






SadTalker主页:https://github.com/Winfredy/SadTalker![]() https://github.com/Winfredy/SadTalker
https://github.com/Winfredy/SadTalker
1、安装NVIDIA cuda
2、安装 anaconda
3、项目下载和运行环境配置
(1)下载文件并解压
(2)命令行安装
#进入SadTalker项目目录
cd SadTalker
#创建一个python3.8名为sadtalker的虚拟环境
conda create -n sadtalker python=3.8
#激活名为sadtalker的虚拟环境
conda activate sadtalker
#pip切换到清华源提高下载速度
pip config set global.index-url Simple Index
#安装pytorch及相关包
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
pip install torch==2.4.1匹配python3.10环境
#安装视频处理工具ffmpeg
conda install ffmpeg
#安装项目相关依赖
pip install -r requirements.txt
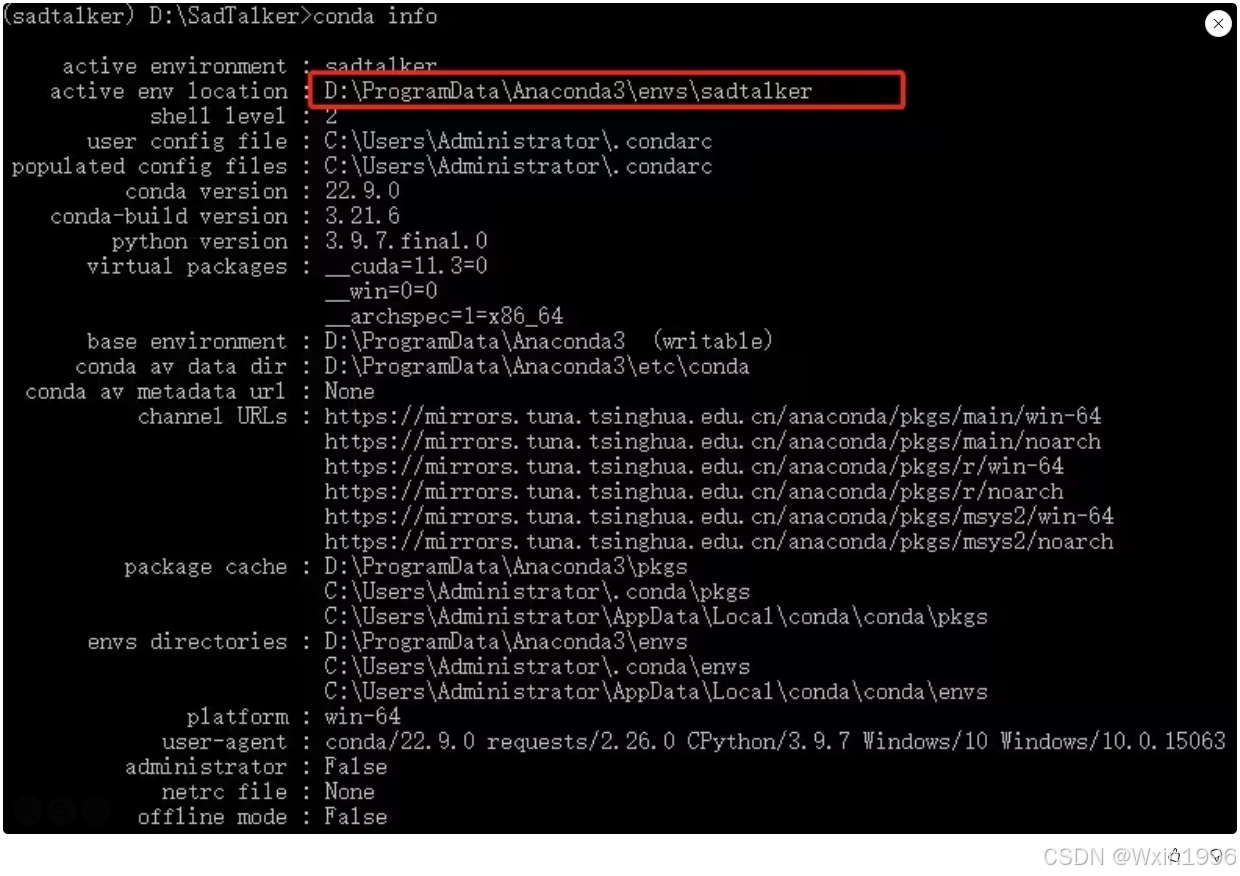
#在刚才的命令行工具里输入命令查看虚拟环境路径
conda info
#把SadTalker源代码里面的:gfpgan\weights\GFPGANv1.4.pth剪切到虚拟环境的Lib\site-packages\gfpgan\weights 目录下,举个例子:我的虚拟环境就是截图红框路径,所以需要把gfpgan\weights\GFPGANv1.4.pth 剪切到虚拟环境的 D:\ProgramData\Anaconda3\envs\sadtalker\Lib\site-packages\gfpgan\weights 这个目录下 :
4.生成数字人视频
把语音文件放到SadTalker\examples\driven_audio 目录下
把图片放到SadTalker\examples\source_image 目录下
#基础使用
#python inference.py --driven_audio --source_image --enhancer gfpgan
#--driven_audio后面需要写音频文件路径,--source_image后面写图片的路径,下面是一个例子
python inference.py --driven_audio D:\SadTalker\examples\driven_audio\bus_chinese.wav --source_image D:\SadTalker\examples\source_image\full_body_2.png --enhancer gfpgan
等待执行完成后,就可以在SadTalker\results下面的文件夹里面找到生成的结果了
参数控制:--preprocess full 和 --still
python inference.py --driven_audio D:\SadTalker\examples\driven_audio\bus_chinese.wav --source_image D:\SadTalker\examples\source_image\full_body_2.png --enhancer gfpgan --preprocess full --still
--preprocess full 表示完整图片
- -still 可以减少头部运动,防止交接处扭曲,但是整个视频就几乎只有眼睛和口型的变化了,看起来没那么自然。
python inference.py --driven_audio F:\SadTalker\SadTalker\examples\driven_audio\bus_chinese.wav --source_image F:\SadTalker\SadTalker\examples\source_image\full_body_2.png --enhancer gfpgan
参考资料:
安装不了basicsr==1.4.2的解决方法_basicsr 1.4.2 depends on tb-nightly-CSDN博客
Python 如何更改现有 conda 虚拟环境的 Python 版本|极客教程 (geek-docs.com)

















 2978
2978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









