






目录
0 资料
【数据集微调】
阿里天池比赛 微调BERT的数据集(“任务1:OCNLI–中文原版自然语言推理”)
数据集地址:https://tianchi.aliyun.com/competition/entrance/531841/information
由于这个比赛已经结束,原地址提交不了榜单看测试结果,请参照下面的信息,下载数据集、提交榜单测试。
-
“任务1:OCNLI–中文原版自然语言推理”数据集的GitHub地址:https://github.com/CLUEbenchmark/OCNLI
-
榜单提交步骤:
- 打开“榜单提交地址”,点击“立即测评”——填写相关信息(github地址填https://github.com/CLUEbenchmark/CLUE,其他信息任意填)。
- 上传一个.zip压缩文件,在压缩文件里存放我们模型预测结果的文件。
- 点击提交。
-
【注意】预测结果文件的格式:https://storage.googleapis.com/cluebenchmark/tasks/clue_submit_examples.zip
15.4. 自然语言推断与数据集:https://zh-v2.d2l.ai/chapter_natural-language-processing-applications/natural-language-inference-and-dataset.html
15.7. 自然语言推断:微调BERT:https://zh-v2.d2l.ai/chapter_natural-language-processing-applications/natural-language-inference-bert.html#id3
保姆级教程,用PyTorch和BERT进行文本分类:https://zhuanlan.zhihu.com/p/524487313
b站视频:
https://www.bilibili.com/video/BV1rz421279G/
1 预训练权重
在国内,一般是手动下载预训练权重,而非网络自动下载。
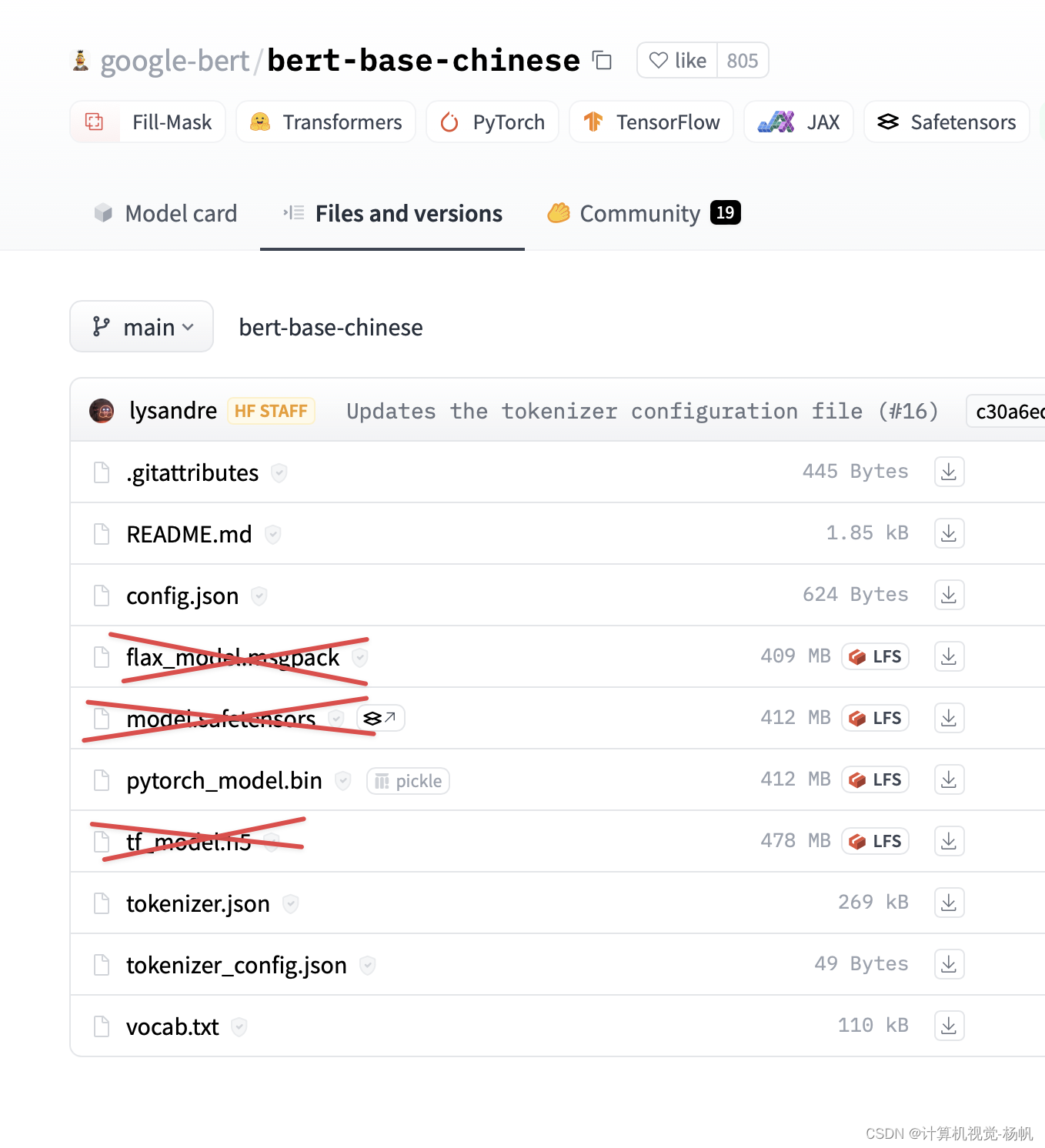
我们将用到 chinese-macbert-base 这个预训练文件,下载网址如下:
https://huggingface.co/hfl/chinese-macbert-base/tree/main
除了叉掉的,其余都要下载。
2 wandb
pip install wandb
WandB 是一个用于实验跟踪、版本控制和结果可视化的工具,主要用于机器学习项目。
wandb使用教程(一):基础用法:https://zhuanlan.zhihu.com/p/493093033
3 Bert-OCNLI
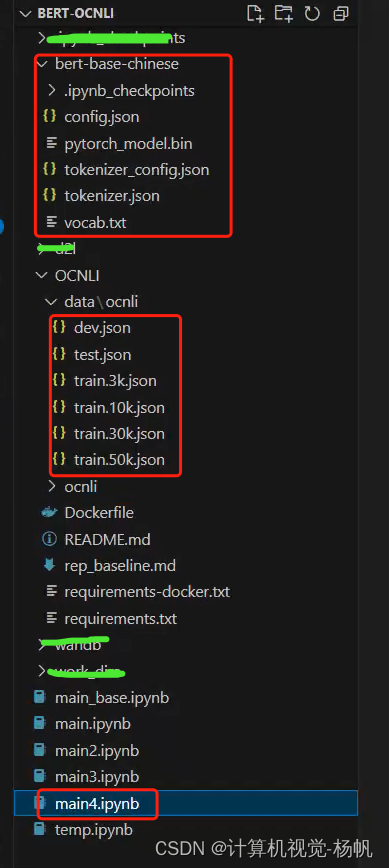
3.1 目录结构
3.2 导入的库
import os
import torch
from torch import nn
import pandas as pd
from transformers import BertModel, BertTokenizer
from torch.optim import Adam
from tqdm import tqdm
3.3 数据集
自然语言推断
自然语言推断(natural language inference)主要研究 假设(hypothesis)是否可以从前提(premise)中推断出来, 其中两者都是文本序列。 换言之,自然语言推断决定了一对文本序列之间的逻辑关系。这类关系通常分为三种类型:
蕴涵(entailment):假设可以从前提中推断出来。
矛盾(contradiction):假设的否定可以从前提中推断出来。
中性(neutral):所有其他情况。
自然语言推断也被称为识别文本蕴涵任务。 例如,下面的一个文本对将被贴上“蕴涵”的标签,因为假设中的“表白”可以从前提中的“拥抱”中推断出来。
前提:两个女人拥抱在一起。
假设:两个女人在示爱。
下面是一个“矛盾”的例子,因为“运行编码示例”表示“不睡觉”,而不是“睡觉”。
前提:一名男子正在运行Dive Into Deep Learning的编码示例。
假设:该男子正在睡觉。
第三个例子显示了一种“中性”关系,因为“正在为我们表演”这一事实无法推断出“出名”或“不出名”。
前提:音乐家们正在为我们表演。
假设:音乐家很有名。
自然语言推断一直是理解自然语言的中心话题。它有着广泛的应用,从信息检索到开放领域的问答。为了研究这个问题,我们将首先研究一个流行的自然语言推断基准数据集。
数据集路径
# 数据集路径
data_dir = 'OCNLI/data/ocnli'
读取数据集
# 读ocnli,两个参数,data_dir是数据集的路径,is_train为bool类型,True代表训练,False代表验证
def read_ocnli(data_dir, is_train):
# 将ocnli解析为前提、假设、标签
# labels_map是标签映射,0、1、2代表三类,3代表无法分类(或者应该去除的数据)。
labels_map = {'entailment':0, 'neutral':1, 'contradiction':2, '-': 3}
file_name = os.path.join(data_dir, 'train.3k.json' if is_train else 'dev.json')
rows = pd.read_json(file_name, lines=True)
premises = [sentence1 for sentence1 in rows['sentence1'] ] # 前提
hypotheses = [sentence2 for sentence2 in rows['sentence2'] ] # 假设
# if label != '-' 是为了去除无法分类的标签
labels = [labels_map[label] for label in rows['label'] if label != '-'] # 标签
return premises, hypotheses, labels
数据集样例展示
# 样例展示
train_data = read_ocnli(data_dir, is_train=True)
for x0, x1, y in zip(train_data[0][:3], train_data[1][:3], train_data[2][:3]):
print("前提:", x0)
print("假设:", x1)
print("标签:", y)
结果:
前提: 现在,我代表国务院,向大会报告政府工作,请予审议,并请全国政协委员提出意见
假设: 全国政协委员无权提出建议
标签: 2
前提: 不过以后呢,两年增加一次工资.
假设: 多年之后工资很高
标签: 1
前提: 一万块,嗯那头盔要八千.
假设: 说话的人很有钱
标签: 1
数据集类别统计
# 类别数据统计
val_data = read_ocnli(data_dir, is_train=False)
label_set = [0, 1, 2]
for data in [train_data, val_data]:
print([
[
row for row in data[2]
].count(i) for i in label_set
])
结果:
[974, 1054, 966]
[947, 1103, 900]
数据集类
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
class OCNLI_Dataset(torch.utils.data.Dataset):
def __init__(self, dataset):
sentence1 = [sentence1 for sentence1 in dataset[0]]
sentence2 = [sentence2 for sentence2 in dataset[1]]
# 用 _ 将前提和假设拼接在一起,但这应该不是好的做法
sentence1_2 = ['{}_{}'.format(a, b) for a, b in zip(sentence1, sentence2)]
self.texts = [tokenizer(
sentence,
padding='max_length',
# bert最大可以设置到512,对OCNLI的统计计算中,
# 发现所有数据没有超过128,max_length越大,计算量越大
max_length = 128,
truncation=True,
return_tensors="pt"
) for sentence in sentence1_2 ]
self.labels = torch.tensor(dataset[2])
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return self.texts[idx], self.labels[idx]
加载数据
train_set = OCNLI_Dataset(read_ocnli(data_dir, True))
test_set = OCNLI_Dataset(read_ocnli(data_dir, False))
print(len(train_set))
# for train_input, train_label in train_set:
# print(train_input)
# print(train_label)
# input()
结果:
3000
3.4 Bert
class BertClassifier(nn.Module):
def __init__(self, dropout=0.5):
super(BertClassifier, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-chinese')
self.dropout = nn.Dropout(dropout)
self.linear = nn.Linear(768, 3) # 这里的3代表输出的类别
self.relu = nn.ReLU()
def forward(self, input_id, mask):
_, pooled_output = self.bert(input_ids= input_id, attention_mask=mask,return_dict=False)
dropout_output = self.dropout(pooled_output)
linear_output = self.linear(dropout_output)
final_layer = self.relu(linear_output)
return final_layer
3.4 训练
def train(model, train_data, val_data, learning_rate, epochs):
# 通过Dataset类获取训练和验证集
train, val = OCNLI_Dataset(train_data), OCNLI_Dataset(val_data)
# DataLoader根据batch_size获取数据,训练时选择打乱样本
train_dataloader = torch.utils.data.DataLoader(train, batch_size=32, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=32)
# 判断是否使用GPU
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=learning_rate)
if use_cuda:
model = model.cuda()
criterion = criterion.cuda()
# 开始进入训练循环
for epoch_num in range(epochs):
# 定义两个变量,用于存储训练集的准确率和损失
total_acc_train = 0
total_loss_train = 0
# 进度条函数tqdm
for train_input, train_label in tqdm(train_dataloader):
train_label = train_label.to(device)
mask = train_input['attention_mask'].to(device)
input_id = train_input['input_ids'].squeeze(1).to(device)
# 通过模型得到输出
output = model(input_id, mask)
# 计算损失
batch_loss = criterion(output, train_label)
# input()
total_loss_train += batch_loss.item()
# print("total_loss_train:",total_loss_train)
# 计算精度
acc = (output.argmax(dim=1) == train_label).sum().item()
total_acc_train += acc
# 模型更新
model.zero_grad()
batch_loss.backward()
optimizer.step()
# ------ 验证模型 -----------
# 定义两个变量,用于存储验证集的准确率和损失
total_acc_val = 0
total_loss_val = 0
# 不需要计算梯度
with torch.no_grad():
# 循环获取数据集,并用训练好的模型进行验证
for val_input, val_label in val_dataloader:
# 如果有GPU,则使用GPU,接下来的操作同训练
val_label = val_label.to(device)
mask = val_input['attention_mask'].to(device)
input_id = val_input['input_ids'].squeeze(1).to(device)
output = model(input_id, mask)
batch_loss = criterion(output, val_label)
total_loss_val += batch_loss.item()
acc = (output.argmax(dim=1) == val_label).sum().item()
total_acc_val += acc
print(
f'''Epochs: {epoch_num + 1}
| Train Loss: {total_loss_train / len(train): .3f}
| Train Accuracy: {total_acc_train / len(train): .3f}
| Val Loss: {total_loss_val / len(train): .3f}
| Val Accuracy: {total_acc_val / len(train): .3f}''')
print("total_loss_train:",total_loss_train)
print("total_acc_train:",total_acc_train)
print("total_loss_val:",total_loss_val)
print("total_acc_val:",total_acc_val)
print("len(train_data):",len(train))
EPOCHS = 50
model = BertClassifier()
LR = 1e-6
train(model, read_ocnli(data_dir, True), read_ocnli(data_dir, False), LR, EPOCHS)
















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









