







在第二章中,我们已经介绍了预填充和解码这两个 LLM 推理的核心阶段,并初步认识到 KV 缓存作为关键加速机制在其中的作用。**本章将在此基础上,对 KV 缓存进行更为深入和全面的剖析。**我们将从其底层的原理和数学本质出发,详细分析 KV 缓存在 vLLM 和 Transformers 等主流推理框架中的具体实现方式,探讨 KV 缓存对不同模型架构的适配性,并深入研究一系列实用的优化策略和代码实践,最终通过实操来验证 KV 缓存在提升长文本生成性能方面的显著效果。
3.1 KV 缓存的原理与数学本质
正如我们在第二章中介绍的,KV 缓存是 Transformer 模型在推理过程中用于存储 Key (K) 和 Value (V) 向量的一种优化技术。理解其原理需要回顾自注意力机制的计算过程。
注意力机制中 Key 和 Value 的作用与计算公式:
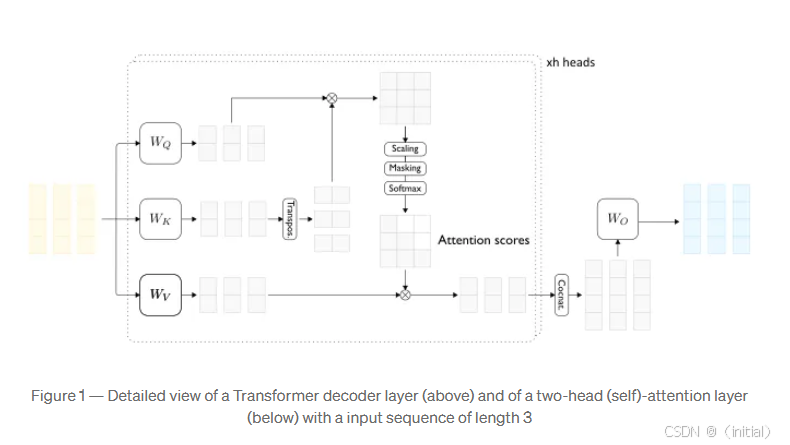
对于输入序列的第 i i i 个 token,其 Query 向量 Q i Q_i Qi 会与所有第 j j j 个 token 的 Key 向量 K j K_j Kj 进行点积,计算得到注意力分数 s i j = Q i ⋅ K j T s_{ij} = Q_i \cdot K_j^T sij=Qi⋅KjT. 经过缩放和 Softmax 归一化后,得到注意力权重 α i j \alpha_{ij} αij. 最终,第 i i i 个 token 的上下文表示 C i C_i Ci 是所有第 j j j 个 token 的 Value 向量 V j V_j Vj 的加权和:
C i = ∑ j = 1 s e q _ l e n α i j V j = ∑ j = 1 s e q _ l e n exp ( s i j / d k ) ∑ l = 1 s e q _ l e n exp ( s i l / d k ) V j C_i = \sum_{j=1}^{seq\_len} \alpha_{ij} V_j = \sum_{j=1}^{seq\_len} \frac{\exp(s_{ij} / \sqrt{d_k})}{\sum_{l=1}^{seq\_len} \exp(s_{il} / \sqrt{d_k})} V_j Ci=∑j=1seq_lenαijVj=∑j=1seq_len∑l=1seq_lenexp(sil/dk)exp(sij/dk)Vj
在这里,Key (K) 用于计算每个 token 之间的相关性(即注意力权重),而 Value (V) 则根据这些权重进行聚合,形成最终的上下文表示。
KV 缓存如何避免重复计算:
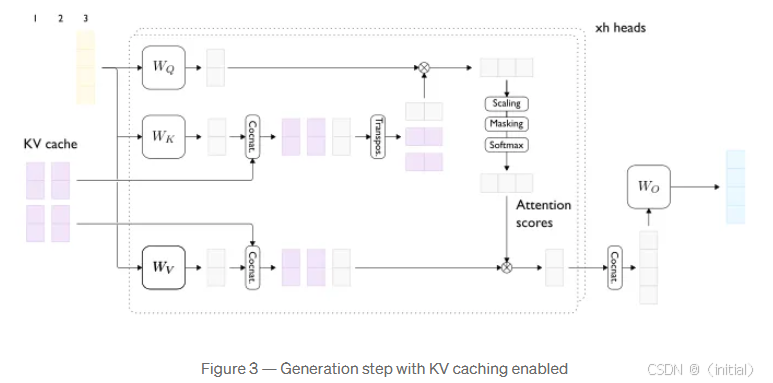
在自回归解码过程中,每生成一个新的 token,模型的输入序列长度就会增加. 如果没有 KV 缓存,为了计算下一个 token 的上下文表示,模型需要对包括原始 Prompt 和所有已生成 token 在内的完整序列重新计算 Q、K 和 V 向量,以及注意力权重。这会带来大量的重复计算,尤其是在生成长文本时。
KV 缓存的核心思想是将已经计算过的 Key 和 Value 向量存储起来,并在后续的解码步骤中直接重用。

通过使用 KV 缓存,在解码的每一步,模型只需要计算当前生成 token 的 Query 向量,并将其与缓存中已有的所有 Key 向量进行比较以计算注意力权重. 然后,利用计算得到的注意力权重,对缓存中对应的 Value 向量进行加权求和. 同时,当前生成 token 的 Key 和 Value 向量也会被添加到 KV 缓存中,供下一步使用. 这样就避免了对历史 token 的 Key 和 Value 向量的重复计算,显著提升了解码效率。
3.2 KV 缓存在主流推理框架中的实现
不同的推理框架对 KV 缓存的实现和优化有所不同。
vLLM 等框架中 PagedAttention 的原理与优势:
正如我们在第二章中初步介绍的,vLLM 等高性能推理框架采用了 PagedAttention 机制来革新 KV 缓存的管理方式,从而实现更高的内存效率和更强的动态性. 为了更好地理解 PagedAttention,我们可以将其与传统的 KV 缓存管理方式进行对比。
传统的 KV 缓存管理通常为每个推理请求(即每个 Prompt 及其生成的序列)在 GPU 显存中分配一块连续的内存空间来存储其 Key 和 Value 向量. 这种做法在处理单个请求时可能没有太大问题,但在高并发的场景下,尤其是当不同请求的序列长度差异很大时,就会暴露出一些明显的缺点:
- 内存碎片: 假设我们同时处理多个长度不一的序列,为了容纳最长的序列,可能会预先分配较大的连续内存块. 当较短的序列结束后,其占用的内存空间可能无法被其他请求充分利用,导致内存碎片。
- 内存浪费: 即使是长度接近的序列,也需要各自独立的连续内存空间,造成一定的内存浪费。
- 难以支持动态长度变化: 在解码过程中,序列长度是动态增长的. 如果预分配的内存空间不足以容纳更长的生成序列,就需要重新分配更大的内存块,这会带来额外的开销。
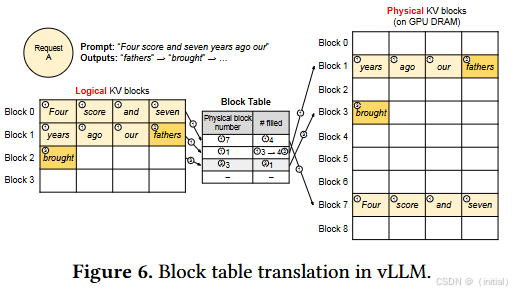
PagedAttention 的核心思想借鉴了操作系统中内存分页管理的机制. 它将每个推理请求的 KV 缓存分割成多个固定大小的小块,这些小块被称为页面(Page). 每个页面可以存储固定数量的 Key 和 Value 向量(例如,对应几个 token 的长度)。
)
逻辑连续,物理不连续: 对于一个推理请求而言,其 KV 缓存在逻辑上仍然是连续的,就像一个完整的数组. 但实际上,这些数据可能被存储在 GPU 显存中多个不连续的页面上. vLLM 通过维护一个**页表(Page Table)**来记录每个逻辑上的 token 位置对应于哪个物理内存页面。
当一个序列在解码过程中增长时,vLLM 只需要按需分配新的空闲页面来存储新增 token 的 Key 和 Value 向量,而无需重新分配整个连续的内存块。
PagedAttention 的优势:
- 极高的内存效率: 由于以页为单位进行分配,可以更精细地管理内存,显著减少内存碎片和浪费. 即使序列长度差异很大,也能更有效地利用 GPU 显存。
- 灵活处理变长序列: 可以轻松地支持同一批次内不同长度的序列,以及单个序列在解码过程中长度的动态增长,只需分配新的页面即可。
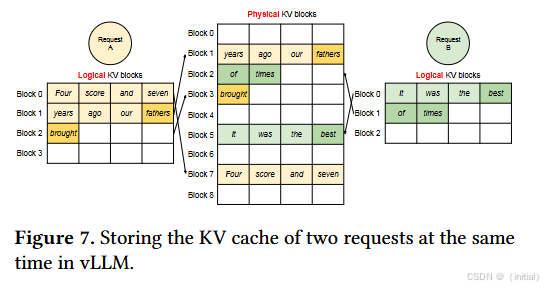
- 高效的 KV 缓存共享与拷贝: 对于具有相同 Prompt 前缀的多个请求(例如在进行 A/B 测试或并行采样时),
vLLM可以通过共享底层的内存页面来实现零拷贝的 KV 缓存共享,极大地节省了内存和拷贝开销. 这对于需要生成多个候选答案的场景非常有用。 - 更好地支持连续批处理(Continuous Batching): PagedAttention 的内存管理方式非常适合与
vLLM的连续批处理技术结合使用. 它可以更灵活地将不同推理请求的计算任务调度到 GPU 上,进一步提高吞吐量。
Transformers 框架中 KV 缓存的结构与操作(代码分析):
在 Hugging Face Transformers 中,KV 缓存通常作为模型 forward 函数的输出(名为 past_key_values)和输入进行传递. past_key_values 是一个包含每一层 Key 和 Value 缓存的元组. 每个元素对应模型的一层,通常是一个包含两个张量(Key 和 Value)的元组。
在首次处理 Prompt 时,past_key_values 为空. 模型计算得到 Key 和 Value 并返回. 在后续的解码步骤中,模型接收到 past_key_values,并将其与当前 token 的输入一起处理,利用缓存的 Key 和 Value 计算注意力,并更新缓存,将当前 token 的 Key 和 Value 添加到对应的层中。
以下代码片段展示了如何逐步解码并使用 past_key_values:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
prompt = "The quick brown fox"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
past_key_values = None
for i in range(10):
outputs = model(input_ids, past_key_values=past_key_values, use_cache=True)
next_token_logits = outputs.logits[:, -1, :]
next_token_id = torch.argmax(next_token_logits, dim=-1).unsqueeze(-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
past_key_values = outputs.past_key_values
print(f"Step {i+1}: Generated token - {tokenizer.decode(next_token_id[0])}")
generated_text = tokenizer.decode(input_ids[0])
print(f"\nGenerated text: {generated_text}")
在这个例子中,outputs.past_key_values 是一个包含 12 个元组(GPT-2 有 12 层),每个元组包含形状为 (batch_size, num_heads, seq_len, head_dim) 的 Key 和 Value 张量. 在每一步解码中,seq_len 会逐渐增加。
3.3 KV 缓存对不同模型架构的影响与适配
KV 缓存是 Decoder-only 模型(如 GPT、LLaMA)实现高效自回归生成的核心. 这类模型在每个解码步骤中都依赖于先前生成的 token 的信息来预测下一个 token,KV 缓存完美地满足了这种需求。
对于 Encoder-Decoder 模型(如 T5、BART),编码器负责处理输入序列并生成上下文表示,这个上下文表示通常以某种形式(例如最终的隐藏状态)传递给解码器. 解码器在生成目标序列时,也会进行自回归生成,并且可以使用 KV 缓存来存储已生成 token 的 Key 和 Value. 然而,与 Decoder-only 模型不同的是,Encoder-Decoder 模型在解码过程中还需要利用编码器提供的上下文信息,这部分信息通常不需要像解码器自身的 KV 缓存那样动态增长. 编码器的输出可以被视为一种形式的 Key 和 Value 信息,供解码器的注意力机制使用。
因此,KV 缓存的概念和实现主要集中在 Decoder-only 模型上,是提升其长序列生成效率的关键. Encoder-Decoder 模型虽然也可能使用类似的技术,但其整体架构和信息流与 Decoder-only 模型存在差异。
3.4 KV 缓存的优化策略与代码实践
为了进一步提升推理性能和降低内存占用,可以采用多种 KV 缓存的优化策略:
-
内存优化技巧:
- KV 缓存的量化: 可以将 KV 缓存中的 Key 和 Value 向量的数据类型从 FP16 降低到 INT8,从而减少一半的内存占用. 一些推理库提供了量化选项.
- vLLM 示例: 在
vLLM中,可以在创建LLM实例时通过quantization参数指定量化方法,例如"int8"。
请注意,量化可能会对模型的精度产生一定影响,需要在实际应用中进行权衡。更细致的量化技术和方法将在后续章节中进行更深入的探讨。from vllm import LLM model_name = "Qwen/Qwen2.5-7B" llm_int8 = LLM(model=model_name, quantization="int8") - vLLM 示例: 在
- KV 缓存的 CPU Offloading: 在 GPU 显存不足的情况下,可以将部分 KV 缓存层卸载到 CPU 内存中. 这可以通过一些库(如 DeepSpeed)来实现。
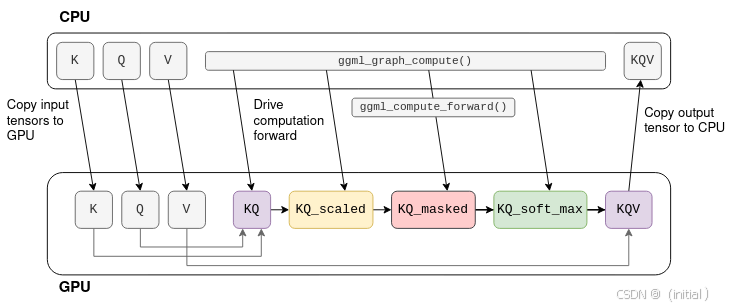
- DeepSpeed 示例 (概念性): 使用 DeepSpeed 进行推理通常需要配置相应的配置文件。以下是一个概念性的代码片段,展示了如何使用 DeepSpeed 的推理优化功能,其中可能包含 KV 缓存的 Offloading:
DeepSpeed 提供了多种优化策略,包括 Zero Offload,可以将模型参数和梯度等卸载到 CPU 或 NVMe 上,间接也可能影响 KV 缓存的管理。具体的 KV 缓存 Offloading 需要更详细的配置。# 注意:这只是一个概念性示例,具体的 DeepSpeed 配置和使用方法较为复杂,请参考 DeepSpeed 文档。 import deepspeed from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "gpt2" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) engine, _, _, _ = deepspeed.initialize( model=model, model_parameters=model.parameters(), config_params={"zero_optimization": {"stage": 0}, "fp16": {"enabled": True}} # 示例配置 ) prompt = "The quick brown fox" input_ids = tokenizer.encode(prompt, return_tensors="pt").to(engine.local_rank) outputs = engine.generate(input_ids, max_length=20) print(tokenizer.decode(outputs[0])) - Context Window Management: 合理设置和管理模型的上下文窗口长度,避免 KV 缓存无限增长导致 OOM 错误. 可以采用截断、滑动窗口等策略. 例如,在调用
llm.generate()时,可以设置max_new_tokens来限制生成长度,间接控制 KV 缓存的大小。
- KV 缓存的量化: 可以将 KV 缓存中的 Key 和 Value 向量的数据类型从 FP16 降低到 INT8,从而减少一半的内存占用. 一些推理库提供了量化选项.
-
选择性 KV 缓存的初步探索:
- Attention Masking 优化: 研究人员正在探索更智能的注意力 Masking 策略,例如 Multi-Query Attention (MQA) 和 Grouped-Query Attention (GQA)。这些技术通过在不同的注意力头之间共享 Key 和 Value 投影,减少了 KV 缓存的大小,同时保持了较高的模型性能。例如,一些新的模型架构如 Falcon 和 Llama 2 就采用了 GQA。
- Sparse Attention 与 KV 缓存的结合: 稀疏注意力机制本身就减少了计算量,与 KV 缓存结合可以进一步降低内存需求. 例如,Longformer、BigBird 等模型采用了稀疏注意力模式,它们在计算注意力时只考虑部分 token,从而减少了 KV 缓存的需求。还有一些研究探索如何动态地选择性保留 KV 缓存中的信息,例如通过重要性评估来决定哪些历史 token 的 KV 需要保留。您可以参考相关论文,例如 “Efficiently Modeling Long Sequences with Structured State Spaces” (S4) 和 “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning” 中也涉及到减少冗余计算和内存访问的策略。
3.5 实操:使用 KV 缓存加速长文本生成,并分析性能提升
我们将使用 vLLM 来演示 KV 缓存(通过 PagedAttention 实现)对长文本生成速度的影响。
import time
import torch
from vllm import LLM
from transformers import AutoTokenizer
model_name = "Qwen/Qwen2.5-7B"
llm = LLM(model=model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompts = ["The quick brown fox jumps over the lazy dog. " * 10]
output_lengths = [100, 500, 1000]
print("Analyzing inference time with varying output lengths (same prompt):")
for prompt in prompts:
prompt_tokens = len(tokenizer.encode(prompt))
print(f"Prompt length (tokens): {prompt_tokens}")
for max_tokens in output_lengths:
start_time = time.time()
outputs = llm.generate(prompt, max_tokens=max_tokens)
end_time = time.time()
inference_time = end_time - start_time
tokens_per_second = max_tokens / inference_time
print(f" Generating {max_tokens} tokens took {inference_time:.4f} seconds ({tokens_per_second:.2f} tokens/s).")
print("\nAnalyzing inference time with varying prompt lengths (fixed output length):")
prompts_long = ["The quick brown fox jumps over the lazy dog. " * 5,
"This is a longer starting sentence. " * 20,
"A very lengthy introduction to the topic at hand, spanning multiple paragraphs. " * 50]
max_tokens = 200
for prompt in prompts_long:
prompt_tokens = len(tokenizer.encode(prompt))
print(f"Prompt length (tokens): {prompt_tokens}")
start_time = time.time()
outputs = llm.generate(prompt, max_tokens=max_tokens)
end_time = time.time()
inference_time = end_time - start_time
tokens_per_second = max_tokens / inference_time
print(f" Generating {max_tokens} tokens took {inference_time:.4f} seconds ({tokens_per_second:.2f} tokens/s).")
# 分析:
# 1. 对于相同的 Prompt 长度,观察生成更长文本时,推理时间是否接近线性增长。这体现了 KV 缓存避免重复计算的效率。
# 2. 比较不同 Prompt 长度对生成固定长度文本的影响。更长的 Prompt 会增加预填充阶段的 KV 缓存大小,可能会略微影响后续解码速度,但主要影响是预填充的时间。
# 3. **监测内存占用:** 您可以使用 `torch.cuda.memory_allocated()` 函数来监测 GPU 内存的占用情况。在生成文本之前和之后分别调用此函数,可以观察 KV 缓存的增长。以下是如何修改代码以包含内存监测:
for prompt in prompts:
# ... (previous code)
for max_tokens in output_lengths:
torch.cuda.reset_peak_memory_stats() # Reset peak memory stats
memory_before = torch.cuda.memory_allocated() / (1024 ** 2) # Memory in MB
start_time = time.time()
outputs = llm.generate(prompt, max_tokens=max_tokens)
end_time = time.time()
memory_after = torch.cuda.memory_allocated() / (1024 ** 2) # Memory in MB
inference_time = end_time - start_time
tokens_per_second = max_tokens / inference_time
print(f" Generating {max_tokens} tokens took {inference_time:.4f} seconds ({tokens_per_second:.2f} tokens/s), Memory change: +{memory_after - memory_before:.2f} MB.")
# ... (rest of the code)
# 请确保您的代码在支持 CUDA 的 GPU 环境中运行。
总结:
本章我们深入探讨了 KV 缓存的原理、实现和优化策略. 通过了解 KV 缓存的工作方式,我们可以更好地理解现代 LLM 如何实现高效的推理. 掌握 KV 缓存的相关知识对于我们未来学习更高级的推理优化技术至关重要。
内容同步在我的微信公众号 智语Bot



















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











