






1.摘要:
检测将对象识别为轴向boxes,大部分目标检测枚举了详尽的潜在目标位置和对每个潜在对象分类,这是浪费的,低效的,需要很多后处理。本文将目标建模为一个点——bbox的中心。本文检测器用关键点评估来找到中心点和其他目标属性的回归。本文的方法叫CenterNet,是一个端到端的,更简单,更快,更精确的检测器。
2.介绍:
one-stage detector为可能的bboxes滑动一个复杂的安排,叫做anchor,然后直接对他们分类,不经过具体的box内容。two-stage的。。。。,尽管如此,这些idea已经取得了经验上的成功。
在本文,通过一个在bbox中心的single point来表达一个目标,其他属性,例如目标size,维度,3D程度,指引,和姿势都从中心定位的特征直接回归。简单的将input image送入全连接网络,生成热点图(heatmap),这个热点图的山峰(peak)对应目标的中心,在每一个山峰的图像特征预测目标的bbox高宽。模型训练使用标准的密集监督式学习,后处理不用nms了。

相关工作:
本文的方法和anchor based的one-stage的方法密切相关,中心点可以看做一个形状不可知的anchor。但是不同的是:
1.我们只用中心点定位,不用于框的重叠计算,对于前景和背景没有手动的阈值(前人的0.7,0.3)。
2.对每一个目标只有一个positive“anchor”(点),因此不用进行nms。通过在关键点热点图简单的采集山峰获得。
3.centernet使用大的输出像素(步距为4),这消除了对多个anchor的需要。
通过关键点评估进行目标检测:
本文不是首先对于目标点检测用关键点评估,cornernet检测bbox两个角落作为关键点,extremenet检测上,左,下,右。和两个方法和本文方法建立了同样鲁棒的关键点评估网络,但是前两个方法在关键点检测之后需要一个组合分组阶段,这降低了速度。本文不需要组合分组阶段
单眼3D目标检测:
本文和one-stage版本的deep3dbox或者3drcnn类似,和这些方法比centernet更加简单和快。
3.初步
输入图像为 I ∈ R W × H × 3 I \in R^{W \times H \times 3} I∈RW×H×3 ,本文的目标是生成一个关键点的热点图: Y ^ ∈ [ 0 , 1 ] W R × H R × C \hat{Y} \in[0,1]^{\frac{W}{R} \times \frac{H}{R} \times C} Y^∈[0,1]RW×RH×C ,其中R是下采样的步距(stride),C是关键点类型的数量,例如:C=17表示人的十七个关节,C=80表示目标检测的种类。R默认为4。预测出 Y ^ x , y , c = 1 \hat{Y}_{x, y, c}=1 Y^x,y,c=1表示类别c在当前检测到这个类别的目标,预测出 Y ^ x , y , c = 0 \hat{Y}_{x, y, c}=0 Y^x,y,c=0表示检测到背景,本文使用几个不同的全卷积编码解码网络来从一张图I中预测 Y ^ \hat{Y} Y^,包括:堆叠的沙漏网络,resnet,DLA
关键点预测网络基于xxx建立,对于类别c的每一个真实关键点(ground truth keypoint,gtpoint) p ∈ R 2 p \in R^2 p∈R2,计算一个低像素的对应: p ~ = ⌊ p R ⌋ \tilde{p}=\left\lfloor\frac{p}{R}\right\rfloor p~=⌊Rp⌋,然后使用高斯核 Y x y c = exp ( − ( x − p ~ x ) 2 + ( y − p ~ y ) 2 2 σ p 2 ) Y_{x y c}=\exp \left(-\frac{\left(x-\tilde{p}_{x}\right)^{2}+\left(y-\tilde{p}_{y}\right)^{2}}{2 \sigma_{p}^{2}}\right) Yxyc=exp(−2σp2(x−p~x)2+(y−p~y)2)把所有的gtpoint对应到热点图 Y ∈ [ 0 , 1 ] W R × H R × C {Y} \in[0,1]^{\frac{W}{R} \times \frac{H}{R} \times C} Y∈[0,1]RW×RH×C上,高斯核中 σ p \sigma_{p} σp是一个目标大小(size)相关的标准差,如果某一个类的两个高斯分布发生了重叠,直接取元素间最大的就可以。
官方代码中生成的gtpoint高斯分布

每个点
Y
∈
[
0
,
1
]
W
R
×
H
R
×
C
{Y} \in[0,1]^{\frac{W}{R} \times \frac{H}{R} \times C}
Y∈[0,1]RW×RH×C 的范围是0-1,而1则代表这个目标的中心点,也就是我们要预测要学习的点。
损失函数为:(使用了focal loss)真值,带帽子的是预测值)

α和β是超参数,N是图像I的关键点数量,选择N来归一化将所有得正的focal loss归一化到1。使用α=2,β=4。
α的作用:当真值 Y x y c Y_{x y c} Yxyc为1时,如果 Y ^ x y c \hat{Y}_{x y c} Y^xyc接近1,说明这个是一个比较容易检测出的点,那么 ( 1 − Y ^ x y c ) a (1-\hat{Y}_{x y c})^a (1−Y^xyc)a就很小,减少训练比重,反之 Y ^ x y c \hat{Y}_{x y c} Y^xyc接近0,说明这个中心点还没有学习到,要加大其训练的比重, ( 1 − Y ^ x y c ) a (1-\hat{Y}_{x y c})^a (1−Y^xyc)a就很大
当真值不为1,是otherwise时, Y ^ x y c \hat{Y}_{x y c} Y^xyc理应为0,如果不为0且较大,接近于1,那么 ( Y ^ x y c ) a (\hat{Y}_{x y c})^a (Y^xyc)a就很大,增加训练比重。
β的作用:注意这里用的是真实值, ( 1 − Y x y c ) β (1-{Y}_{x y c})^β (1−Yxyc)β,当离中心点远的时候,这个值就大,使接近中心点的时候,检测得 Y ^ x y c \hat{Y}_{x y c} Y^xyc接近1如0.9也是情有可原的,用 ( 1 − Y x y c ) β (1-{Y}_{x y c})^β (1−Yxyc)β来降低loss权重,但是当远离中心点的手,即便检测得 Y ^ x y c \hat{Y}_{x y c} Y^xyc=0.1,那损失也是很大的,要增大损失权重。这一项使距离中心点越远的点的损失比重占的越大,而越近的点损失比重则越小,这相当于弱化了实际中心点周围的其他负样本的损失比重,相当于处理正负样本的不平衡了。
综上:
( 1 − Y ^ x y c ) a 和 ( Y x y c ) a (1-\hat{Y}_{x y c})^a和({Y}_{x y c})^a (1−Y^xyc)a和(Yxyc)a来限制easy example导致的gradient被easy example dominant的问题,而 ( 1 − Y x y c ) β (1-{Y}_{x y c})^β (1−Yxyc)β则用来处理正负样本的不平衡问题(因为每一个物体只有一个实际中心点,其余的都是负样本,但是负样本相较于一个中心点显得有很多)。
传统的基于anchor的检测方法,通常选择与标记框IoU大于0.7的作为positive,IoU小于0.3的则标记为negative。在训练过程中使positive和negative的box比例为1:3来减少negative box的比例(例如SSD没有使用focal loss)。
而在CenterNet中,每个中心点对应一个目标的位置,不需要进行overlap的判断。那么怎么去减少negative center pointer的比例呢?CenterNet是采用Focal Loss的思想,在实际训练中,中心点的周围其他点(negative center pointer)的损失则是经过衰减后的损失(上文提到的),而目标的长和宽是经过对应当前中心点的w和h回归得到的:
offset:
因为进行了R=4的下采样,这样的特征图重新映射到原始图像上的时候会带来精度误差,例如首先读入图像[640,320],然后变形成[512,512],然后下采样4倍成[128,128]。如果原图中心点映射到heatmap上的位置为[98.97667,2.3566666],但通过heatmap预测出的点为[98,2],直接将[98,2]映射回原图[640,320],就会有偏差,因此对于每一个中心点,额外采用了一个local offset: O ^ ∈ R W R × H R × 2 \hat{O} \in R^{\frac{W}{R} \times \frac{H}{R} \times 2} O^∈RRW×RH×2
这个offset是根据损失函数计算得到:

O
^
\hat{O}
O^是预测得到的offset,括号里的是计算得到的真实的offset,所有的类都共用这个offset,这个监督只在关键点处使用,其他位置忽略
4.object as point:
对预测size的处理:
假设目标k 的真实size是:
s
k
=
x
2
(
k
)
−
x
1
(
k
)
−
y
2
(
k
)
−
y
1
(
k
)
s_k=x_{2(k)}-x_{1(k)}-y_{2(k)}-y_{1(k)}
sk=x2(k)−x1(k)−y2(k)−y1(k),(下采样之后的长宽值)预测出的是
S
^
∈
R
W
R
×
H
R
×
2
\hat{S} \in R^{\frac{W}{R} \times \frac{H}{R} \times 2}
S^∈RRW×RH×2 ,对所有的类别通用。使用L1 loss,损失函数为:

注意,这里使用的是下采样之后的长宽值。
总的损失是,用λ控制权重,λsize=0.1,λoff=1

所以最后输出是C+4(C是类别,4表示偏移加尺寸),对于每一种形态(如目标检测,3d检测),都共用backbone,通过最后的3x3卷积,relu,和1x1卷积来分离开。
从point到bbox:
推理阶段,负每一个类单独采集热点图的peak(顶峰),
如何判定是顶峰:如果一个值大于等于他周围的8个值,那么就是顶峰。
保留最后的100个顶峰,最后再通过一个阈值,调出大于该阈值的中心点作为最终的结果
设
P
^
c
\hat{P}_c
P^c是类别c的n个检测出的中心点集:

每一个关键点都用一个整数坐标(x_i,y_i)定位。使用关键点的值\hat{Y}_{x_iy_ic}作为检测的置信度,从而在检测位置生成一个box:

其中
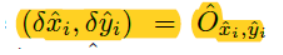
是预测的偏移。
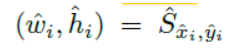
是预测的尺寸。
整个过程直接从关键点估计,没用iou,nms或者其他后处理,顶峰关键点的采集作为足够的nms选择。
实现细节:
实验了四个框架:resnet18,resnet101,dla34,hourglass104.在resnet和dla34中使用了可变性卷积
训练:一些参数设置。
推理:使用了三个版本:no augmentation,flip augmentation,flip and multi-scale(0.5,0.75,1,1,25,1.5),
对于flip,在解码bbox之前平均网络输出;(例如,用和不用flip分别预测了位置和bbox,,然后做一个平均位置和bbox尺寸的操作)
对于multi-scale,使用 NMS来选择结果。
这些增强产生了不同的速度和精度平衡。如下图:

DLA34取得了最好的速度和精度平衡,52fps,37.4%AP。















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









