







Camera
先看一下最终的json格式:
[
{
"id": 0,
"img_name": "00001",
"width": 1959,
"height": 1090,
"position":
[-3.0089893469241797, -0.11086489695181866, -3.7527640949141428],
"rotation": [
[0.876134201218856, 0.06925962026449776, 0.47706599800804744],
[-0.04747421839895102, 0.9972110940209488, -0.057586739349882114],
[-0.4797239414934443, 0.027805376500959853, 0.8769787916452908]
],
"fy": 1164.6601287484507,
"fx": 1159.5880733038064
}
]
数据信息
image.bin: 图像相关
for each image:
image_id + qvec(shape:(4, )) + tvec(shape:(3, )) + camera_id
with open(path_to_model_file, "rb") as fid:
num_reg_images = read_next_bytes(fid, 8, "Q")[0]
for _ in range(num_reg_images):
binary_image_properties = read_next_bytes(
fid, num_bytes=64, format_char_sequence="idddddddi")
image_id = binary_image_properties[0]
qvec = np.array(binary_image_properties[1:5])
tvec = np.array(binary_image_properties[5:8])
camera_id = binary_image_properties[8]
image_name = ""
current_char = read_next_bytes(fid, 1, "c")[0]
while current_char != b"\x00": # look for the ASCII 0 entry
image_name += current_char.decode("utf-8")
current_char = read_next_bytes(fid, 1, "c")[0]
num_points2D 点云数量 eg.11661
x_y_id_s 读取点云坐标
xys整理转换->[x, y]
point3D_ids:3D点云 z轴坐标
num_points2D = read_next_bytes(fid, num_bytes=8,
format_char_sequence="Q")[0]
x_y_id_s = read_next_bytes(fid, num_bytes=24*num_points2D,
format_char_sequence="ddq"*num_points2D)
xys = np.column_stack([tuple(map(float, x_y_id_s[0::3])),
tuple(map(float, x_y_id_s[1::3]))])
point3D_ids = np.array(tuple(map(int, x_y_id_s[2::3])))
返回图像信息:
images[image_id] = Image(
id=image_id, qvec=qvec, tvec=tvec,
camera_id=camera_id, name=image_name,
xys=xys, point3D_ids=point3D_ids)
return images
cameras.bin: 相机内参
camera_id + model_id + model_name(相机模型)
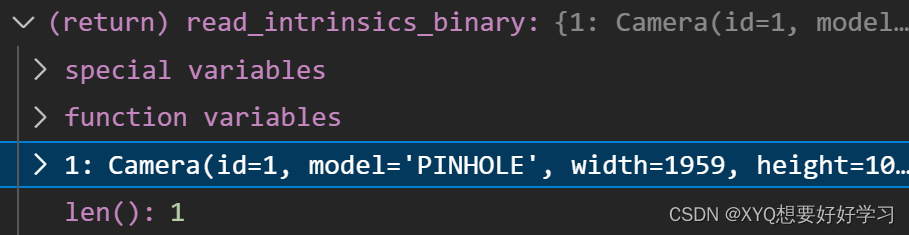
def read_intrinsics_binary(path_to_model_file):
"""
see: src/base/reconstruction.cc
void Reconstruction::WriteCamerasBinary(const std::string& path)
void Reconstruction::ReadCamerasBinary(const std::string& path)
"""
cameras = {}
with open(path_to_model_file, "rb") as fid:
num_cameras = read_next_bytes(fid, 8, "Q")[0]
for _ in range(num_cameras):
camera_properties = read_next_bytes(
fid, num_bytes=24, format_char_sequence="iiQQ")
camera_id = camera_properties[0]
model_id = camera_properties[1]
model_name = CAMERA_MODEL_IDS[camera_properties[1]].model_name
CAMERA_MODELS = {
CameraModel(model_id=0, model_name="SIMPLE_PINHOLE", num_params=3),
CameraModel(model_id=1, model_name="PINHOLE", num_params=4),
CameraModel(model_id=2, model_name="SIMPLE_RADIAL", num_params=4),
CameraModel(model_id=3, model_name="RADIAL", num_params=5),
CameraModel(model_id=4, model_name="OPENCV", num_params=8),
CameraModel(model_id=5, model_name="OPENCV_FISHEYE", num_params=8),
CameraModel(model_id=6, model_name="FULL_OPENCV", num_params=12),
CameraModel(model_id=7, model_name="FOV", num_params=5),
CameraModel(model_id=8, model_name="SIMPLE_RADIAL_FISHEYE", num_params=4),
CameraModel(model_id=9, model_name="RADIAL_FISHEYE", num_params=5),
CameraModel(model_id=10, model_name="THIN_PRISM_FISHEYE", num_params=12)
}
CAMERA_MODEL_IDS = dict([(camera_model.model_id, camera_model)
for camera_model in CAMERA_MODELS])
CAMERA_MODEL_NAMES = dict([(camera_model.model_name, camera_model)
for camera_model in CAMERA_MODELS])
width:1090, height:1959
num_params:4 相机参数量
params:(1159.5880733038061, 1164.6601287484507, 979.5, 545.0)
分别对应:focal_length_x focal_length_y
width = camera_properties[2]
height = camera_properties[3]
num_params = CAMERA_MODEL_IDS[model_id].num_params
params = read_next_bytes(fid, num_bytes=8*num_params,
format_char_sequence="d"*num_params)
返回相机:
cameras[camera_id] = Camera(id=camera_id,
model=model_name,
width=width,
height=height,
params=np.array(params))
assert len(cameras) == num_cameras
return cameras
转换处理
readColmapCameras:结合外参读取cam_Info
每帧对应一个cam_Info
一个相机内参 但有frame个cam_Info
可能是因为object是静态?只需要一个相机在不同时刻拍下即可。
class CameraInfo(NamedTuple):
uid: int
R: np.array
T: np.array
FovY: np.array
FovX: np.array
image: np.array
image_path: str
image_name: str
width: int
height: int
开始:
def readColmapCameras(cam_extrinsics, cam_intrinsics, images_folder):
cam_infos = []
for idx, key in enumerate(cam_extrinsics):
sys.stdout.write('\r')
# the exact output you're looking for:
sys.stdout.write("Reading camera {}/{}".format(idx+1, len(cam_extrinsics)))
sys.stdout.flush()
extr = cam_extrinsics[key]
intr = cam_intrinsics[extr.camera_id]
height = intr.height
width = intr.width
由q、t得到旋转和平移矩阵:
uid = intr.id
R = np.transpose(qvec2rotmat(extr.qvec))
T = np.array(extr.tvec)
def qvec2rotmat(qvec):
return np.array([
[1 - 2 * qvec[2]**2 - 2 * qvec[3]**2,
2 * qvec[1] * qvec[2] - 2 * qvec[0] * qvec[3],
2 * qvec[3] * qvec[1] + 2 * qvec[0] * qvec[2]],
[2 * qvec[1] * qvec[2] + 2 * qvec[0] * qvec[3],
1 - 2 * qvec[1]**2 - 2 * qvec[3]**2,
2 * qvec[2] * qvec[3] - 2 * qvec[0] * qvec[1]],
[2 * qvec[3] * qvec[1] - 2 * qvec[0] * qvec[2],
2 * qvec[2] * qvec[3] + 2 * qvec[0] * qvec[1],
1 - 2 * qvec[1]**2 - 2 * qvec[2]**2]])
根据相机的焦距和图像的宽/高计算视场角:
if intr.model=="SIMPLE_PINHOLE":
focal_length_x = intr.params[0]
FovY = focal2fov(focal_length_x, height)
FovX = focal2fov(focal_length_x, width)
elif intr.model=="PINHOLE":
focal_length_x = intr.params[0]
focal_length_y = intr.params[1]
FovY = focal2fov(focal_length_y, height)
FovX = focal2fov(focal_length_x, width)
else:
assert False, "Colmap camera model not handled: only undistorted datasets (PINHOLE or SIMPLE_PINHOLE cameras) supported!"
image_path = os.path.join(images_folder, os.path.basename(extr.name))
image_name = os.path.basename(image_path).split(".")[0]
# basename 提取文件名部分 split(".") "00001.jpg" 拆开 [0] 取"00001"
image = Image.open(image_path)
# 读取image type:PIL
cam_info = CameraInfo(uid=uid, R=R, T=T, FovY=FovY, FovX=FovX, image=image,
image_path=image_path, image_name=image_name, width=width, height=height)
cam_infos.append(cam_info)
sys.stdout.write('\n')
return cam_infos
getNerfppNorm
# 计算所有相机的中心点位置, 以及它到最远camera的距离
nerf_normalization = getNerfppNorm(train_cam_infos)
def getNerfppNorm(cam_info):
def get_center_and_diag(cam_centers):
cam_centers = np.hstack(cam_centers) # (3, 301)
avg_cam_center = np.mean(cam_centers, axis=1, keepdims=True)
center = avg_cam_center # (3, 1)
dist = np.linalg.norm(cam_centers - center, axis=0, keepdims=True)
diagonal = np.max(dist) # 最远距离
return center.flatten(), diagonal
cam_centers = []
for cam in cam_info:
W2C = getWorld2View2(cam.R, cam.T)
C2W = np.linalg.inv(W2C)
cam_centers.append(C2W[:3, 3:4])
center, diagonal = get_center_and_diag(cam_centers) # 所有相机的均值中心点,最远距离
radius = diagonal * 1.1
translate = -center
return {"translate": translate, "radius": radius}
W2C:world to camera view 世界坐标转局部坐标
-> 求逆:C2W 局部坐标转世界坐标
def getWorld2View2(R, t, translate=np.array([.0, .0, .0]), scale=1.0):
Rt = np.zeros((4, 4))
Rt[:3, :3] = R.transpose()
Rt[:3, 3] = t
Rt[3, 3] = 1.0
C2W = np.linalg.inv(Rt)
cam_center = C2W[:3, 3]
cam_center = (cam_center + translate) * scale
C2W[:3, 3] = cam_center
Rt = np.linalg.inv(C2W)
return np.float32(Rt)
readColmapSceneInfo
相机信息处理完毕:
def readColmapSceneInfo(path, images, eval, llffhold=8):
try:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.bin")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.bin")
cam_extrinsics = read_extrinsics_binary(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_binary(cameras_intrinsic_file)
except:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.txt")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.txt")
cam_extrinsics = read_extrinsics_text(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_text(cameras_intrinsic_file)
reading_dir = "images" if images == None else images
cam_infos_unsorted = readColmapCameras(cam_extrinsics=cam_extrinsics, cam_intrinsics=cam_intrinsics, images_folder=os.path.join(path, reading_dir))
cam_infos = sorted(cam_infos_unsorted.copy(), key = lambda x : x.image_name) # 按照图片顺序排序
if eval:
train_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold != 0]
test_cam_infos = [c for idx, c in enumerate(cam_infos) if idx % llffhold == 0]
else:
train_cam_infos = cam_infos
test_cam_infos = []
# 计算所有相机的中心点位置, 以及它到最远camera的距离
nerf_normalization = getNerfppNorm(train_cam_infos)
point cloud

vertices: type=PlyElement; size=182686
positions:点的xyz坐标向量
colors:点的颜色
normals:点的法向量
def fetchPly(path):
plydata = PlyData.read(path)
vertices = plydata['vertex']
positions = np.vstack([vertices['x'], vertices['y'], vertices['z']]).T
colors = np.vstack([vertices['red'], vertices['green'], vertices['blue']]).T / 255.0
normals = np.vstack([vertices['nx'], vertices['ny'], vertices['nz']]).T
return BasicPointCloud(points=positions, colors=colors, normals=normals)
ply_path = os.path.join(path, "sparse/0/points3D.ply")
bin_path = os.path.join(path, "sparse/0/points3D.bin")
txt_path = os.path.join(path, "sparse/0/points3D.txt")
if not os.path.exists(ply_path):
print("Converting point3d.bin to .ply, will happen only the first time you open the scene.")
try:
xyz, rgb, _ = read_points3D_binary(bin_path)
except:
xyz, rgb, _ = read_points3D_text(txt_path)
storePly(ply_path, xyz, rgb)
try:
pcd = fetchPly(ply_path)
except:
pcd = None
scene_info = SceneInfo(point_cloud=pcd,
train_cameras=train_cam_infos,
test_cameras=test_cam_infos,
nerf_normalization=nerf_normalization,
ply_path=ply_path)
return scene_info
至此,场景信息加载完毕
class SceneInfo(NamedTuple):
point_cloud: BasicPointCloud
train_cameras: list
test_cameras: list
nerf_normalization: dict
ply_path: str
Scene
上述已完成:
def __init__(self, args : ModelParams, gaussians : GaussianModel, load_iteration=None, shuffle=True, resolution_scales=[1.0]):
"""b
:param path: Path to colmap scene main folder.
"""
self.model_path = args.model_path
self.loaded_iter = None
self.gaussians = gaussians
if load_iteration:
if load_iteration == -1:
self.loaded_iter = searchForMaxIteration(os.path.join(self.model_path, "point_cloud"))
else:
self.loaded_iter = load_iteration
print("Loading trained model at iteration {}".format(self.loaded_iter))
self.train_cameras = {}
self.test_cameras = {}
if os.path.exists(os.path.join(args.source_path, "sparse")):
scene_info = sceneLoadTypeCallbacks["Colmap"](args.source_path, args.images, args.eval)
elif os.path.exists(os.path.join(args.source_path, "transforms_train.json")):
print("Found transforms_train.json file, assuming Blender data set!")
scene_info = sceneLoadTypeCallbacks["Blender"](args.source_path, args.white_background, args.eval)
else:
assert False, "Could not recognize scene type!"
把相机相关信息存入json文件:
if not self.loaded_iter:
# 复制ply
with open(scene_info.ply_path, 'rb') as src_file, open(os.path.join(self.model_path, "input.ply") , 'wb') as dest_file:
dest_file.write(src_file.read())
json_cams = []
camlist = []
if scene_info.test_cameras:
camlist.extend(scene_info.test_cameras)
if scene_info.train_cameras:
camlist.extend(scene_info.train_cameras) # 一次性追加另一个序列的多个值
# camlist len(301) 301张image对应的相机参数(fov image_path...)
for id, cam in enumerate(camlist):
# 解析每个camera_info对应到frame
json_cams.append(camera_to_JSON(id, cam))
# 写入json文件
with open(os.path.join(self.model_path, "cameras.json"), 'w') as file:
json.dump(json_cams, file)
def camera_to_JSON(id, camera : Camera):
# 旋转平移矩阵
Rt = np.zeros((4, 4))
Rt[:3, :3] = camera.R.transpose()
Rt[:3, 3] = camera.T
Rt[3, 3] = 1.0
# 变换到局部坐标系
W2C = np.linalg.inv(Rt)
pos = W2C[:3, 3]
rot = W2C[:3, :3]
serializable_array_2d = [x.tolist() for x in rot]
camera_entry = {
'id' : id,
'img_name' : camera.image_name,
'width' : camera.width,
'height' : camera.height,
'position': pos.tolist(),
'rotation': serializable_array_2d,
'fy' : fov2focal(camera.FovY, camera.height),
'fx' : fov2focal(camera.FovX, camera.width)
}
return camera_entry
视场角求得焦距:
def fov2focal(fov, pixels):
return pixels / (2 * math.tan(fov / 2))
接着,
# 随机打乱所有图片和对应cameInfo的顺序
if shuffle:
random.shuffle(scene_info.train_cameras) # Multi-res consistent random shuffling
random.shuffle(scene_info.test_cameras) # Multi-res consistent random shuffling
# 所有相机的中心点位置到最远camera的距离 7.49063801765442
self.cameras_extent = scene_info.nerf_normalization["radius"]
for resolution_scale in resolution_scales:
print("Loading Training Cameras")
self.train_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.train_cameras, resolution_scale, args)
print("Loading Test Cameras")
self.test_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.test_cameras, resolution_scale, args)
创建 3D gaussian
# 如果是初次训练, 则从COLMAP创建的点云中初始化每个点对应的3D gaussian, 否则直接从之前保存的模型文件中读取3D gaussian
if self.loaded_iter:
self.gaussians.load_ply(os.path.join(self.model_path,
"point_cloud",
"iteration_" + str(self.loaded_iter),
"point_cloud.ply"))
else:
self.gaussians.create_from_pcd(scene_info.point_cloud, self.cameras_extent)
把SceneInfo中,即刚刚读取到的点云数据,传入create_from_pcd函数:
def create_from_pcd(self, pcd : BasicPointCloud, spatial_lr_scale : float):
self.spatial_lr_scale = spatial_lr_scale
fused_point_cloud = torch.tensor(np.asarray(pcd.points)).float().cuda() # torch.Size([182686, 3])
# rgb转化为球谐系数
fused_color = RGB2SH(torch.tensor(np.asarray(pcd.colors)).float().cuda()) # torch.Size([182686, 3])
features = torch.zeros((fused_color.shape[0], 3, (self.max_sh_degree + 1) ** 2)).float().cuda() # torch.Size([182686, 3,16])
# 每个颜色通道有16个球谐系数
features[:, :3, 0 ] = fused_color
features[:, 3:, 1:] = 0.0
print("Number of points at initialisation : ", fused_point_cloud.shape[0])
# gaussian shape(scale)
# distCUDA2 计算点云中的每个点到与其最近的N个点的平均距离的平方
dist2 = torch.clamp_min(distCUDA2(torch.from_numpy(np.asarray(pcd.points)).float().cuda()), 0.0000001) # torch.Size([182686])
scales = torch.log(torch.sqrt(dist2))[...,None].repeat(1, 3) # 尺度缩放到log(平均距离)
# repeat 0维复制1次,1维复制3次 ->[182686, 3]
# gaussian rotation 初始化为0
rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda") # 旋转参数 四元组
rots[:, 0] = 1
# (P, 1), 每个点的不透明度, 初始化为0.1
opacities = inverse_sigmoid(0.1 * torch.ones((fused_point_cloud.shape[0], 1), dtype=torch.float, device="cuda"))
# 转为参数类型
self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(True)) # (P, 3)
self._features_dc = nn.Parameter(features[:,:,0:1].transpose(1, 2).contiguous().requires_grad_(True)) # (P, 1, 3)
self._features_rest = nn.Parameter(features[:,:,1:].transpose(1, 2).contiguous().requires_grad_(True)) # (P, 15, 3)
self._scaling = nn.Parameter(scales.requires_grad_(True)) # (P, 3)
self._rotation = nn.Parameter(rots.requires_grad_(True)) # (P, 4)
self._opacity = nn.Parameter(opacities.requires_grad_(True)) # (P, 1)
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda") # (P, ) 投影到2D时, 每个2D gaussian最大的半径
完毕。















 1252
1252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









