










Faster R-CNN 的模型结构是其高效目标检测能力的核心所在。以下是对 Faster R-CNN 主要组成部分的详细介绍:
一、 特征提取网络(Backbone)
特征提取网络是Faster R-CNN架构中的核心部分,负责编解输入图像并提取有效特征,辅助后续的目标检测任务。在Faster R-CNN中,ResNet和FPN(Feature Pyramid Networks)的结合是一个非常有效的选择。
1. ResNet(残差网络)
ResNet是一种深度卷积神经网络,其主要创新在于引入了残差学习的概念。以下是ResNet的一些关键特点:
残差块(Residual Blocks):每个残差块包含两个或更多的卷积层,并且通过快捷连接(skip connection)直接将输入添加到输出中。这一设计使得网络能够学习到残差(target function minus identity mapping),从而更容易优化。
深度学习的可训练性:借助残差连接,ResNet可以构建非常深的网络(如ResNet-50、ResNet-101,甚至ResNet-152),而不易出现梯度消失的问题,推动了深度学习的发展。
特征丰富性:深层的残差网络能够学习更抽象、层次更丰富的特征,对于复杂图像内容的表示能力非常强。
2. 特征金字塔网络(FPN)
FPN是用于目标检测和图像分割的策略,通过构建特征金字塔,增强了模型对不同尺度目标的检测能力。FPN的功能包括:
多尺度特征提取:FPN在生成图像的不同分辨率特征图时,通过特征金字塔的结构,允许网络在不同的尺度处理具有不同大小的目标。高分辨率的特征图能够捕捉小目标的细节,而较低分辨率的特征图则提供更多的上下文信息,有助于检测大目标。
自上而下的特征融合:FPN采用自上而下的路径构建特征金字塔,结合高层特征和上一级特征。具体来说,将高层特征进行上采样,然后与较低层的特征图进行横向连接。这种方式使得不同层次的特征能够整合,保留细节信息。
增强目标检测能力:通过使用FPN,Faster R-CNN能够更有效地处理小目标和大目标,同时避免信息丢失,提高了检测精度。
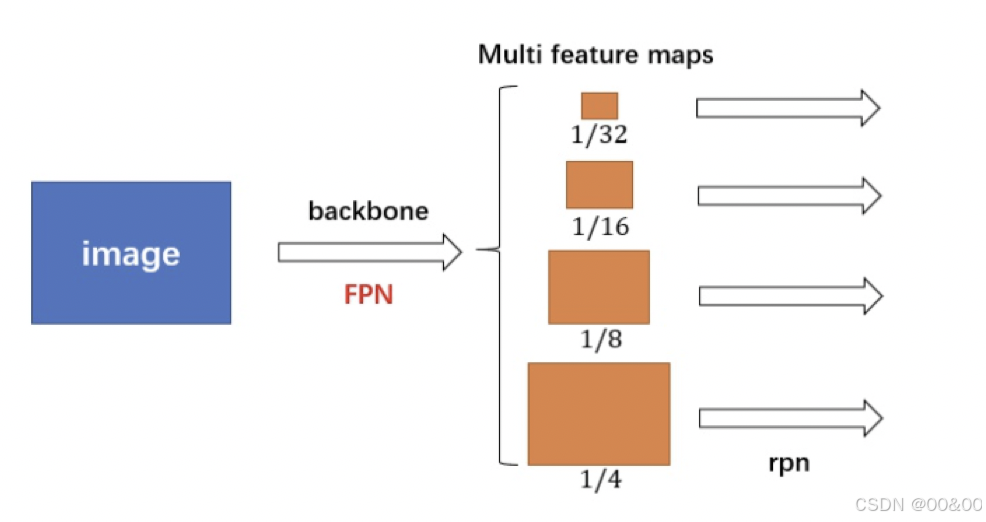
3. 生成特征图(Feature Maps)
使用ResNet和FPN后,Faster R-CNN能够生成多尺度的特征图,这些特征图是后续区域建议和目标分类的基础。具体包括:
多层特征图输出:FPN通过不同层次的特征图,提供了多样化的信息表达,使得不同维度的信息相互补充。
丰富的上下文信息:不同层次的特征图能够提供一定的空间上下文,这对目标检测的精度和召回率有显著提升。
用于RoI生成和分类的基础:这些特征图随后被用于生成候选区域(RoIs),并为目标分类和边界框回归提供必要的信息支撑。
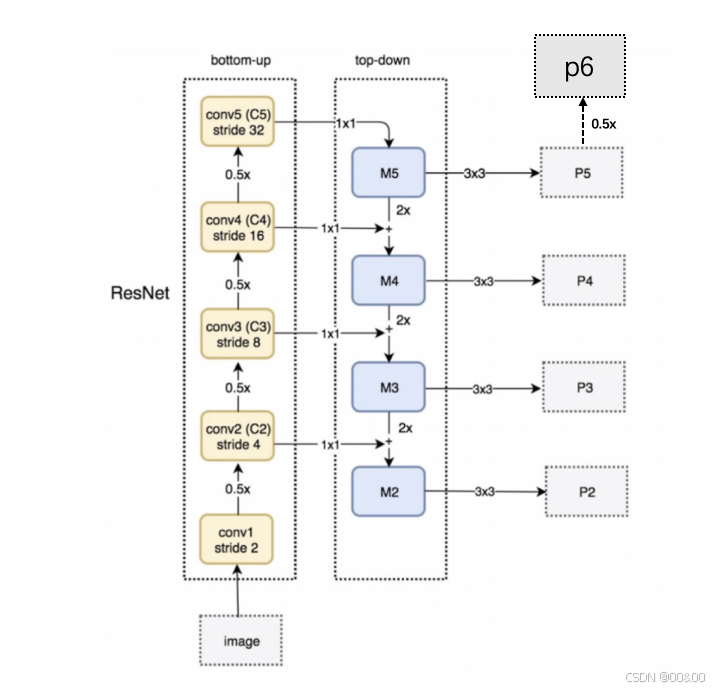
ResNet与FPN的结合为Faster R-CNN的特征提取网络提供了强大的基础,通过深层次的特征学习和多尺度特征整合,为复杂场景中的目标检测任务提供了显著的提升。这种设计不仅提高了模型的检测精度,还增强了模型在处理中小目标时的表现,促进了目标检测领域的发展。
二、区域建议网络(RPN)详细描述
区域建议网络(Region Proposal Network, RPN)是 Faster R-CNN 框架中至关重要的组件,致力于从特征图中生成高质量的候选区域(Region of Interest, RoIs)。RPN 的设计旨在实现快速且高效的目标检测,减少传统方法(如选择性搜索)的计算开销。
1. 锚框(Anchors)
锚框的概念:
在 RPN 中,锚框是预定义的一组边界框,位于特征图的每个位置。这些框具有固定的大小和纵横比,旨在覆盖多种尺度和形状的目标。锚框通过定义在特征图上多个预先设定的框,允许模型在不同位置和尺度上进行检测。
锚框生成:
每个特征图的位置会生成多个锚框,通常会根据多种尺寸和纵横比组合来设计。例如,可以设置一组常见尺寸(如 128x128, 256x256, 512x512)和不同的纵横比(如 1:1, 1:2, 2:1)。
参数设置:
锚框的数量和尺寸需要根据训练数据的分布进行调整,以确保它们能有效地覆盖目标物体的不同大小。通常,设置 9 个锚框(例如 3 种尺寸和 3 种纵横比的组合)。
示例:
如果输入特征图的尺寸为,并且每个位置生成 9 个锚框,那么总的锚框数量将是
。
2. 分类子网
分类子网的功能:
分类子网的主要任务是判断每个锚框的内容是物体(前景)还是背景。这一过程通过对特征图进行卷积计算,然后将结果通过全连接层处理,输出前景和背景的概率。
实现流程:
步骤1 卷积操作:
将特征图输入到若干个卷积层,通过卷积提取高层次特征,为后续的分类提供支持。
步骤2 输出层:
通过一层或多层全连接神经网络,针对每个锚框输出一个得分(通常为 logits),表示其为前景与背景的概率。
步骤3 损失函数:
使用交叉熵损失函数对分类结果进行优化,以提高前景和背景的分类准确性。示例代码:
class ClassificationSubNet(nn.Module):
def __init__(self, in_channels, num_anchors):
super(ClassificationSubNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 512, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(512, num_anchors * 2, kernel_size=1, stride=1) # 输出前景与背景的得分
def forward(self, x):
x = self.relu(self.conv1(x))
return self.conv2(x) # 返回每个锚框的分类得分3. 回归子网
回归子网的功能:
回归子网用于对每个锚框的坐标进行调整,使其更加准确地围绕目标。通过回归网络,输出相对于锚框的四个边界框坐标的偏移值,从而使得候选区域更接近真实目标的边界框。
实现流程:
步骤1 预测格式:
网络将每个锚框的偏移(delta)作为输出,通常是 x、y 坐标的偏移量和宽度、高度的缩放因子,共四个值。
步骤2 损失计算:
使用平滑 L1 损失(Smooth L1 Loss)来计算预测框与真实框之间的回归损失,确保预测框与目标的重合度提高。示例代码:
class RegressionSubNet(nn.Module):
def __init__(self, in_channels, num_anchors):
super(RegressionSubNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 512, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(512, num_anchors * 4, kernel_size=1, stride=1) # 输出边界框偏移量
def forward(self, x):
x = self.relu(self.conv1(x))
return self.conv2(x) # 返回每个锚框的坐标回归参数4. RPN 的工作流程
RPN 的整个工作流程可以总结为以下几个步骤:
特征提取:通过 Backbone 网络(如 ResNet + FPN)提取输入图像的特征图。
锚框生成:在特征图的每个位置生成多个锚框。
前景与背景分类:根据特征图中的信息,通过分类子网对每个锚框进行前景/背景分类。
边界框回归:通过回归子网对锚框的位置进行调整。
损失计算与训练:计算分类误差和回归误差,使用合适的损失函数优化 RPN,以实现端到端的训练。
候选区域生成:经过 NMS(非极大值抑制)处理,筛选出高质量的候选区域(RoIs)供后续的目标检测步骤使用。
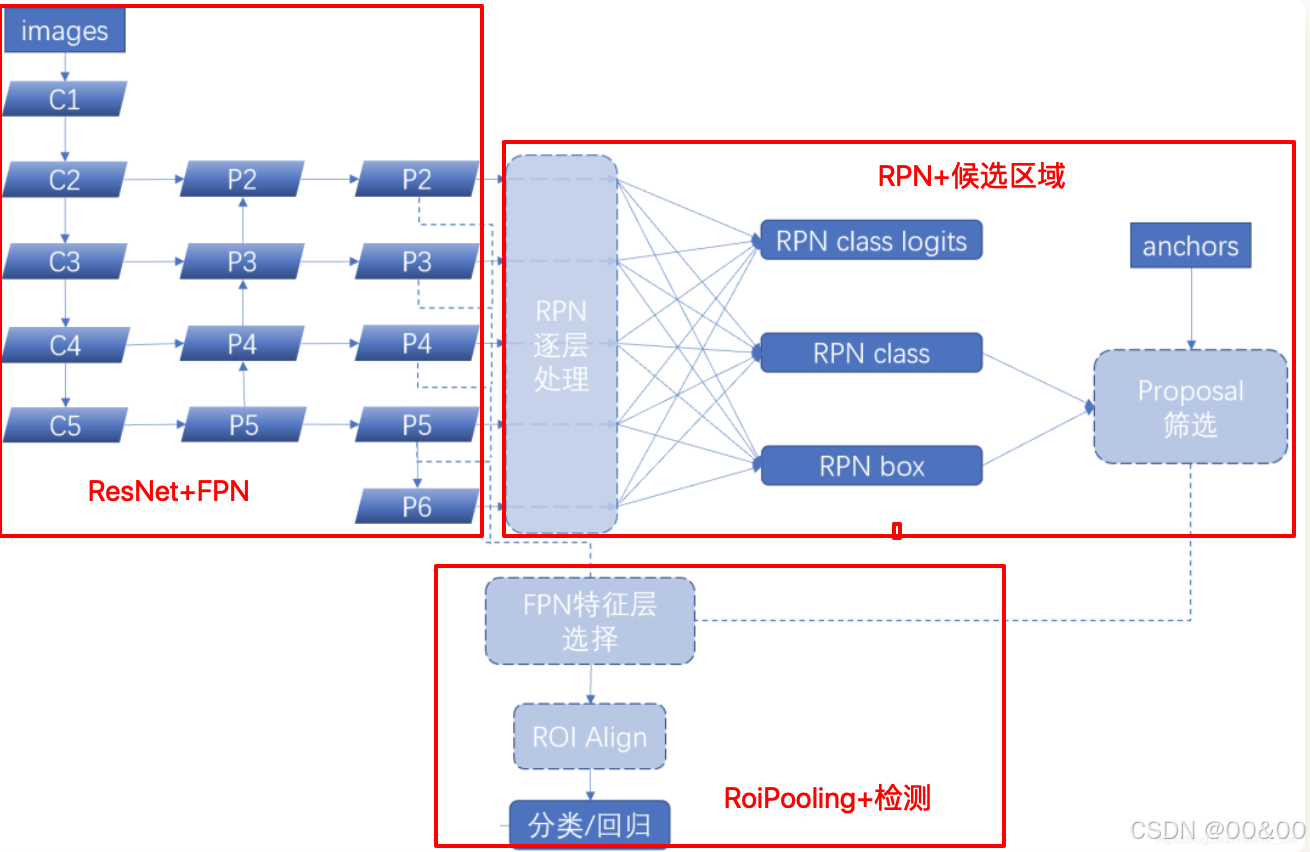
RPN 通过端到端的学习方法有效提升了候选区域的生成效率,省去了传统选择性搜索的时间开销。其设计不仅提高了检测速度,也确保了生成 RoIs 的质量。通过锚框、分类子网和回归子网的有效协作,使得 RPN 成为 Faster R-CNN 系统中不可或缺的部分,为目标检测任务奠定了基础。
三、RoI Pooling
在 Faster R-CNN 中,经过区域建议网络(RPN)生成候选区域(RoIs)后,接下来的处理步骤是使用 RoI Pooling 操作将这些候选区域映射到固定大小的特征图(通常为 7x7)。这一步的目的是为了统一处理不同尺寸的区域,确保后续的分类和回归层可以正常工作。
1. RoI Pooling 的目的
不变性:
在目标检测任务中,候选区域通常会有不同的大小和纵横比。为了让后续的模型部分(如全连接层)能够处理这些不同尺寸的特征,RoI Pooling 将所有候选区域的尺寸规范化为相同的大小(如 7x7)。这样,模型在输入数据时就不再受区域的尺寸影响,保证了模型的稳定性和一致性。
最大池化:
RoI Pooling 操作通过最大池化在每个候选区域内部提取出最显著的特征。这种方法可以有效地从候选区域中抓取重要信息,并在一定程度上减少信息的损失,同时保持特征图的空间结构,增强了模型的鲁棒性。
2. 如何实现 RoI Pooling
步骤1 输入特征图:
首先,模型将整个图像提供的特征图作为输入,它的尺寸通常大于候选区域的最大尺寸。例如,特征图的尺寸可能为。
步骤2 区域坐标:
RPN 输出的一组候选区域的坐标(通常为 x_min, y_min, x_max, y_max),这些坐标指示了在特征图中每个 RoI 的位置。
步骤3 划分:
对于每个候选区域,RoI Pooling 将该区域划分为的网格(通常
),并计算特征图在这些划分区域内的最大值。例如,将一个候选区域读取到特征图中,然后根据既定的 RoI 尺寸(如 7x7),将该区域均匀分成 7 行 7 列。
步骤4 最大值选择:
在划分出的每个小区域内,通过最大池化操作选择最大值,替换相应的网格位置。最终输出为一个的固定大小的特征图。示例代码:
这里是一个 RoI Pooling 的伪代码实现。
def roi_pooling(feature_map, rois, output_size):
pooled_features = []
for roi in rois:
x1, y1, x2, y2 = roi # 提取 RoI 的边界框坐标
roi_feature = feature_map[y1:y2, x1:x2] # 提取 RoI 区域的特征
# 将 RoI 区域划分为 output_size (通常是 7x7)
pooled_roi = []
bin_h = (y2 - y1) / output_size[0]
bin_w = (x2 - x1) / output_size[1]
for i in range(output_size[0]):
for j in range(output_size[1]):
pooled_roi.append(
roi_feature[int(i * bin_h):(int((i + 1) * bin_h)),
int(j * bin_w):(int((j + 1) * bin_w))].max()
)
pooled_features.append(pooled_roi)
return np.array(pooled_features).reshape(-1, output_size[0], output_size[1])3. RoI Pooling 的输出
输出格式:
RoI Pooling 的输出是一个固定大小的特征图(如),可以直接输入到后续的分类和回归层中。这一过程确保即使来自不同大小候选区域的特征向量长度相同,从而使得后续处理更加高效。
特征传递:
每个 RoI 经过 RoI Pooling 后,生成的 特征图代表了该区域的综合特征,并通过全连接层进行分类和边界框回归。这些处理使得检测模型能够更精准地对每个候选区域进行分析。
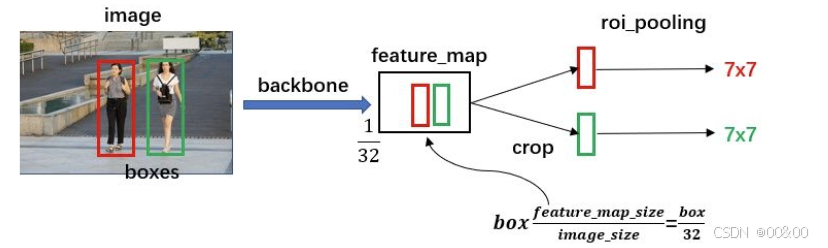
RoI Pooling 是 Faster R-CNN 中一个至关重要的组成部分,通过将候选区域映射到固定大小的特征图,解决了不同尺寸区域的处理问题。其利用最大池化技术提取最显著的特征,使得后续的分类和回归层能够高效且稳定地进行操作。这一过程不仅保证了输入的统一性,还增强了模型对各种目标的检测能力。
四、分类与回归层
在 Faster R-CNN 中,经过 RoI Pooling 的特征图被送入全连接层(Fully Connected Layers),进行两个关键任务:分类和边界框回归。这两个任务帮助网络首先识别输入图像中的目标类别,然后精确定位这些目标的边界框。
1. 分类层
功能:
分类层的主要目标是对每个候选区域(RoI)进行分类,输出每个 RoI 的类别概率分布。通常情况下,分类层会包含一个背景类和一个或多个目标类,旨在通过最大化每个候选区域的分类准确性,使模型能够区分不同类别的目标。
实现过程:
步骤1 Softmax 函数:
使用 Softmax 函数将全连接层的输出转化为每个类别的概率。Softmax 函数将任意实数输入转化为在(0,1)之间的概率值,使得所有类别的概率和为 1。
其中 是类别
的得分,
是给定输入
时,类别
的概率。
步骤2 损失函数:
样式采用交叉熵损失(Cross Entropy Loss)来评估分类性能,损失函数的目标是最小化预测概率和真实标签之间的差异。
其中是真实类别(0或1),及
是预测概率。 示例代码:
class ClassificationLayer(nn.Module):
def __init__(self, input_dim, num_classes):
super(ClassificationLayer, self).__init__()
self.fc1 = nn.Linear(input_dim, 1024)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(1024, num_classes) # 输出每个候选区域的类概率
def forward(self, x):
x = self.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1) # 计算每个类别的概率2. 边界框回归层
功能:
边界框回归层的任务是精确预测每个候选区域的真实边界框坐标。相对每个 RoI Pooling 输出的特征,回归层会输出一个回归值,表示该 RoI 的边界框坐标的偏移量。通过学习这些偏移量,模型能够生成更精确的目标框。
实现过程:
步骤1 坐标预测:
回归层的输出通常包含四个值,它们对应于确定的坐标(x, y, width, height)的偏移量。通过计算这些偏移量,模型能够调整初步预测的边界框位置。
其中是锚框的坐标,
是经过训练学习到的值。
步骤2 损失函数:
回归层通常采用平滑L1损失(Smooth L1 Loss)来优化回归精度。平滑L1损失在真实框和预测框之间较小的误差时采用L1损失,在误差较大时趋向于L2损失,确保训练过程的稳定性。
其中 是真实坐标,
是预测坐标。**示例代码**:
class ClassificationLayer(nn.Module):
def __init__(self, input_dim, num_classes):
super(ClassificationLayer, self).__init__()
self.fc1 = nn.Linear(input_dim, 1024)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(1024, num_classes) # 输出每个候选区域的类概率
def forward(self, x):
x = self.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1) # 计算每个类别的概率3. 分类与回归的联合作用
联合损失:
分类层和回归层的损失通常是联合被优化的,即通过最大化分类损失与回归损失的加权和来训练模型。整体损失函数可以表示为:
其中是权重系数,用于平衡分类损失和回归损失的重要性。
训练过程:
通过反向传播算法,分别计算分类层与回归层的梯度并更新参数,使得模型在预测分类与定位目标时更加准确。
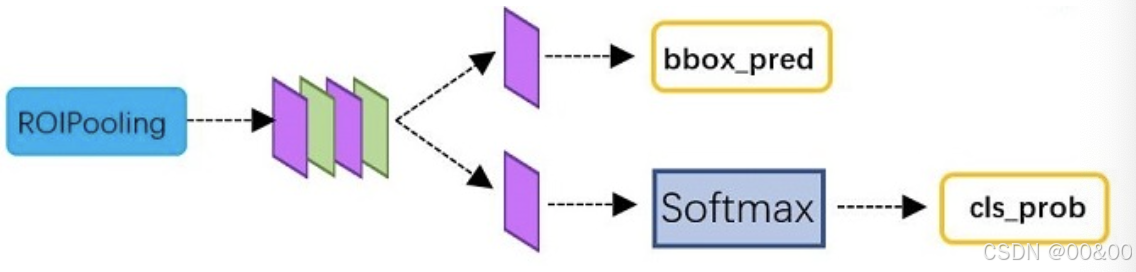
在 Faster R-CNN 中,分类层和边界框回归层是结合 RoI Pooling 输出后的关键部分。分类层通过 Softmax 函数确定每个候选区域所属的类别,而回归层则精细调整边界框以提高目标检测的精确性。它们通过最小化联合损失来共同优化模型,使其能够准确识别和定位物体,从而有效提升整体检测性能。
五、总结
Faster R-CNN 的结构设计通过结合特征提取、候选区域生成、RoI处理以及目标分类和回归,大幅提高了目标检测的速度和精度。每个组成部分相辅相成,使得整个模型能够有效处理复杂的视觉场景,广泛应用于自动驾驶、视频监控和智能医疗等领域。


















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











