








 超级会员免费看
超级会员免费看


大语言模型-教育方向数据集
| 编号 | 论文 | 数据集 | 样例 |
|---|---|---|---|
| 1 | Bitew S K, Hadifar A, Sterckx L, et al. Learning to Reuse Distractors to Support Multiple-Choice Question Generation in Education[J]. IEEE Transactions on Learning Technologies, 2022, 17: 375-390. | Televic, NL, https://github.com/semerekiros/dist-retrieval/tree/main/test-MCQs | 主要为荷兰语 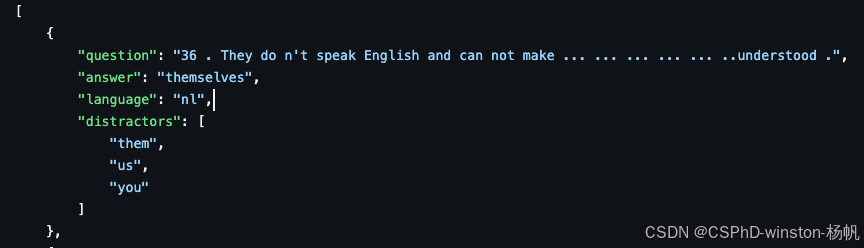 |
| 2 | AAAI 2020 QASC 问答数据集13小学科学选择题,每个问题包含8个选项,一个正确答案 数据集介绍 QA |

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











