







1. 引言
承接我们之前对模型量化技术的探讨,本文将聚焦于近年来在大型语言模型 (LLMs) 低比特训练后量化 (PTQ) 方面取得的进展,并深入研究 DeepSeek 在 FP8 量化上的探索。 随着大型语言模型 (LLMs) 在自然语言处理领域取得巨大成功,其庞大的参数规模带来了显著的计算和存储挑战,使得高效部署成为关键问题。低比特量化,尤其是将模型参数量化到 4 比特甚至更低的精度,是实现极致压缩和加速推理的有效手段。然而,传统的 PTQ 方法在应用于 LLMs 并进行低比特量化时,往往会导致不可接受的精度损失。近年来,研究人员提出了多种先进的 PTQ 技术,旨在克服这些挑战。本文将深入探讨这些技术进展,并重点介绍 DeepSeek 在探索 FP8 量化以优化 LLMs 方面的工作。
2. LLM 低比特训练后量化技术进展
2.1 GPTQ: 精确的生成式预训练 Transformer 训练后量化
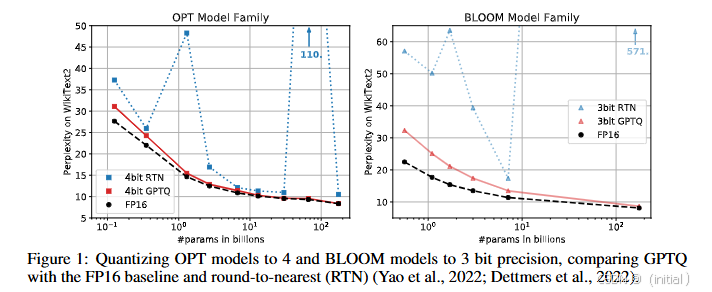
2.1.1核心思想与深入解析:
GPTQ 建立在 Optimal Brain Surgeon (OBS) 框架之上,旨在通过最小化量化引起的模型输出变化来直接量化预训练的 Transformer 模型。OBS 的基本思想是通过使用泰勒展开估计移除网络连接对损失函数的影响,并利用二阶导数(Hessian 矩阵)来指导剪枝。GPTQ 将 OBS 的思想应用于量化。对于每一层,GPTQ 迭代地量化每个权重,并在量化后通过更新同一层中尚未量化的权重来补偿由此引入的误差。具体而言,对于一个权重
w
i
j
w_{ij}
wij,GPTQ 会估计其量化到低精度
w
^
i
j
\hat{w}_{ij}
w^ij 后对损失函数
L
L
L 的影响,这可以通过二阶泰勒展开近似表示:
Δ
L
≈
g
i
j
Δ
w
i
j
+
1
2
H
i
j
,
i
j
(
Δ
w
i
j
)
2
+
∑
(
k
,
l
)
≠
(
i
,
j
)
H
i
j
,
k
l
Δ
w
k
l
\Delta L \approx g_{ij} \Delta w_{ij} + \frac{1}{2} H_{ij, ij} (\Delta w_{ij})^2 + \sum_{(k,l) \neq (i,j)} H_{ij, kl} \Delta w_{kl}
ΔL≈gijΔwij+21Hij,ij(Δwij)2+(k,l)=(i,j)∑Hij,klΔwkl
其中
g
i
j
g_{ij}
gij 是梯度,
H
H
H 是 Hessian 矩阵,
Δ
w
i
j
=
w
^
i
j
−
w
i
j
\Delta w_{ij} = \hat{w}_{ij} - w_{ij}
Δwij=w^ij−wij 是量化误差。GPTQ 的目标是在量化每个权重后,通过调整剩余的权重
Δ
w
k
l
\Delta w_{kl}
Δwkl 来最小化这个损失变化。实际应用中,GPTQ 通常使用 Hessian 矩阵的对角近似,并采用一种贪婪的逐权重量化策略。
- 关键特点: GPTQ 能够实现极低的比特量化(如 INT4),并且在包括 GPT-2、GPT-3 等多种 LLM 架构上表现出优异的精度。其量化过程相对快速,因为它只需要少量校准数据来估计 Hessian 信息。
- 优缺点与解析: 优点是能够实现非常低的比特率,量化速度快,并且精度较高,这得益于其基于 Hessian 的误差估计和补偿机制。OBS 框架提供了一种理论基础来指导权重的量化。缺点是依赖二阶导数信息的近似,可能对模型结构较为敏感,且 Hessian 计算本身也存在一定的开销。逐层量化的方式可能无法捕捉到跨层的依赖关系,限制了全局优化。
- 相关论文:
2.1.2 GPTQ 量化算法核心流程
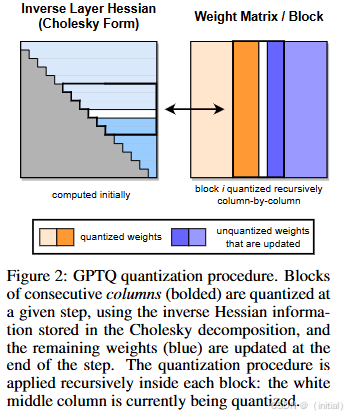
核心步骤:使用存储在Cholesky(切尔斯基)分解中的逆Hessian(海森)
信息量化连续列的块(加粗表示),并在步骤结束时更新剩余的权重
(蓝色表示),在每个块内递归(白色中间块)地应用量化过程。
GPTQ量化过程的关键步骤操作,具体描述如下:
- 块量化:选择一块连续的列(在图中加粗表示),并将其作为当前步骤 的量化目标。
- 使用Cholesky分解:利用Cholesky分解得到的逆Hessian信息来量化选定 的块。Cholesky分解提供了一种数值稳定的方法来处理逆矩阵,这对于维 持量化过程的准确性至关重要。
- 权重更新:在每个量化步骤的最后,更新剩余的权重(在图中以蓝色表 示)。这个步骤确保了整个量化过程的连贯性和精确性。
- 递归量化:在每个选定的块内部,量化过程是递归应用的。这意味着量 化过程首先聚焦于一个较小的子块,然后逐步扩展到整个块。 通过这种方式,GPTQ方法能够在保持高度精度的同时,高效地处理大量 的权重,这对于大型模型的量化至关重要。这种策略特别适用于处理大
型、复杂的模型,如GPT系列,其中权重数量巨大,且量化过程需要特别 小心以避免精度损失。
当然,可以将算法中的步骤转换成数学公式的形式。以下是算法步骤的数学表达
2.1.3 量化权重 W
输入:权重矩阵 W ∈ R d row × d col W \in \mathbb{R}^{d_{\text{row}} \times d_{\text{col}}} W∈Rdrow×dcol,逆Hessian矩阵 H − 1 = ( 2 X X ⊤ + λ I ) − 1 \mathbf{H}^{-1} = (2XX^{\top} + \lambda I)^{-1} H−1=(2XX⊤+λI)−1 ,块大小 B B B
输出:量化后的权重矩阵 Q ∈ R d row × d col Q \in \mathbb{R}^{d_{\text{row}} \times d_{\text{col}}} Q∈Rdrow×dcol ,量化误差矩阵 E ∈ R d row × B E \in \mathbb{R}^{d_{\text{row}} \times B} E∈Rdrow×B
步骤:
-
初始化:
Q ← 0 d row × d col Q \leftarrow \mathbf{0}_{d_{\text{row}} \times d_{\text{col}}} Q←0drow×dcol
E ← 0 d row × B E \leftarrow \mathbf{0}_{d_{\text{row}} \times B} E←0drow×B
H − 1 ← Cholesky ( ( H − 1 ) ⊤ ) \mathbf{H}^{-1} \leftarrow \text{Cholesky}((\mathbf{H}^{-1})^{\top}) H−1←Cholesky((H−1)⊤) -
对于 i = 0 , B , 2 B , … , i = 0, B, 2B, \ldots, i=0,B,2B,…, do:
直到 i ≥ d col \text{直到 } i \geq d_{\text{col}} 直到 i≥dcol- 对于
j
=
i
,
…
,
i
+
B
−
1
j = i, \ldots, i + B - 1
j=i,…,i+B−1 do(如果
j
<
d
col
j < d_{\text{col}}
j<dcol ):
Q : , j ← quant ( W : , j ) Q_{:,j} \leftarrow \text{quant}(W_{:,j}) Q:,j←quant(W:,j)
E : , j − i ← ( W : , j − Q : , j ) [ H − 1 ] j j E_{:,j-i} \leftarrow \frac{(W_{:,j} - Q_{:,j})}{[\mathbf{H}^{-1}]_{jj}} E:,j−i←[H−1]jj(W:,j−Q:,j)
W : , j : ( i + B ) ← W : , j : ( i + B ) − E : , j − i ⋅ H j , j : ( i + B ) − 1 W_{:,j:(i+B)} \leftarrow W_{:,j:(i+B)} - E_{:,j-i} \cdot \mathbf{H}^{-1}_{j,j:(i+B)} W:,j:(i+B)←W:,j:(i+B)−E:,j−i⋅Hj,j:(i+B)−1
- 对于
j
=
i
,
…
,
i
+
B
−
1
j = i, \ldots, i + B - 1
j=i,…,i+B−1 do(如果
j
<
d
col
j < d_{\text{col}}
j<dcol ):
-
更新剩余权重:
W : , ( i + B ) : ← W : , ( i + B ) : − E ⋅ H i : ( i + B ) , ( i + B ) : − 1 W_{:,(i+B):} \leftarrow W_{:,(i+B):} - E \cdot \mathbf{H}^{-1}_{i:(i+B),(i+B):} W:,(i+B):←W:,(i+B):−E⋅Hi:(i+B),(i+B):−1 -
返回 Q Q Q 和 E E E。
其中,函数 quant ( ⋅ ) \text{quant}(\cdot) quant(⋅) 表示量化操作, H j , j : ( i + B ) − 1 \mathbf{H}^{-1}_{j,j:(i+B)} Hj,j:(i+B)−1表示逆Hessian矩阵 H − 1 \mathbf{H}^{-1} H−1 中从第 j j j 行到第 i + B i+B i+B 行,第 j j j 列的子矩阵,其他子矩阵索引同理。
2.2 AWQ: 激活感知的低比特宽度模型压缩

2.2.1核心思想与深入解析:
AWQ (Activation-aware Weight Quantization) 的核心洞察在于 LLM 中不同权重的量化敏感度受到其对应的激活值的尺度密切相关。AWQ 认为,具有较大激活值的权重通道对量化误差更为敏感。因此,AWQ 的关键步骤是识别这些重要的权重,并通过调整它们的数值范围对其进行特殊处理以最小化量化误差。
具体来说,AWQ 通过在少量校准数据上运行模型,收集每个权重通道的激活值统计信息(通常是最大绝对值)。对于一个线性层
W
∈
R
m
×
n
W \in \mathbb{R}^{m \times n}
W∈Rm×n,AWQ 会为每个输出通道
i
∈
{
1
,
.
.
.
,
m
}
i \in \{1, ..., m\}
i∈{1,...,m} 计算激活值
A
∈
R
b
×
n
A \in \mathbb{R}^{b \times n}
A∈Rb×n 的尺度
S
i
=
max
j
,
b
∣
A
b
,
j
∣
S_i = \max_{j, b} |A_{b, j}|
Si=maxj,b∣Ab,j∣。然后,AWQ 会对权重
W
i
,
:
W_{i, :}
Wi,: 进行缩放:
W
i
,
:
′
=
W
i
,
:
⋅
S
i
α
W'_{i, :} = W_{i, :} \cdot S_i^\alpha
Wi,:′=Wi,:⋅Siα
其中
α
\alpha
α 是一个在
[
0
,
1
)
[0, 1)
[0,1) 范围内的超参数,用于控制缩放的程度。在推理时,为了保持计算结果的一致性,需要对后续的激活值进行反向缩放。AWQ 的核心思想是通过这种激活感知的缩放,使得量化后的权重能够更好地逼近原始权重,从而减少精度损失。
- 优缺点与解析: 优点是能够实现更高的精度,尤其在极低比特下,这得益于其直接关注量化敏感性的权重。激活尺度提供了一种简单而有效的方式来估计权重的“重要性”。缺点是需要少量具有代表性的校准数据来准确估计激活值尺度,并且超参数 α \alpha α 的选择可能需要根据不同的模型和层进行调整。
- 相关论文:
- [2] AWQ: Activation-aware Weight Quantization for Low-bit Wide Model Compression. Advances in Neural Information Processing Systems, 2023.
2.2.2 关键特点

- 低位权重量化:AWQ专为大型语言模型(LLMs)设计,支持低位(即少位数)的权重量化,有效减少模型大小。
- 重点保护显著权重:AWQ基于权重重要性不均的观察,只需保护大约1%的显著权重,即可显著减少量化误差。
- 观察激活而非权重:在确定哪些权重是显著的过程中,AWQ通过观察激活分布而非权重分布来进行。
- 无需反向传播或重构:AWQ不依赖于复杂的反向传播或重构过程,因此能够更好地保持模型的泛化能力,避免对
特定数据集的过拟合。 - 适用于多种模型和任务:AWQ在多种语言建模任务和领域特定基准测试中表现出色,包括指令调整的语言模型和
多模态语言模型。 - 高效的推理框架:与AWQ配套的是一个为LLMs量身定做的高效推理框架,提供显著的速度提升,适用于桌面和
移动GPU。 - 支持边缘设备部署:这种方法支持在内存和计算能力有限的边缘设备(如NVIDIA Jetson Orin 64GB)上部署大
型模型,如70B Llama-2模型。
2.2.3 AWQ 量化算法核心流程
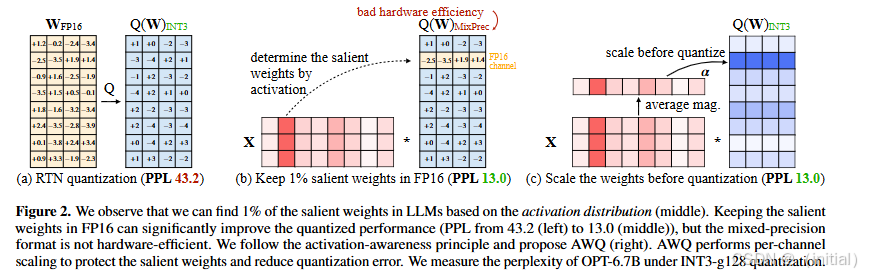
-
量化函数 Q ( w ) Q(w) Q(w):
Q ( w ) = Δ ⋅ Round ( w Δ ) , Δ = max ( ∣ w ∣ ) ⋅ 2 N − 1 Q(w) = \Delta \cdot \text{Round}\left(\frac{w}{\Delta}\right), \quad \Delta = \max(|w|) \cdot 2^{N-1} Q(w)=Δ⋅Round(Δw),Δ=max(∣w∣)⋅2N−1
其中, N N N 是量化位数, Δ \Delta Δ 是由绝对最大值确定的量化尺度。 -
量化误差:
- 量化误差主要由四舍五入操作引起,其期望误差 RoundErr ( ⋅ ) \text{RoundErr}(\cdot) RoundErr(⋅) 大约为 0.25。
-
缩放和反量化:
- 通过缩放权重
w
w
w 并相应地调整输入
x
x
x,可以减少量化误差:
Q ( w ⋅ s ) ⋅ x s = Δ ′ ⋅ Round ( w s Δ ′ ) ⋅ x s Q(w \cdot s) \cdot \frac{x}{s} = \Delta' \cdot \text{Round}\left(\frac{ws}{\Delta'}\right) \cdot \frac{x}{s} Q(w⋅s)⋅sx=Δ′⋅Round(Δ′ws)⋅sx
其中, Δ ′ \Delta' Δ′ 是应用缩放 s s s 后的新的量化尺度。
- 通过缩放权重
w
w
w 并相应地调整输入
x
x
x,可以减少量化误差:
算法步骤
-
识别显著权重:
- 通过分析激活分布来识别显著权重通道,而不是直接分析权重分布。
-
自动搜索最优缩放因子:
- 对于每个输入通道,自动搜索一个最优的缩放因子
s
s
s,以最小化量化后的输出差异:
s ∗ = arg min s L ( s ) , L ( s ) = ∥ Q ( W ⋅ diag ( s ) ) ( diag ( s ) − 1 ⋅ X ) − W X ∥ s^* = \arg\min_s L(s), \quad L(s) = \|Q(W \cdot \text{diag}(s))(\text{diag}(s)^{-1} \cdot X) - WX\| s∗=argsminL(s),L(s)=∥Q(W⋅diag(s))(diag(s)−1⋅X)−WX∥
其中, W W W 是原始权重, X X X 是输入特征。
- 对于每个输入通道,自动搜索一个最优的缩放因子
s
s
s,以最小化量化后的输出差异:
-
量化和反量化:
- 使用找到的最优缩放因子对权重进行量化和反量化,以减少量化误差。
-
模型微调:
- 在量化后,对模型进行微调以恢复可能的精度损失。
2.3 SpQR: 近乎无损的 LLM 压缩稀疏量化表示
- 核心思想与深入解析: SpQR (Sparse-Quantized Representation) 的目标是实现 LLM 的高压缩率,同时尽可能地保持原始模型的精度。SpQR 的方法是将每个权重 w w w 表示为两个部分:一个低比特的量化值 q q q 和一个稀疏的、更高精度的残差 r r r。具体来说,对于一个权重张量 W W W,SpQR 首先确定一个稀疏模式,通常是基于权重的绝对值大小,将小于某个阈值的权重置零。然后,对于剩余的非零权重,SpQR 使用低比特进行量化。为了补偿量化和稀疏化引入的误差,SpQR 会计算一个残差 r = w − q r = w - q r=w−q,并以更高的精度存储这些残差。为了进一步提高效率,SpQR 对这些残差也进行了稀疏化处理,只保留其中一部分(例如,每 k k k 个权重保留一个残差)。因此,一个原始的权重 w w w 近似表示为 q + s ⋅ r q + s \cdot r q+s⋅r,其中 q q q 是量化值, r r r 是残差, s s s 是一个稀疏掩码。
- 关键特点: SpQR 可以在大幅减小模型尺寸的同时,将对模型性能的影响降到最低,甚至在某些情况下可以实现近乎无损的压缩。
- 优缺点与解析: 优点是可以实现非常高的压缩率且精度损失极小,这得益于稀疏性和残差校正的结合。稀疏性降低了存储需求,而残差校正弥补了低比特量化带来的信息损失。缺点是实现和推理可能需要特定的硬件或优化的软件库来高效地处理稀疏矩阵和残差计算,这可能会增加推理的复杂性。
- 相关论文:
- [3] SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Compression. arXiv preprint arXiv:2303.15698, 2023.
2.4 SmoothQuant: 平滑激活值以实现低比特量化
- 核心思想与深入解析: SmoothQuant 的核心思想是解决 LLM 中激活值和权重的量化难度不平衡的问题。激活值的动态范围通常比权重要大得多,这使得在进行低比特量化时,激活值更容易饱和,导致信息损失。SmoothQuant 通过在每个 Transformer block 内引入一个可调的平滑因子
α
\alpha
α,对激活值和权重进行重新缩放。对于一个激活张量
A
A
A 和其后的权重张量
W
W
W,SmoothQuant 执行以下变换:
A ′ = A ⋅ diag ( s ) α A' = A \cdot \text{diag}(\mathbf{s})^\alpha A′=A⋅diag(s)α
W ′ = diag ( s ) − α ⋅ W W' = \text{diag}(\mathbf{s})^{-\alpha} \cdot W W′=diag(s)−α⋅W
其中 s \mathbf{s} s 是激活值的通道尺度(例如,每通道的最大绝对值), α ∈ [ 0 , 1 ) \alpha \in [0, 1) α∈[0,1) 是平滑因子。这个变换在数学上是等价的,因为 ( A ⋅ S α ) ⋅ ( S − α ⋅ W ) = A ⋅ W (A \cdot S^\alpha) \cdot (S^{-\alpha} \cdot W) = A \cdot W (A⋅Sα)⋅(S−α⋅W)=A⋅W。然而,通过调整 α \alpha α,可以将激活值的动态范围缩小,使其更适合低比特量化,同时相应地扩大权重的动态范围。通常, α \alpha α 的值会根据每一层的量化难度进行调整。 - 关键特点: SmoothQuant 能够有效地提高 INT8 量化 LLMs 的精度,并且相对容易集成到现有的推理框架中,因为它不引入额外的推理操作。
- 优缺点与解析: 优点是在 INT8 量化下精度提升显著,易于实现,并且不需要额外的推理开销。它通过平衡激活值和权重的动态范围,有效地解决了低比特量化的一个关键瓶颈。缺点是平滑因子 α \alpha α 的选择可能需要根据具体的模型和数据集进行调整,且对于极低比特量化(如 INT4)的提升可能不如 AWQ 等方法显著。
- 相关论文:
- [4] SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. arXiv preprint arXiv:2211.10438, 2022.
2.5 QLoRA: 量化感知低秩适配器微调
- 核心思想与深入解析: QLoRA (Quantization-aware Low-Rank Adaptation) 是一种参数高效的微调方法,其核心在于对预训练的 LLM 进行 4 比特 NormalFloat (nf4) 量化 (这可以看作是一种训练后的量化方法),然后在此基础上添加低秩适配器进行微调。QLoRA 的核心技术包括:4 比特 NormalFloat (nf4) 量化,这是一种针对正态分布数据优化的信息理论最优量化数据类型;双重量化 (Double Quantization),进一步减少量化常数的内存占用;以及分页优化器 (Paged Optimizers),利用 NVIDIA Unified Memory 的特性来避免 GPU 内存不足的错误。在微调过程中,只有新增的低秩适配器的参数会被更新。低秩适配器通过学习两个小矩阵 A ∈ R d × r A \in \mathbb{R}^{d \times r} A∈Rd×r 和 B ∈ R r × k B \in \mathbb{R}^{r \times k} B∈Rr×k 来近似原始权重矩阵的更新 Δ W ≈ B A T \Delta W \approx BA^T ΔW≈BAT,其中 r r r 是一个远小于原始权重矩阵秩的超参数。
- 关键特点: QLoRA 实现了在消费级 GPU 上进行大规模 LLM 微调的能力,显著降低了显存占用,同时在许多任务上取得了与全精度微调相当的性能。
- 优缺点与解析: 优点是极大地降低了 LLM 微调的资源需求,可以使用较小的硬件进行微调,并且 nf4 量化在低精度下表现良好。缺点是主要应用于微调场景,基础模型的性能仍然受到 4 比特量化的影响,并且引入了额外的适配器参数。
- 相关论文:
- [5] QLoRA: Efficient Finetuning of Quantized LLMs. arXiv preprint arXiv:2305.14314, 2023.
3. DeepSeek 的 FP8 量化探索
DeepSeek 在其 LLM 的优化方面进行了积极的探索,并且在 FP8(8-bit Floating Point)量化方面取得了一些进展。FP8 作为一种新兴的低精度浮点数格式,旨在提供比 INT8 更高的精度,同时保持良好的性能,这使其成为在精度敏感型任务中替代 INT8 的一个潜在选择。
根据我们之前的搜索结果,DeepSeek 在 FP8 量化方面的一些关键点以及更深入的解析包括:
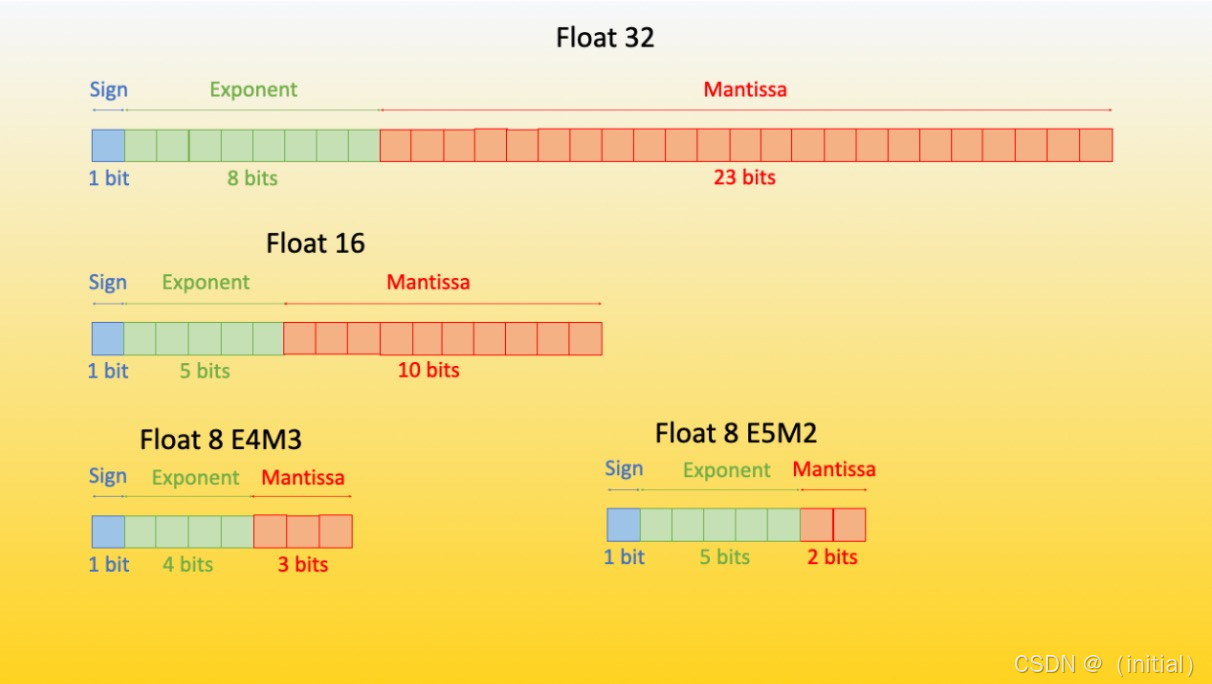
- FP8 格式与选择: FP8 主要有两种格式:E4M3 (1 符号位, 4 指数位, 3 尾数位) 和 E5M2 (1 符号位, 5 指数位, 2 尾数位)。E4M3 的动态范围为 [ − 2 7 , 2 7 ) [-2^7, 2^7) [−27,27),精度约为 2 − 3 2^{-3} 2−3;E5M2 的动态范围为 [ − 2 15 , 2 15 ) [-2^{15}, 2^{15}) [−215,215),精度约为 2 − 2 2^{-2} 2−2。DeepSeek 可能会根据模型的具体需求和硬件支持情况选择合适的 FP8 格式。
- 训练中的 FP8 混合精度 (FP8-LM): DeepSeek 的 FP8-LM 框架在训练 GPT-175B 模型时展现了显著的效率提升。这得益于现代 NVIDIA GPU(如 H100)中 Tensor Core 对 FP8 格式的高效支持。FP8 混合精度训练通常涉及在模型的前向和反向传播中使用 FP8 格式进行计算,同时使用更高精度(如 FP16 或 FP32)进行参数更新,以保证训练的稳定性。DeepSeek 采用了 tile-wise 和 block-wise 的细粒度量化策略,这可能有助于更好地处理模型内部不同区域数值分布的差异,并提高量化精度。他们还通过统计分析自动调整张量的缩放因子,以确保梯度值在 FP8 的表示范围内。
- 相关信息来源:
- [6] DeepSeek Technical Analysis — (5) FP8 Training | by Jinpeng Zhang | Feb, 2025 - Medium: https://dataturbo.medium.com/deepseek-technical-analysis-5-fp8-training-ff34768727b8
- 相关信息来源:
- 推理中的 FP8 量化: DeepSeek 将其模型(例如 DeepSeek-R1-Distill-Qwen-32B)的权重和激活值量化到 FP8 进行推理,实现了模型大小和 GPU 内存需求的显著降低(约 50%)。他们对 Transformer 模块中的线性算子进行了量化,并采用了对称的逐通道(权重)和逐 token(激活值)的量化方案。对称量化通常更易于实现和加速。
- 相关信息来源:
- [7] neuralmagic/DeepSeek-R1-Distill-Qwen-32B-FP8-dynamic - Hugging Face: https://huggingface.co/neuralmagic/DeepSeek-R1-Distill-Qwen-32B-FP8-dynamic
- 相关信息来源:
- 块状 FP8 量化 (Blockwise FP8 Quantization) 的推理: DeepSeek v3 模型使用了块状 FP8 量化策略,其中每个小的权重块独立计算缩放因子,这可以提供更细粒度的量化控制,更好地适应模型内部数值分布的局部变化,从而提高量化精度。
- 相关信息来源:
- [8] [float8] Add support for blockwise fp8 quantization scheme used in DeepSeek v3 · Issue #1594 · pytorch/ao - GitHub: https://github.com/pytorch/ao/issues/1594
- 相关信息来源:
- 高精度累加: 为了在使用 FP8 进行快速计算的同时,尽量减小由于低精度带来的舍入误差,DeepSeek 在进行矩阵乘法累加等操作时,可能会使用更高的精度(如 FP16 或 FP32)进行累加。
- 相关信息来源:
- [9] Bits and Business: FP8 quantization deepdive into DeepSeek’s High-Precision, Low-Bit Revolution | by Adnan Masood, PhD. - Medium: https://medium.com/@adnanmasood/bits-and-business-fp8-quantization-deepdive-into-deepseeks-high-precision-low-bit-revolution-18649428409a
- 相关信息来源:
4. 结论与展望
总的来说,GPTQ 和 AWQ 更侧重于实现极低的比特率,而 SmoothQuant 在 INT8 量化方面表现出色。SpQR 则致力于实现近乎无损的压缩,QLoRA 则专注于低资源下的微调。DeepSeek 对 FP8 的探索则为精度和性能之间提供了一个新的平衡点。低比特训练后量化技术,包括整数化方法如 GPTQ、AWQ、SpQR 和 SmoothQuant,以及浮点数方法如 DeepSeek 探索的 FP8 量化,都在快速发展,并为大型语言模型的高效部署提供了强大的工具。这些技术各有优势和适用场景,研究人员正不断探索新的方法,以在极低的比特数下进一步提高 LLMs 的精度和性能。未来,我们可以期待更智能、更高效的量化策略出现,例如结合硬件特性的量化方法、动态量化技术以及更完善的混合精度量化方案,从而使得强大的 LLMs 能够更广泛地应用于各种资源受限的场景中。
内容同步在我的微信公众号 :智语Bot
参考资料
- [1] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. arXiv preprint arXiv:2210.17323, 2022.
- [2] AWQ: Activation-aware Weight Quantization for Low-bit Wide Model Compression.** Advances in Neural Information Processing Systems, 2023.
- [3] SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Compression.** arXiv preprint arXiv:2303.15698, 2023.
- [4] SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models.** arXiv preprint arXiv:2211.10438, 2022.
- [5] QLoRA: Efficient Finetuning of Quantized LLMs.** arXiv preprint arXiv:2305.14314, 2023.
- [6] DeepSeek Technical Analysis — (5) FP8 Training | by Jinpeng Zhang | Feb, 2025 - Medium.** https://dataturbo.medium.com/deepseek-technical-analysis-5-fp8-training-ff34768727b8
- [7] neuralmagic/DeepSeek-R1-Distill-Qwen-32B-FP8-dynamic - Hugging Face.** https://huggingface.co/neuralmagic/DeepSeek-R1-Distill-Qwen-32B-FP8-dynamic
- [8] [float8] Add support for blockwise fp8 quantization scheme used in DeepSeek v3 · Issue #1594 · pytorch/ao - GitHub.** https://github.com/pytorch/ao/issues/1594
- [9] Bits and Business: FP8 quantization deepdive into DeepSeek’s High-Precision, Low-Bit Revolution | by Adnan Masood, PhD. - Medium.** https://medium.com/@adnanmasood/bits-and-business-fp8-quantization-deepdive-into-deepseeks-high-precision-low-bit-revolution-18649428409a



















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











