



今天学点啥?每天10分钟,拆解一个真实岗位JD,搞懂一个大模型技术点。

今天拆解的是阿里巴巴智能信息事业部的LLM算法岗,薪资给到了40-70K·16薪(年薪最高112万),JD中的技术要求如下:
- ✅ 前沿探索:跟踪、研究大语言模型相关领域,包括但不限于模型预训练、指令微调、强化学习、检索增强生成(RAG)、AI Agent等
- ✅ 业务赋能:基于大规模用户行为数据和高质量标注数据,设计并构建LLM解决方案,以支持搜索广告和信息流广告相关业务
- ✅ 专业技能:熟悉prompt工程及常用的SFT数据构建方式,了解RAG、AI Agent框架
在阿里这个70K的算法岗中,RAG被多 次明确提及,足见其重要性。
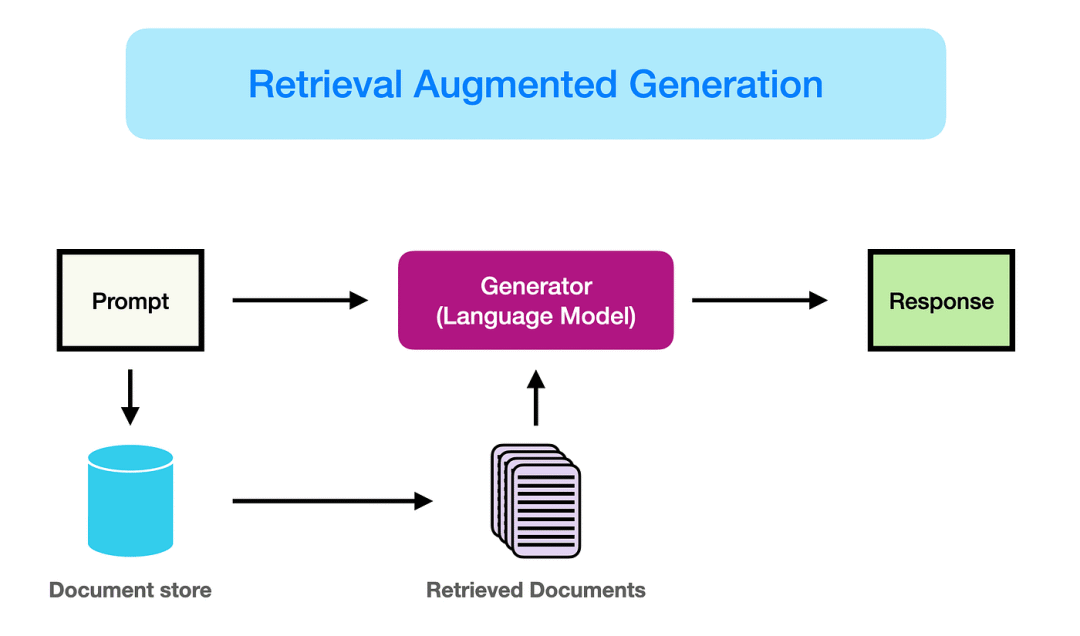
一、RAG是什么?
想深入了解RAG是什么?我们先看一个真实场景:
你在淘宝问客服:“我上个月买的羽绒服,尺码偏大想换小一号,怎么办?”
- 传统LLM: “您好,关于商品换货,一般需要在收货后7天内申请…”(标准话术,没解决问题)
- 用了RAG的智能客服: “您好,查询到您10月5日购买的XX品牌羽绒服(订单号123456),该商品支持7天无理由退换。由于您购买的黑色L码库存充足,可以直接为您换成M码,预计3天内送达。是否需要我帮您提交换货申请?”
区别在哪? 传统LLM只能基于训练数据泛泛回答,RAG系统先检索了你的订单信息、商品库存、售后政策,再生成个性化回复。
看完上面真实场景,再来简单科普下:RAG是什么?
RAG = Retrieval-Augmented Generation(检索增强生成)
- 传统LLM:答案 = LLM(问题)
- RAG系统:答案 = LLM(问题 + 检索到的文档)
有了RAG系统后,大模型的一次问题实际上分为三步执行:
(1)用户提问时,先从知识库里检索相关文档
(2)把检索到的文档和问题一起喂给LLM
(3)LLM基于这些文档生成回答
上面真实场景具体三步执行如下:
code-snippet__js
用户提问:"我上个月买的羽绒服,尺码偏大想换小一号,怎么办?"
↓
【Query理解】
├─ 时间范围:"上个月" → 2024年10月1日-10月31日
├─ 商品信息:"羽绒服"
├─ 问题描述:"尺码偏大"
└─ 用户需求:"换小一号" = 换货需求
↓
【多路检索阶段】
├─ 向量检索(语义理解):
│ "尺码偏大想换小一号" = "换货" = "退换" = "尺码不合适"
│ 召回:售后政策文档、换货流程、尺码指南
│
├─ BM25检索(关键词匹配):
│ 匹配:"羽绒服"、"换"、"尺码"
│ 召回:商品相关文档
│
└─ 结构化查询(用户数据库):
WHERE user_id=当前用户 AND
purchase_date BETWEEN '2024-10-01' AND '2024-10-31' AND
product_name LIKE '%羽绒服%'
结果:订单号123456,10月5日购买黑色L码羽绒服
↓
【混合召回结果】(10个候选文档)
├─ 订单记录:用户10月5日购买XX品牌黑色L码羽绒服
├─ 商品信息:该羽绒服有S/M/L/XL四个尺码
├─ 库存信息:黑色M码当前库存30件
├─ 售后政策:支持7天无理由退换,需吊牌完好
├─ 换货流程:在线提交申请,3个工作日审核
├─ 物流信息:同城3天达,异地5-7天
├─ 尺码对照表:L码胸围110cm,M码胸围106cm
├─ 用户评价:该商品尺码偏大,建议拍小一号
├─ 退换条件:商品未洗涤、未穿着、吊牌完整
└─ 客服话术:主动询问用户需求,提供解决方案
↓
【Rerank重排序】
根据Query相关性打分,精选Top3:
[文档1] 订单记录 - 相关度0.95(直接命中用户订单)
[文档2] 售后政策 - 相关度0.92(回答"怎么办")
[文档3] 库存信息 - 相关度0.89(确认M码有货)
↓
【构造Prompt】
系统角色:你是阿里巴巴淘宝智能客服助手,需要基于检索到的信息提供个性化服务
参考信息:
[文档1] 用户于2024年10月5日购买XX品牌羽绒服,黑色L码,订单号123456,
订单状态:已收货(10月8日签收)
[文档2] 该商品支持7天无理由退换货政策(从签收日起算),需要商品吊牌完好、
未穿着、未洗涤。换货流程:在线提交申请→客服审核→寄回商品→发出新商品
[文档3] 该商品当前库存状态:黑色M码库存充足(30件),预计3天内可发货;
黑色S码库存2件
用户问题:我上个月买的羽绒服,尺码偏大想换小一号,怎么办?
输出要求:
1. 基于参考信息回答,不要编造
2. 主动提供具体解决方案(不是泛泛的政策介绍)
3. 确认用户需求,询问是否帮助办理
4. 语气友好、专业
↓
【LLM生成回答】
"您好,查询到您10月5日购买的XX品牌羽绒服(订单号123456),该商品支持7天无理由
退换。由于您购买的黑色L码库存充足,可以直接为您换成M码,预计3天内送达。
是否需要我帮您提交换货申请?"
↓
【答案优势分析】
✓ 个性化:准确找到用户的订单(10月5日)
✓ 准确性:确认了政策(7天无理由)和库存(M码有货)
✓ 可操作:给出具体方案(换M码)和时效(3天)
✓ 主动服务:询问是否帮助办理,而非让用户自己去找
二、RAG关键技术有哪些?
通过上面真实场景,科普完RAG是什么?如果大家没有编程经验,对RAG三步执行估计比较懵。接下来通过RAG关键技术深度解析来让大家更深入理解。
1. Embedding和向量检索:RAG的核心
什么是Embedding?把文本转成一串数字(向量),让计算机能"理解"语义。
code-snippet__js
"羽绒服" → [0.2, 0.8, 0.1, ..., 0.5](768个数字)
"冬装外套" → [0.3, 0.7, 0.2, ..., 0.4]
"苹果手机" → [0.9, 0.1, 0.8, ..., 0.2]
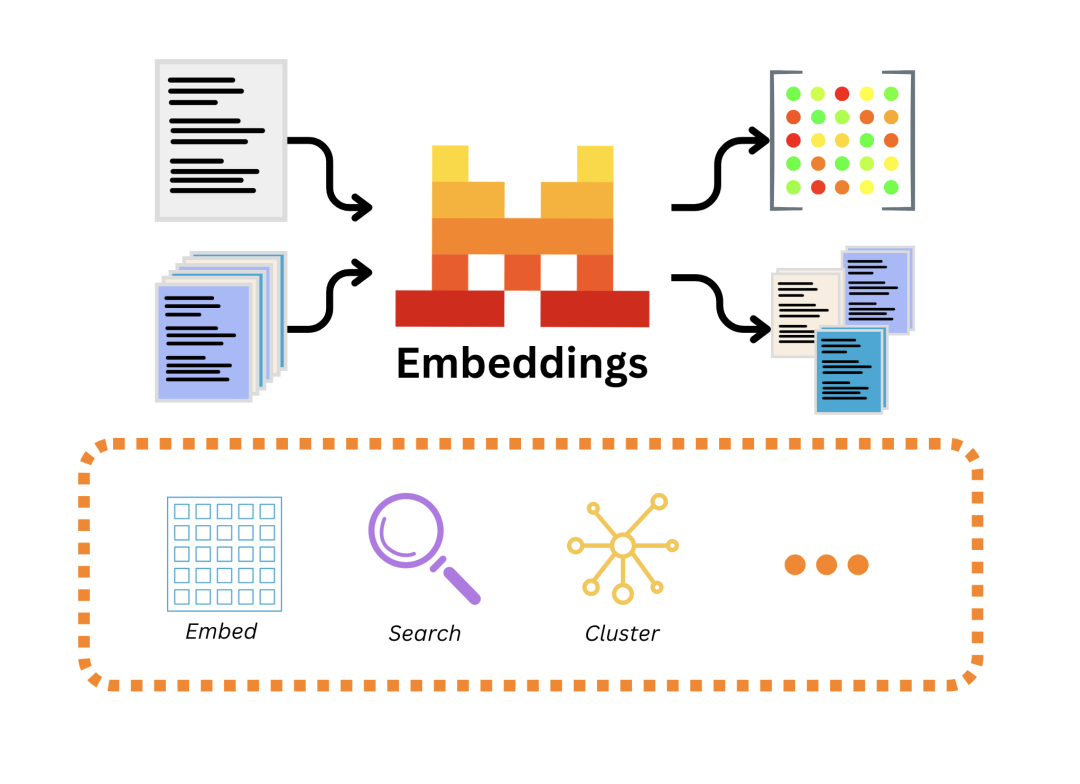
如何进行向量检索?简单说就是给两个向量的"相似程度"打分,例如用余弦相似度计算两个向量的相似度。
- “羽绒服” vs “冬装外套” = 0.85(很相似)
- “羽绒服” vs “苹果手机” = 0.12(不相关)
为什么需要向量检索?语义相近的内容,其向量在空间中的位置也更接近,这样向量检索能快速找到“相似”内容,而不是机械地匹配“相同”的关键词。
- 传统关键词:用户搜"防寒衣物",找不到"羽绒服"(词不同)
- 向量检索:能理解"防寒衣物"和"羽绒服"语义相近,成功匹配
2. 文档切分:看似简单,实则决定成败
为什么要文档切分(Chunk)?为了在精度与上下文之间取得平衡,既能精准定位相关信息,又能为模型提供语义完整的上下文。
(1)LLM上下文限制:GPT-4约8K tokens(约6000字),不能把整本手册都塞进去
(2)精准定位:一份50页的售后政策,只有第3页回答了用户问题,其他是干扰
(3)检索效率:小块匹配更精准
如何进行Chunk大小的权衡?核心是在检索精度与上下文完整性之间找到最佳平衡点。
Chunk大小
优点
缺点
适合场景
小(100-300字)
检索精准
上下文不完整,容易断句
FAQ、问答对
中(500-1000字)
平衡
通用
技术文档、产品手册
大(1500+字)
上下文完整
噪声多、检索不精准
长文章、分析报告
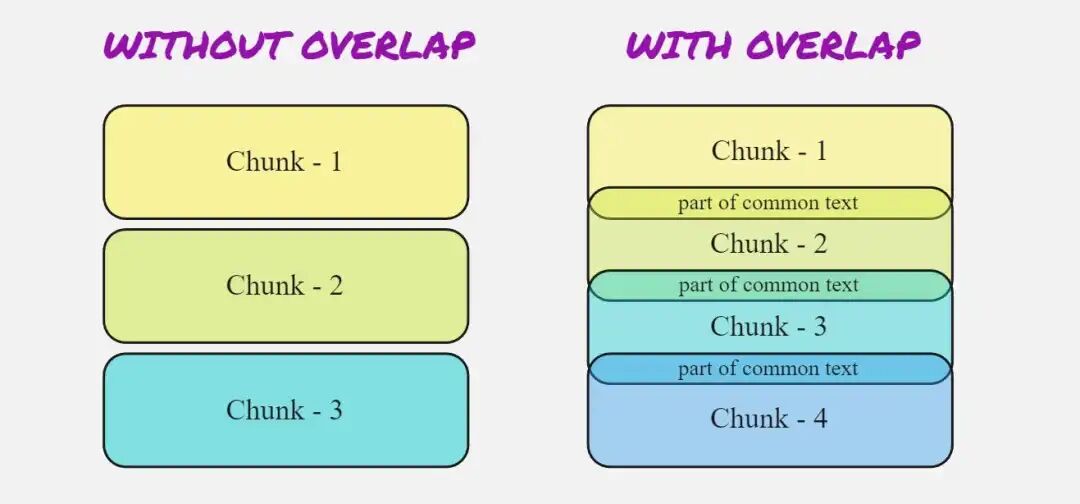
什么是Overlap?Overlap为什么很重要?Overlap是指在对文档进行分块(Chunk)时,相邻文本块之间的重叠部分。适当Overlap可以防止语义切断,从而提高检索召回率。
例如售后政策文本:“商品自签收之日起7天内支持退换货”
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 中文约250字,相当于1-2个段落
chunk_overlap=50, # 10%重叠,确保关键句不被切断
separators=["\n\n", "\n", "。", "!", "?", " ", ""] # 优先按段落、句子切分
)
(1)不加Overlap,切断了关键句。
- Chunk1:“商品自签收之日起7天”(不完整)
- Chunk2:“内支持退换货”(不完整)
- 结果:两个chunk都没用!
(2)加50字Overlap,关键信息完整。
- Chunk1:“…商品自签收之日起7天内支持退换货…”(完整)
- Chunk2:“…7天内支持退换货,需保持吊牌完好…”(完整)
- 结果:关键信息被两个Chunk都包含了
常见的Overlap配置:一般建议Overlap为Chunk size的10%-20%
Chunk Size
Overlap
Overlap比例
适用场景
500 tokens
50 tokens
10%
短文档、结构清晰
1000 tokens
200 tokens
20%
通用场景(推荐)
2000 tokens
400 tokens
20%
长文档、复杂内容
3. 混合检索:1+1>2的组合拳
什么是混合检索(Hybrid Search)?为什么需要混合检索?混合检索(Hybrid Search) 是指结合多种检索方法来提高RAG系统的检索质量,最常见的是结合向量检索(语义检索)和关键词检索(如BM25)。
例如上面真实场景:用户问"订单号123456的物流信息"
- 纯向量检索(Dense Retrieval):匹配到"订单查询"相关文档,但不是这个订单
- 纯关键词检索(Sparse Retrieval,如BM25):精确匹配"123456",但不理解"物流"=“快递”=“配送”
- 混合检索: 既语义理解,又关键词匹配,找到订单123456的物流文档
什么时候必须用混合检索?下面这些场景必须用混合检索:
- 文档包含大量专有名词(产品名、人名、技术术语)
- 用户查询包含精确信息(版本号、日期、ID等)
- 需要高召回率的场景(客服、法律文档)
向量检索(语义检索)和关键词检索(如BM25)的权重怎么选?权重不是随便定的,需要**根据业务场景调优。**
场景
向量权重
关键词权重
通用知识问答
0.7
0.3
技术文档检索
0.5
0.5
产品手册查询
0.4
0.6
代码搜索
0.3
0.7
例如阿里的商品搜索:可能是0.5/0.5,因为既要理解"防寒衣物"(语义),又要匹配"羽绒服"(关键词)
from langchain.retrievers import EnsembleRetriever
# 向量检索器
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
# BM25关键词检索器
bm25_retriever = BM25Retriever.from_documents(chunks)
# 混合检索:70%语义 + 30%关键词
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.7, 0.3] # 根据业务A/B测试调优
)
4. 知识图谱检索:理解实体间的关系网络
什么是知识图谱检索(Knowledge Graph Retrieval)?为什么需要它?知识图谱检索是指通过构建实体及其关系的图结构,让RAG系统不仅能检索到相关文本,还能理解实体之间的关联关系,从而提供更准确、更完整的答案。
传统向量检索只能找到"相似"的文本片段,但无法理解实体间的复杂关系。而知识图谱由三个核心元素构成:实体(Entity) - 关系(Relation) - **属性(Attribute),****通过结构化的知识图谱表示,捕捉数据中实体、关系及全局语义,从而增强LLM的推理能力,解决传统RAG在复杂查询和多跳推理中的局限性。
- 复杂查询:利用社区聚类(如Leiden算法)生成分层摘要,支持跨文档主题分析(如“近五年AI研究趋势”),实现全局语义理解,解决复杂查询。
- 多跳推理:通过图谱路径回答需多次关联的问题(如“A事件如何间接导致C结果”)。
什么时候必须用知识图谱检索?
下面这些场景中,知识图谱检索能显著提升RAG效果。
| 场景 | 为什么需要知识图谱 | 示例 |
|---|---|---|
| 多跳推理 | 需要通过多个关系推导答案 | "我朋友的朋友是谁?"需要跨越2层关系 |
| 产品对比 | 需要同时提取多个产品的相同属性 | “对比三款手机的电池续航” |
| 故障诊断 | 需要通过症状→原因→解决方案的因果链 | “电脑蓝屏→内存故障→更换内存条” |
| 合规检查 | 需要追溯政策依据链 | "该操作是否合规?"需要检查多层政策关系 |
| 个性化推荐 | 需要理解用户历史行为和产品关联 | “购买了A的用户还喜欢B和C” |
- Rerank重排序:最后一道质量关卡
什么是Rerank重排序?为什么需要重排序?Rerank(重排序) 是在初步检索后,使用更精细的模型对候选文档重新打分和排序,确保最相关的内容排在最前面,提供给LLM生成答案。
(1)初步检索返回了10个文档,但相关性参差不齐
- 向量检索:返回了语义相似但不精确的文档
- 关键词检索:匹配到了关键词但上下文不对
- 知识图谱:找到了相关实体但不是用户真正想要的
(2)所以进行两阶段检索,Rerank按相关性重新排序
- 粗排:向量检索从100万 → Top100
- 精排:Rerank从Top100 → Top3
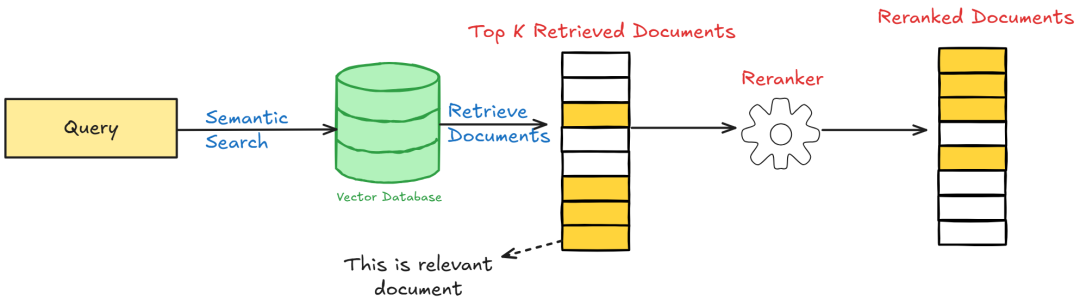
Rerank的核心原理是什么?Rerank模型与初步检索模型的区别如下
对比维度
初步检索(First-stage)
Rerank(Second-stage)
模型类型
双塔模型(Bi-Encoder)
交叉编码器(Cross-Encoder)
计算方式
查询和文档分别编码,计算相似度
查询和文档联合编码,深度交互
速度
快(毫秒级),可预计算文档向量
慢(百毫秒级),必须实时计算
准确性
中等,适合海量召回
高,适合精排Top-K
候选规模
百万级→Top100
Top100→Top5
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank
# Rerank模型
compressor = CohereRerank(
model="rerank-multilingual-v2.0",
top_n=3# 最终返回3个最相关文档
)
# 组合:先向量检索Top10,再Rerank精选Top3
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vector_retriever
)
为什么大厂LLM算法工程师需要深入理解RAG?因为他们需要的不是会调API的人,而是能优化全链路、解决生产问题的工程师。RAG不是简单的"检索+生成",而是一套完整的系统工程。
-
Embedding:理解语义的基础,768维是平衡点
-
Chunk:500字+50字overlap,保证语义完整
-
混合检索:语义+关键词,权重根据业务调优
-
知识图谱检索:理解实体间的关系网络
-
Rerank:两阶段检索,精度的最后一道质量关卡
日拱一卒,让大脑不断构建深度学习和大模型的神经网络连接。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









