






 本文介绍了一种结合两流卷积网络与残差网络的技术,通过时空交互和时间残差连接,增强了视频动作识别的深度学习模型。新架构在ImageNet和UCF101基准上超越了先前的最佳成果,展示了在端到端训练中学习复杂时空特征的能力。
本文介绍了一种结合两流卷积网络与残差网络的技术,通过时空交互和时间残差连接,增强了视频动作识别的深度学习模型。新架构在ImageNet和UCF101基准上超越了先前的最佳成果,展示了在端到端训练中学习复杂时空特征的能力。
摘要
双流卷积网络(ConvNets)在视频中人的动作识别方面表现出了强大的性能。最近,残差网络(ResNets)作为一种训练极深架构的新技术出现了。本论文介绍了这两种方法的组合时空ResNets。新架构通过两种方式引入残差连接,概括了时空域的ResNets。首先,在two-stream结构的外观和运动路径之间注入残差连接,允许two-stream之间的时空交互。其次,通过为其配备可学习的卷积滤波器将预先训练的图像卷积网络转换为时空网络,卷积滤波器初始化为时间残差连接,并及时对相邻的特征图进行操作。这种方法随着模型深度的增加而慢慢增加时空接受域,并自然地整合了图像ConvNet设计原则。整个模型是端到端的训练,允许分层学习复杂的时空特征。使用两个广泛被采用的动作识别基准来评估本论文的新时空ResNets网络,在这两个基准上,它超过了以前的最先进水平。
1 介绍
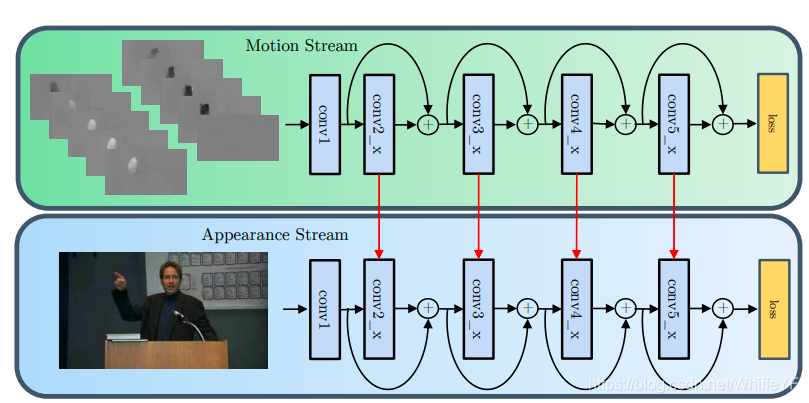
图一 本论文的方法是在two-stream ConvNet模型[20]中的引入残差连接。这两个网络分别捕捉空间(外观)和时间(运动)信息来识别输入序列。本论文不使用从空间到时间流的残差,因为这会使损失偏向于外观信息。
我们在 two-stream方法[20]的基础上进行构建,这两种方法采用了两个独立的ConvNet流,一个是空间外观流,它实现了来自RGB图像的最先进的动作识别,另一个是时间运动流,它在光流信息上运行。two-stream 结构是受到神经科学的two-stream假说的启发[6],神经科学的two-stream假说是指两个视觉皮层通路:
- The ventral pathway:它对空间特征有反应,如物体的形状或颜色等特性。
- The dorsal pathway:它对物体的转换和空间关系敏感,如物体发生运动。
我们用以下方法扩展 two-stream 卷积网络。
- 首先,由于残差网络(ResNets)[8]最近在ImageNet和MSCOCO等数据集上成功地完成了许多具有挑战性的识别任务,我们将ResNets应用于视频中的人类动作识别任务。在这里,用预先训练好的图像分类网[8]初始化模型,利用大量基于图像的训练数据来完成视频中的动作识别任务。
- 其次,本论文证明了在 two-stream之间加入残差连接(见图1)并共同微调得到的模型可以在 two-stream 结构上提高性能。
- 第三,本论文克服了原 two-stream方法中有限的时间感受野大小,通过扩展模型在时间上的尺度。
将卷积维数映射滤波器转换为时间滤波器,随时间推移为网络提供可学习的残余连接。通过叠加几个时间滤波器,并对输入序列进行大时间步长(即跳跃帧)采样,可以使网络在输入的大时间范围内运行。为了证明本论文提出的时空残差体系结构的好处,本论文在两个标准动作识别基准上对其进行了评估,在这两个基准上,它极大地促进了最先进的技术。
3. 技术方法
3.1 Two-Stream residual 网络
本论文使用深度ResNets[8,9]。这些网络的设计类似于VGG网络[21],带有小型的
3
×
3
3\times3
3×3空间滤波器(第一层除外),并且类似于Inception 网络[23],带有
1
×
1
1\times1
1×1滤波器,用于学习维度的缩减和扩展。该网络的输入大小为
224
×
224
224\times224
224×224,通过步长为2的卷积在网络中减少了5倍,然后是
7
×
7
7\times7
7×7特征图的全局平均池化层,以及使用softmax的全连接分类层。每次特征图的空间大小发生变化,特征的数量就会增加一倍,以避免紧瓶颈。每次卷积后应用批处理归一化[11]和ReLU [14];网络不使用隐藏的fc、dropout或max-pooling(除非紧接在第一层之后)。残差单位定义为[8,9]
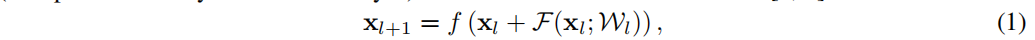
X
l
X_l
Xl和
X
l
+
1
X_{l+1}
Xl+1是第
l
l
l层的输入和输出,
F
F
F是用权重
W
l
=
{
W
l
,
k
∣
1
≤
k
≤
K
}
W_l=\{W_{l,k}|1\le k\le K\}
Wl={Wl,k∣1≤k≤K}和
K
∈
{
2
,
3
}
K\in\{2,3\}
K∈{2,3} 和
F
≡
R
e
L
u
F\equiv ReLu
F≡ReLu 来表示非线性残差映射。残差单元的一个关键优点是它们的跳跃连接允许信号从网络的第一层直接传播到最后一层。特别是在反向传播期间,这种安排是有利的:梯度直接从 Loss 层传播到任何先前的层,同时跳过可能触发梯度信号消失或恶化的中间权值层。
我们还利用了 two-stream结构[20]。对于这两个流,我们使用在ImageNet数据集上预训练的ResNet-50模型[8],并根据目标数据集中的类数替换最后一层(分类)。在运动流的第一层的过滤器被进一步修改,通过复制三个大小为 2 L = 20 2L = 20 2L=20的RGB滤波通道来操作水平和垂直光流堆栈,每个都有一个L = 10帧的堆栈。这个策略允许我们利用大量带标注的训练数据用于两个流。
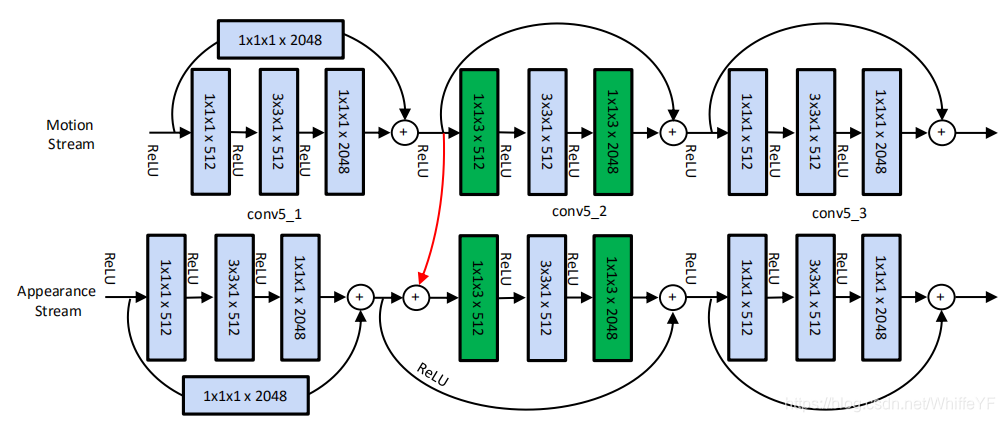
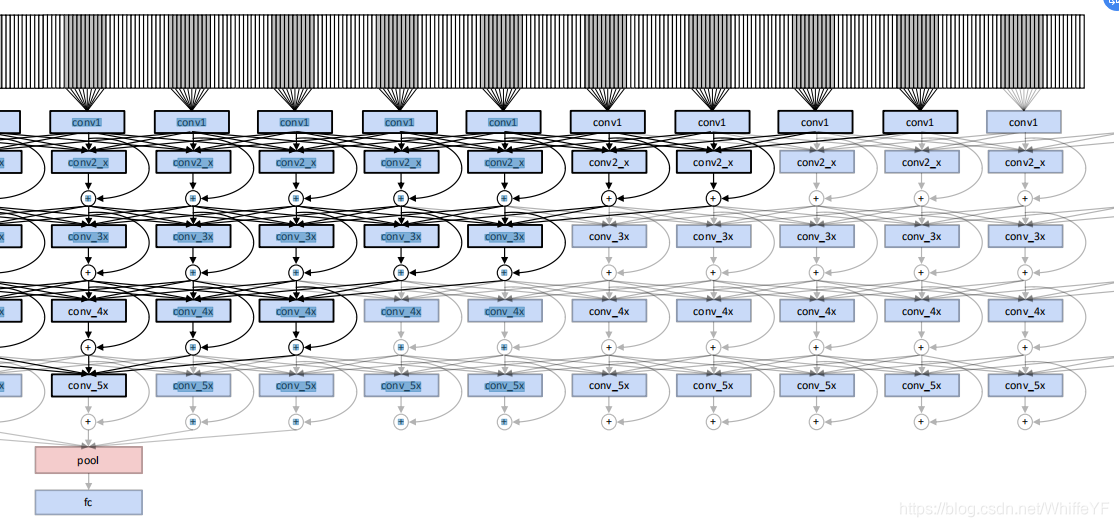
图2,conv5_x residual单元的结构。 two streams之间的残差连接(红色突出显示)使运动交互成为可能。第二个残差单元conv5_2还包括时间卷积(绿色突出显示),用于学习抽象时空特征。
two-stream 结构的一个缺点是它不能在时空上记录外观和运动信息。因此,它不能表示什么(被空间流捕获)以什么方式移动(被时间流捕获)。在这里,本论文通过让网络在几个时空尺度上学习这种时空线索来弥补这一缺陷。本论文通过在 two streams之间引入残差连接来实现这种交互。正如在一个ResNet中可以有各种类型的快捷连接一样, two streams也可以有多种连接方式。在前期的实验中,本论文发现two streams的相同层之间的直接连接会导致验证错误的增加。同样,双向连接显著增加了验证错误。本论文推测,这些结果是由于一个网络流注入融合信号后,另一个网络流的信号发生了巨大的变化。因此,本论文开发了一个更微妙的替代解决方案,基于相加的相互作用,如下所示。
运动残差(Motion Residuals)
本论文从动作流注入一个跳跃连接到外观流的残差单元。为了能够学习所有可能尺度下的时空特征,在网络的每个空间分辨率的第二个残差单元(由表1中的skip-stream表示)之前应用此修改,如图2中的conv5_x层连接所示。形式上,对相应的外观流残差单元(1)进行修改
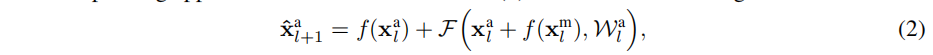
其中
x
l
+
1
a
x^a_{l+1}
xl+1a为第
l
l
l层外观流的输入,
x
l
m
x^m_{l}
xlm为第
l
l
l层运动流的输入,
W
l
a
W^a_{l}
Wla为第
l
l
l层在外观流中残差单位的权值,对于损失函数
L
L
L在后向传递中的梯度,链式法则产生
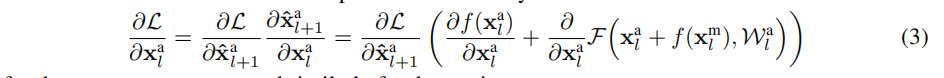
对于外观流和类似的对于动作流
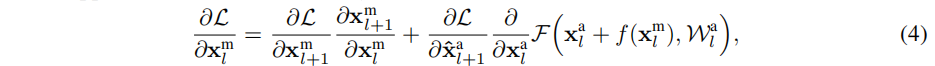
式中(4)的第一项加性为运动流中第
l
l
l层的梯度,第二项累加来自于外观流的梯度。因此,流之间的残差连接将梯度从外观流反向传播到运动流。
3.2跨时间的卷积剩余连接
在处理时变的视觉数据时,时空一致性是一个重要的线索,可以利用无监督方式[7]从视频中学习一般表示。在这种情况下,时间平滑性是一个重要的属性,它要求特征随时间缓慢变化。此外,可以预期,在许多情况下,ConvNet会在不同时间捕获相似的特性。例如,具有重复动作模式(如锤击)的动作会随着时间的推移触发外观和动作流的相似特征。在这种情况下,使用时间残差连接将是非常有意义的。然而,对于外观或瞬时运动模式随时间变化的情况,残差连接将是判别学习的次优选择,因为总和运算随时间对应于低通滤波,并将平滑特征的潜在重要高频时间变化。此外,反向传播无法弥补这一缺陷,因为在总和层,从输出到输入连接的所有梯度都是平均分布的。
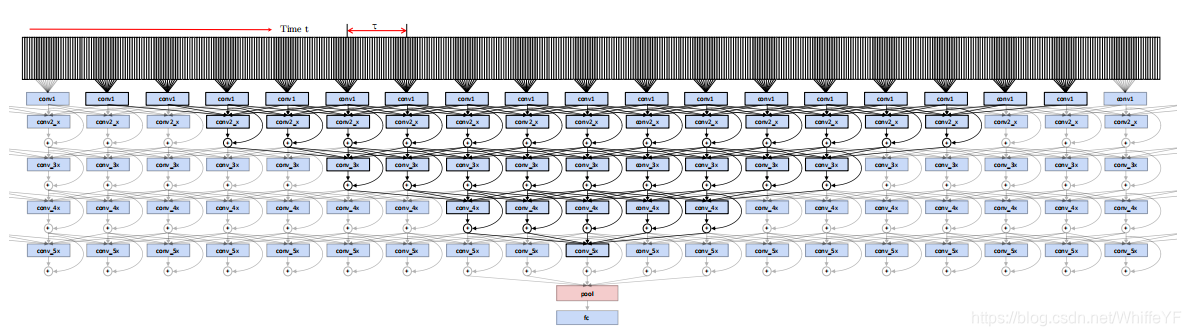
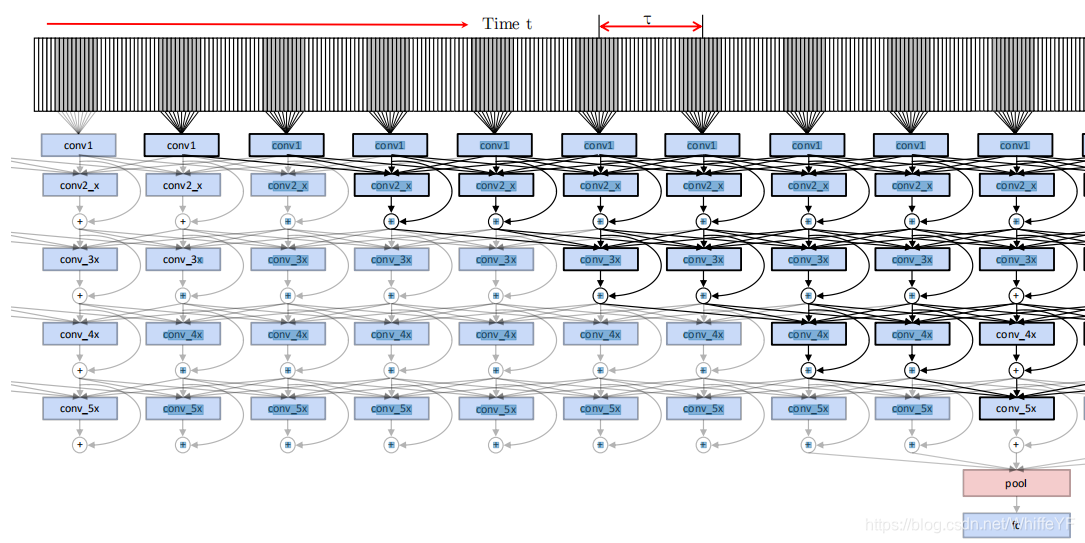
图3:本论文的运动网络流的第5个 meta 层的单个神经元的感受野被突出显示。
τ
τ
τ表示输入之间的时间步长。conv5_3的输出在时间上是max-pooling,并feed to ST-ResNet*的全连接层。
基于上述观察,本论文开发了一种新的时间残差连接方法,该方法建立在连接小型[21]非对称滤波器的ConvNet设计指南[10,23]上,见第一节。通过将残差路径中的空间维度映射滤波器转换为时间滤波器,本论文使用时间卷积扩展了ResNet架构。这允许直接使用在大规模数据集上预先训练过的标准双流convnet,例如利用ImageNet挑战的大量训练数据。本论文将时间权值初始化为跨时间的残差连接,并通过反向传播让网络学习最好地来区分图像动态。本论文通过在预先训练的ResNets 中跨时间复制学习到的
1
×
1
1\times1
1×1维空间映射核来实现这一点。给定预先训练好的空间权值,对
w
l
∈
R
1
×
1
×
C
w_l\in R^{1\times 1 \times C}
wl∈R1×1×C、时域滤波器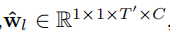
进行初始化
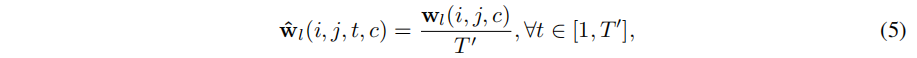
然后通过backpropagation进行改进。在(5)中,除以T0表示在不同时间内的平均特征响应。我们从运动和外观ResNets 转换 过滤器,并相应地重新生成。因此,时间滤波器能够学习外观和运动特征的时间演化,而且,通过叠加滤波器,如网络的深度增加,复杂的时空关系可以建模。
3.3建议结构 (Proposed architecture)
批归一化[11]从所有激活中减去批均值,然后除以它们的方差。这些 moments 是通过平均空间位置和多幅图像批量估计的。批处理归一化后,应用一个学习到的、通道特定的仿射变换(缩放和偏差)。噪声偏置/方差估计代替了dropout正则化的需要[8,24]。本论文发现,减少用于批处理归一化的样本数量可以进一步提高模型的泛化性能。例如,对于外观流,本论文在训练期间使用4的低批量大小进行矩估计。这一实践强烈支持模型的泛化,并大大提高了验证的准确性(在UCF101上为4%)。有趣的是,与这种方法相比,在分类层之后使用dropout(例如在[24]中)降低了外观流的验证准确性。注意,只有规格化激活的批大小减少了;随机梯度下降法的批大小不变。

表1:在两个 ConvNet streams 中使用的时空ResNet结构。metalayers 在列中显示,它们的构建块在括号中显示卷积滤波器的尺寸
(
W
×
H
×
T
,
C
)
(W\times H\times T, C)
(W×H×T,C)。括号中显示的每个构建块也有一个到下面的块的跳跃连接,而skip-stream表示从动作到外观流的残差连接,例如,图2中的conv5_2构建块。步长为2的下采样由conv1、pool1、conv3_1、conv4_1和conv5_1执行。这些层的输出和感受野大小如下所示。对于两个流,pool5层后面是一个
1
×
1
×
1
×
2048
1\times1\times1\times2048
1×1×1×2048全连接层,一个softmax层和一个Loss。
参考文献
[6] M. A. Goodale and A. D. Milner. Separate visual pathways for perception and action. Trends in Neurosciences, 15(1):20–25, 1992.
[7] Ross Goroshin, Joan Bruna, Jonathan Tompson, David Eigen, and Yann LeCun. Unsupervised feature learning from temporal data. In Proc. ICCV, 2015.
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition.arXiv preprint arXiv:1512.03385, 2015.
[9] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks.arXiv preprint arXiv:1603.05027, 2016.
[10] Yani Ioannou, Duncan Robertson, Jamie Shotton, Roberto Cipolla, and Antonio Criminisi. Training cnns with low-rank filters for efficient image classification. In Proc. ICLR, 2016.
[11] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proc. ICML, 2015.
[14] A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012.
[21] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In Proc. ICLR, 2014.
[23] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. arXiv preprint arXiv:1512.00567, 2015.
参考
Spatiotemporal Residual Networks for Video Action Recognition
双流网络行为识别-Spatiotemporal Residual Networks for Video Action Recognition-论文阅读


















 7697
7697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











