







支持向量机
Support Vector Machine(SVM)
-
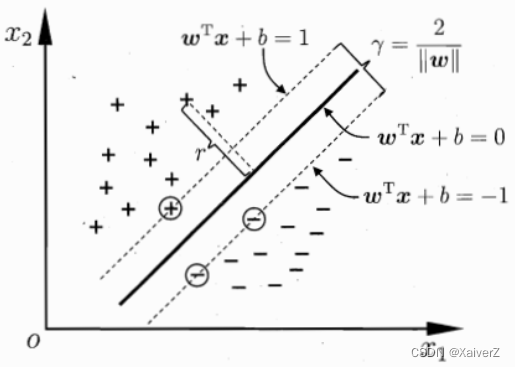
距离超平面最近的这几个训练样本点使等号成立,它们被称为“支持向量”
-
求解SVM最优化:SMO(Sequential Minimal Optimization)
核函数
-
上述例子在二维平面上,训练样本假设是线性可分的,然而在现实任务中,原始样本空间可能本身就线性不可分,所以可以将原始空间映射到一个更高维的特征空间,使得样本在这个特征空间线性可分
- 如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分
-
由于SVM最优化涉及计算映射到高维空间后的样本向量的点积,由于特征空间维数可能很高,因此直接计算比较困难,故设计了核函数,避免直接计算高维向量内积
κ ( x i , x j ) = ⟨ ϕ ( x i ) , ϕ ( x j ) ⟩ = ϕ ( x i ) T ϕ ( x j ) \kappa\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\left\langle\phi\left(\boldsymbol{x}_{i}\right), \phi\left(\boldsymbol{x}_{j}\right)\right\rangle=\phi\left(\boldsymbol{x}_{i}\right)^{\mathrm{T}} \phi\left(\boldsymbol{x}_{j}\right) κ(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩=ϕ(xi)Tϕ(xj)
-
常用核函数

- 文本数据通常采用线性核,情况不明时先尝试高斯核(RBF)
软间隔支持向量机
Soft Margin
-
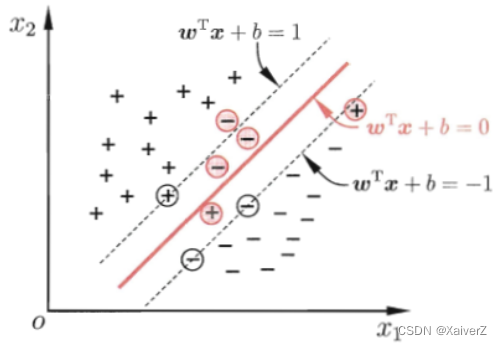
前述讨论假设存在超平面将样本完全分隔开,但往往很难找到这样的超平面,难免会有一些不满足条件的样本。缓解该问题的方法是允许SVM在一些样本上出错,为此引入“软间隔”概念。
-
在最大化间隔的同时,不满足约束的样本应尽可能少,优化目标可写为(采用Hinge Loss衡量不满足约束的样本误差)
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 m max ( 0 , 1 − y i ( w T x i + b ) ) \min _{\boldsymbol{w}, b} \frac{1}{2}\|\boldsymbol{w}\|^{2}+C \sum_{i=1}^{m} \max \left(0,1-y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)\right) w,bmin21∥w∥2+Ci=1∑mmax(0,1−yi(wTxi+b))
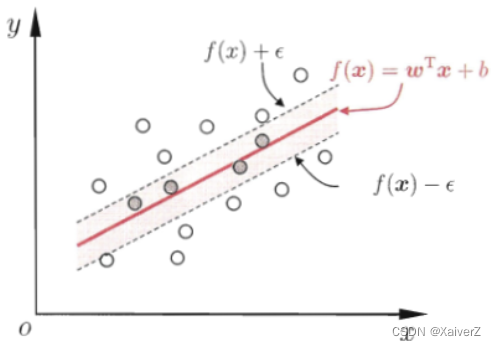
支持向量回归
Support Vector Regression,SVR
-
SVR仅当预测值与真实值之间的误差绝对值大于 ε ε ε时才计算损失
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 m ℓ ε ( f ( x i ) − y i ) \min _{\boldsymbol{w}, b} \frac{1}{2}\|\boldsymbol{w}\|^{2}+C \sum_{i=1}^{m} \ell_{ε}\left(f\left(\boldsymbol{x}_{i}\right)-y_{i}\right) w,bmin21∥w∥2+Ci=1∑mℓε(f(xi)−yi)
ℓ ε \ell_{ε} ℓε为ε-insensitive lossℓ ϵ ( z ) = { 0 , if ∣ z ∣ ⩽ ϵ ∣ z ∣ − ϵ , otherwise \ell_{\epsilon}(z)= \begin{cases}0, & \text { if }|z| \leqslant \epsilon \\ |z|-\epsilon, & \text { otherwise }\end{cases} ℓϵ(z)={0,∣z∣−ϵ, if ∣z∣⩽ϵ otherwise
核方法
使用核函数的学习方法
-
核线性判别分析
Kernelized Linear Discriminant Analysis,KLDA















 3066
3066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









