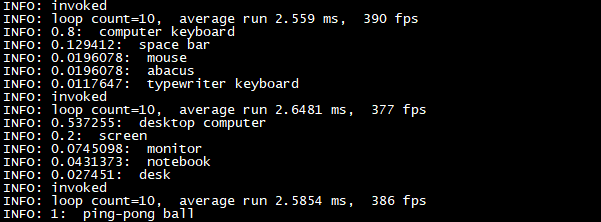
图 7
程序滚动识别多张图片,以第1张图片识别结果为例,输出结果信息如下所示。
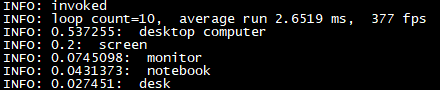
图 8
从输出信息可知,本张图片识别为桌面电脑、屏幕、监控器、笔记本电脑、桌子的概率分别为53.7255%、20%、7.45098%、4.31373%、2.7451%,程序循环运行10次模型平均耗时为2.6519ms,帧率为377fps。
案例程序对测试图片的目标对象进行识别后,通过HDMI显示屏绘制标签及置信度概率最大的对象结果如下所示。

图 9
若您希望深入了解更多i.MX 8M Plus相关的精彩案例演示,可以通过公众号(Tronlong创龙科技)获取详细资料,快来一起试试吧!


















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











