






1、StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
中文标题:StoryDiffusion:一致性自我注意力用于长距离图像和视频生成

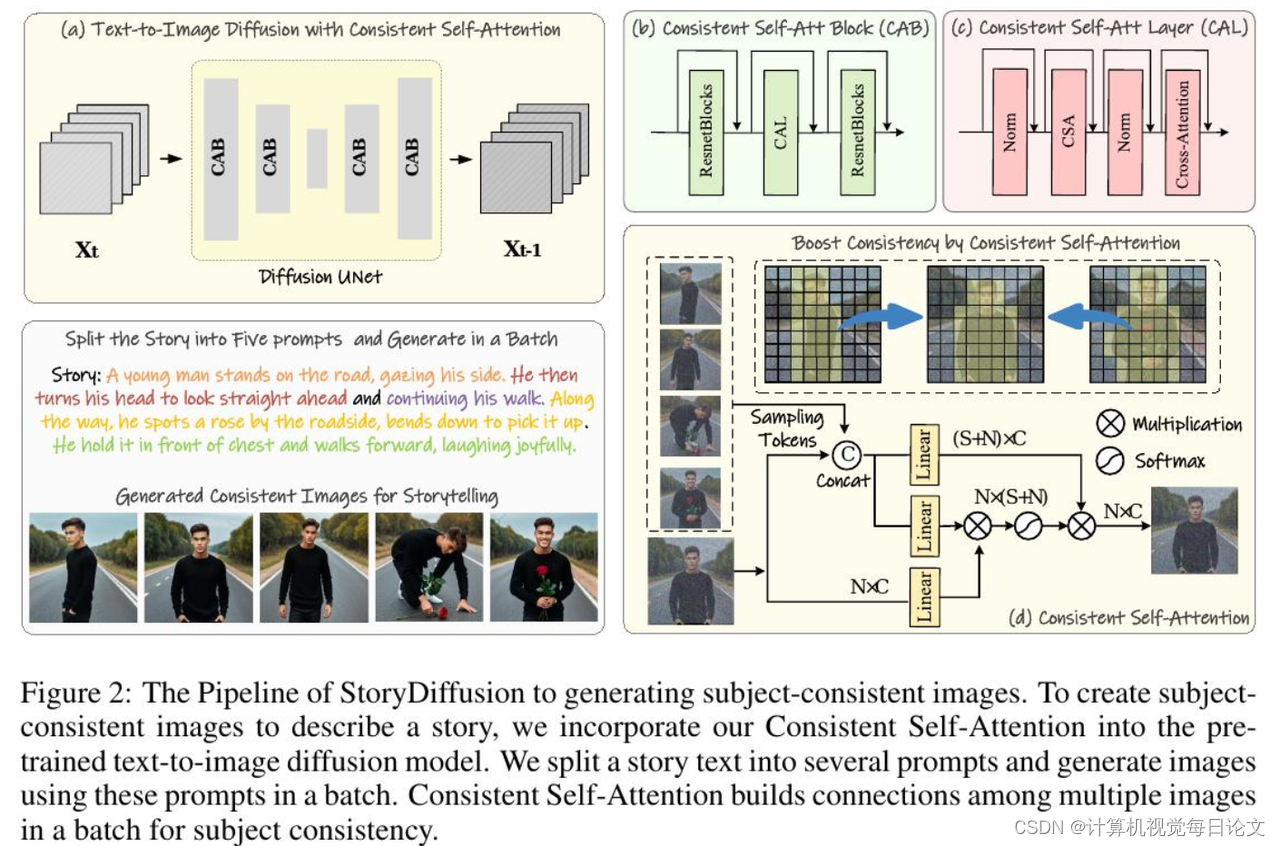
简介:该论文提出了一种名为"StoryDiffusion"的新方法,解决了长序列图像和视频生成中的一致性问题。其中包括两个关键创新:
"一致性自注意力机制"。这种新的自注意力计算方法能够显著提高生成图像的一致性,同时也可用于零样本增强预训练的扩散式文本到图像模型。
"语义空间时间运动预测器"。这是一种新的语义空间时间运动预测模块,可以将生成的图像序列转换为具有平滑过渡和一致主题的视频,特别对于长视频生成更加稳定。
将这两个新组件整合在"StoryDiffusion"框架中,可以使用一致的图像或视频描述基于文本的故事,生成丰富多样的内容。
该论文在视觉故事生成领域进行了开创性探索,希望能够激发更多从架构改进角度进行的研究。作者还公开了相关的代码实现。
2、AM-RADIO: Agglomerative Model -- Reduce All Domains Into One
中文标题:AM-RADIO: 凝聚模型 -- 将所有领域归并为一体

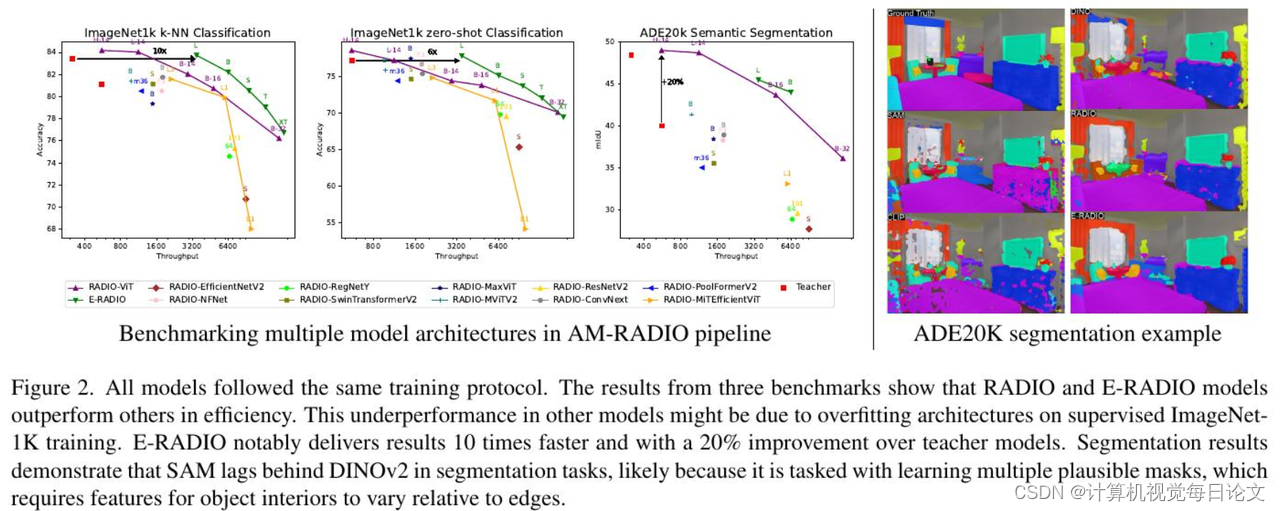
简介:近期出现了一些视觉基础模型(VFMs),成为许多下游任务的重要支撑。这些VFM,如CLIP、DINOv2和SAM,通过不同的训练目标展现了各自的特点,适用于不同的下游任务。尽管这些模型在概念上有所不同,但研究人员发现它们可以通过多教师蒸馏的方式有效融合为一个统一的模型。这种方法被称为AM-RADIO(聚合模型-将所有领域归并为一)。这种综合方法不仅超越了单个教师模型的性能,还融合了它们的独特特征,如零shot视觉语言理解、精细的像素级理解和开放词汇分割能力。为了追求最高效的硬件支持,研究人员评估了多种架构在多教师蒸馏管道中的表现,最终开发出了一种新颖的E-RADIO架构,其性能超越了前代模型,计算效率也至少是教师模型的7倍。这项工作进行了全面的基准测试,涵盖了ImageNet分类、ADE20k语义分割、COCO目标检测以及LLaVa-1.5等框架。相关代码已公开在GitHub上,供大家参考。
3、XFeat: Accelerated Features for Lightweight Image Matching
中文标题:XFeat: 加速轻量级图像匹配的特征


简介:本文提出了一种新的轻量级且高效的图像匹配架构,称为XFeat。主要特点如下:
重新审视了卷积神经网络在特征检测、提取和匹配方面的基本设计,满足了快速和稳健的算法在资源受限设备上使用的需求。
在保持足够大的图像分辨率的同时,限制了网络中的通道数,以提高效率。
提供了在稀疏或半密级别上进行匹配的选择,适用于不同的下游应用。
引入了一种新型的基于粗略局部描述符的匹配细化模块,能够高效地提供半密匹配。
性能方面,XFeat比当前基于深度学习的局部特征快5倍左右,准确性相当或更好,在姿态估计和视觉定位方面有所体现。
可以在普通笔记本电脑CPU上实时运行,无需专门的硬件优化。
总的来说,XFeat是一种通用且高效的轻量级图像匹配解决方案,代码和模型权重可在线上获取。
















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









