







摘要:PCI 总线的数据交换
前三章还是在讨论PCI的东西,基本了解了PCI之后,再进入后面PCIE的深入学习。
目录
3. 1. 2 PCI 设备 BAR 寄存器和 PCI 桥 Base、 Limit 寄存器的初始化
3. 2. 2 处理器到 PCI 设备的数据传送 3. 2. 3 PCI 设备的 DMA 操作
3. 2. 4 PCI 桥的 Combining、 Merging 和 Collapsing
3. 3. 2 PCI 设备对不可 Cache 的存储器空间进行 DMA 读写
3. 3. 3 PCI 设备对可 Cache 的存储器空间进行 DMA 读写
3. 3. 4 PCI 设备进行 DMA 写时发生 Cache 命中
第 3 章 PCI 总线的数据交换
3. 1 PCI 设备 BAR 空间的初始化
这一章,我个人认为还是偏向理论。虽然在说明方便详细了一些,但还是着重于表面。这在第一章第二章其实都有过类似的内容。
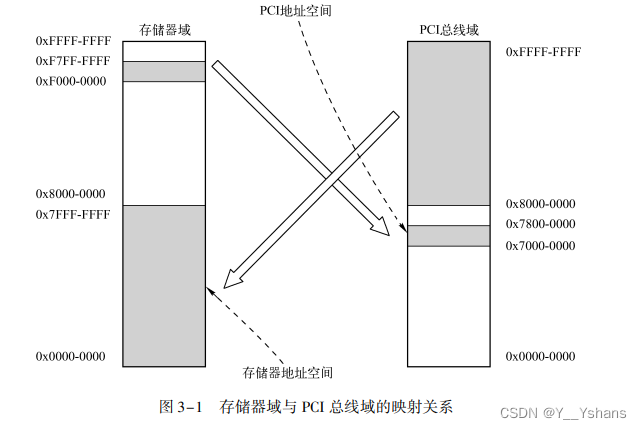
3. 1. 1 存储器地址与 PCI 总线地址的转换
这里只需要知道,存储器地址与PCI总线地址是有一个映射关系即可,并且大家习惯将这个映射关系进行相等处理。下图是书中为了说明:映射关系的存在以及原则上他们是不等的。
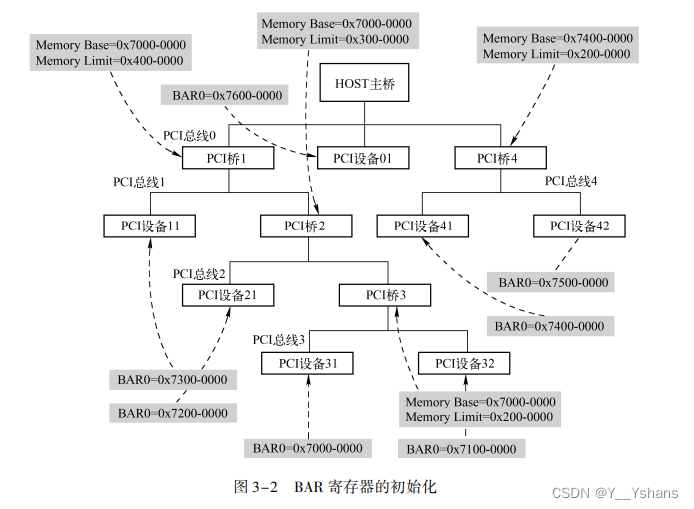
3. 1. 2 PCI 设备 BAR 寄存器和 PCI 桥 Base、 Limit 寄存器的初始化
需要知道这张图,地址空间分配,后面小节会对这张图进行案例讲解。
3. 2 PCI 设备的数据传递
PCI 设备的数据传递使用地址译码方式, 当一个存储器读写总线事务到达 PCI 总线时, 在这条总线上的所有 PCI 设备将进行地址译码, 如果当前总线事务使用的地址在某个 PCI 设 备的 BAR 空间中时, 该 PCI 设备将使能 DEVSEL#信号, 认领这个总线事务。 如果 PCI 总线上的所有设备都不能通过地址译码, 认领这个总线事务时, 这条总线的 “负向译码” 设备将认领这个总线事务, 如果在这条 PCI 总线上没有 “负向译码” 设备, 该 总线事务的发起者将使用 Master Abort 总线周期结束当前 PCI 总线事务。
小节开始之前已经对正向译码和负向译码进行了说明。
3. 2. 1 PCI 设备的正向译码与负向译码
正向译码比较好理解,当有事务的时候,事务所在PCI线都会进行一次译码,看看这个事务属于谁。
但是会存在都不属于的情况,这个时候,书中用了一个案例:
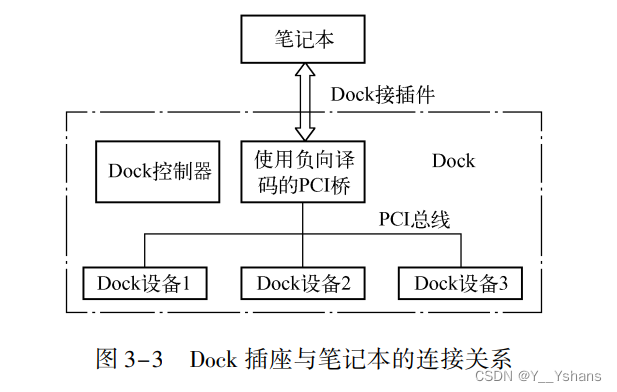
事务会向上传输,更前级或许会有能够接收这个事务的设备或者桥。
如果都没有,那就会报错。
3. 2. 2 处理器到 PCI 设备的数据传送 3. 2. 3 PCI 设备的 DMA 操作
这两小节以图3-2为例,了解一下数据传送以及DMA的过程,着重还是在于事务的请求与释放、正向译码与负向译码、地址映射等。如果理解了这些,其实这里没必要细究。
3. 2. 4 PCI 桥的 Combining、 Merging 和 Collapsing
这三个东西相当于对PCI桥的优化,从而提高数据传递的效率。
combing:
PCI 桥可以将接收到的多个存储器写总线事务合并为一个突发存储器写总线事务。 PCI 桥进行这种 Combining 操作时需要注意数据传送的 “顺序” 。
Merge:
PCI 桥可以将收到的多个对同一个 DW 地址的 Byte、 Word 进行的存储器写总线事务, 合并为一个对这个 DW 地址的存储器写总线事务。
Collapsing:
Collapsing 指 PCI 桥可以将对同一个地址进行的 Byte、 Word 和 DW 存储器写总线事务合 并为一个存储器写操作。(PCI几乎不支持这个方法)
3. 3 与 Cache 相关的 PCI 总线事务
PCI 总线规范定义了一系列与 Cache 相关的总线事务, 以提高 PCI 设备与主存储器进行 数据交换的效率, 即 DMA 读写的效率。 当 PCI 设备使用 DMA 方式向存储器进行读写操作 时, 一定需要经过 HOST 主桥, 而 HOST 主桥通过 FSB 总线㊀ 向存储器控制器进行读写操作 时, 需要进行 Cache 共享一致性操作。
3. 3. 1 Cache 一致性的基本概念
cache一致性应该是重中之重。一定要弄清楚什么是MESI协议。
(这里将内存和存储器看成一个东西)
M(Modified) :这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。
E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中。
S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中。
I(Invalid) :这行数据无效
(这里的图参考了其它的文章:Cache 一致性_校哥-5207的博客-CSDN博客_cache一致性)
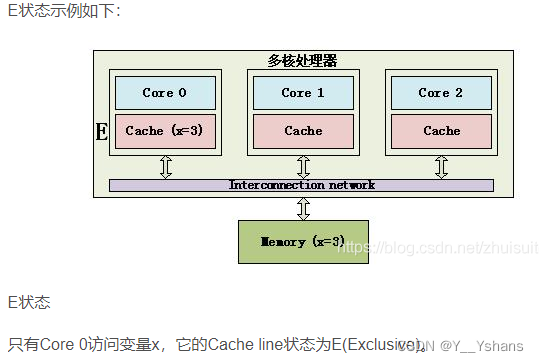
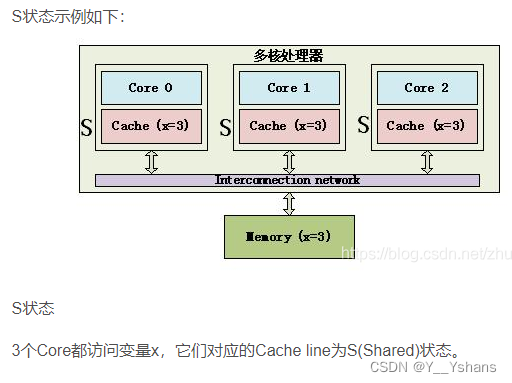
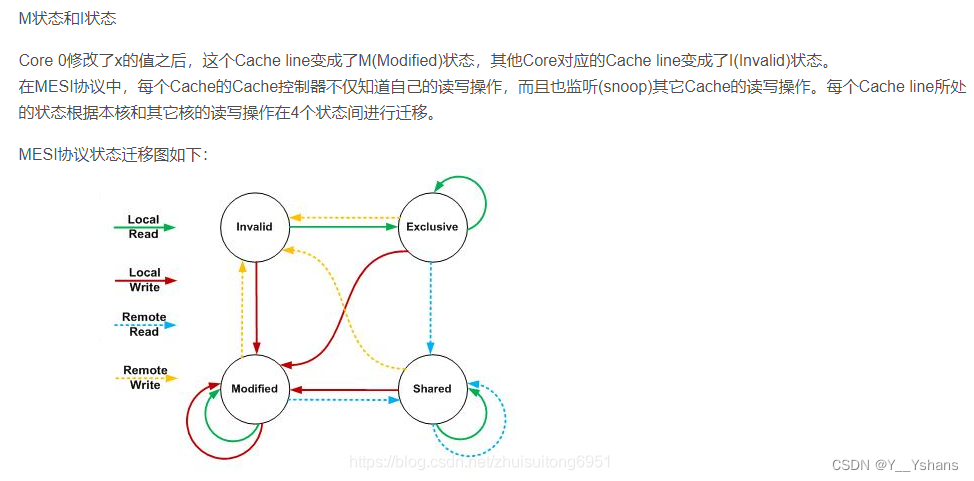
MESI 协议还存在一些变种, 如 MOESI 协议和 MESIF 协议。AMD 处理器就使用 MOESI 协议。
MOESI 协议引入了一个 O (Owned) 状态, 并在 MESI 协议的基础上, 重新定义了 S 状 态, 而 E、 M 和 I 状态和 MESI 协议的对应状态相同。
O(Owned):这行数据有效,cache的数据和内存中的数据不一致,数据存在于两个及以上的Cache中。如果主存储器的数据在多个 CPU 的 Cache 中都具有副本时, 有且仅有一个 CPU 的 Cache 行状态为 O, 其他 CPU 的 Cache 行状态只能为 S
S(Shared):如果其它Cache中存在O的时候,表明Cache中的数据与内存中的不一致,如果其它Cache都是S的时候,表明Cache行中的数据与内存的一致。
Probe Read:主设备从CPU中读
Probe Write:主设备写到CPU中
“Read Hit” 和 “Write Hit” 表示主设备在本地 Cache 中获得数据副本
“Read Miss” 和 “Write Miss” 表示主设备没有在本地 Cache 中获得数据副本
“ Probe Read Hit” 和 “ Probe Write Hit” 表示主设备在其他 CPU 的 Cache 中获得数据副本
在 SMP 处理器系统中, 每一个 CPU 都使用 HIT#和 HITM#信号反映 HOST 主桥访问的地 址是否在各自的 Cache 中命中。 当 HOST 主桥访问存储器时, CPU 将驱动 HITM#和 HIT#信 号, 其描述如表 3-1 所示。
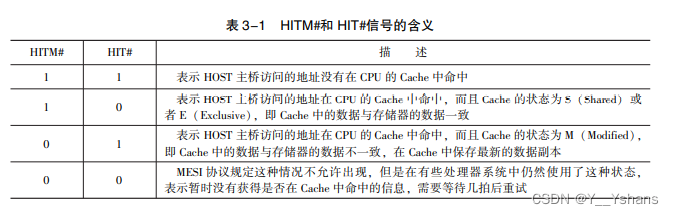
Cache 一致性协议中使用的 Agent
Request Agent:FSB 总线事务的发起设备,这里特指HOST主桥。
Snoop Agents:FSB 总线事务的监听设备。 Snoop Agents 为 CPU。
Response Agent:FSB 总线事务的目标设备。 在本节中, Response Agent 特指存储器控 制器。
FSB 的总线事务
FSB可以理解为处于HOST主桥和CPU之间的总线
Request Phase:Request Agent 在获得 FSB 的地址总线的使用权后, 在该阶段将访问数 据区域的地址和总线事务类型发送到 FSB 上。
Snoop Phase:Snoop Agents 根据访问数据区域在 Cache 中的命中情况, 使用 HIT#和 HITM#信号, 向其他 Agents 通知 Cache 一致性的结果。 有时 Snoop Agent 需要将数据 回写到存储器。
Reponse Phase:Response Agent 根据 Request 和 Snoop Phase 提供的信号, 可以要求 Re⁃ quest Agent 重试 (Retry) , 或者 Response Agent 延时处理 (Defer) 当前总线事务。
Data Phase:一些不传递数据的 FSB 总线事务不包含该阶段。 该阶段用来进行数据传 递, 包括 Request Agent 向 Response Agent 写入数据; Response Agent 为 Request Agent 提供数据; 和 Snoop Agent 将数据回写到 Response Agent。
3. 3. 2 PCI 设备对不可 Cache 的存储器空间进行 DMA 读写
在 x86 处理器中, PCI 设备向不可 Cache 的存储器空间进行读操作时, CPU 也必须进行Cache 共享一致性操作, 而这种没有必要的 Cache 共享一致性操作将影响 PCI 总线的传送效 率。 当 PCI 设备所访问的存储器空间没有在 CPU 的 Cache 命中时, CPU 会通知 FSB, 数据没 有在 Cache 中命中, 此时 PCI 设备访问的数据将从存储器中直接读出。 x86 处理器在前端总线上进行 Cache 共享一致性操作时, 需要使用 Snoop Phase, 如果 PCI 设备能事先得知所访问的存储器是 “不可 Cache 的” , 就不必在前端总线上进行 Cache 共享一致性操作, 即 FSB 总线事务不必包含 Snoop Phase, 从而可以提高前端总线的使用效 率。 但是 x86 处理器并不支持这种方式。
在 MPC8548 处理器中, HOST 主桥可以通过 PIWARn 寄存器㊀ 的 RTT 字段和 WTT 字段 预知 PCI 设备访问的存储器空间是否为可 Cache 空间。 当 HOST 主桥访问 “不可 Cache 空间 时” , 可以使用 FSB 总线的 “不进行 Cache 一致性” 的总线事务。
3. 3. 3 PCI 设备对可 Cache 的存储器空间进行 DMA 读写
过程如下:
首先HOST主桥会发起存储器读总线事务, 并在 Request Phase 中提供地址。CPU在 Snoop Phase 进行总线监听, 并通过 HIT#和 HITM#信号将监听结果通知给 Response Agent。
如果Cache为E:内存和Cache数据一致,直接拿Cache的数据
如果Cache为M:要求CPU将 Cache 中的数据回写到存储器, 并将 Cache 行状态更改为 E。CPU 在 Data Phase 将 Cache 中的数据回写给存储器控制器, 同时为 HOST 主桥提供数据。
如果没有命中Cache:CPU会通知FSB,存储器控制器会将数据提供给HOST主桥
3. 3. 4 PCI 设备进行 DMA 写时发生 Cache 命中
Cahce没有命中的过程是很好理解的。Cache命中的详细过程会复杂一些。
当 Cache 行状态为 E 时,此时PCI设备的写数据比较新。有两种方法,CPU在Snoop Phase时对Cache进行 I(使无效) 操作,然后通过FSB写入存储器。另一种方法,通过FSB直接写入存储器,再将Cache置M(这里要注意的是,虽然M表明Cache和存储器中不一致,但是可以提前改掉存储器的值然后再改M状态)
Cache 行状态为 S 时的处理情况与状态为 E 时的处理情况大同小异
M状态比较复杂:
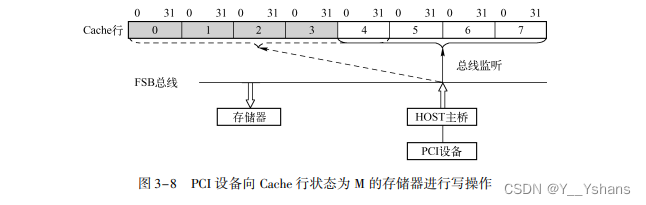
假设此时在 Cache 行中, 阴影部分的数据比存储器中的数据新, 而其他数据与存储器保 持一致,此时一个 PCI 设备将 4 个双字 (第 4 ~ 7 个双字) 的数据写入到一个存储器中, 这 4 个双字所访问的数据在某个 CPU 的 Cache 行中命中, 而且该 Cache 行的状 态为 M, 而且这个 Cache 行的前 4 个双字曾被处理器修改过。
这个时候就不能简单的把另一个Cache置E或者S,而把为更新到存储器的阴影部分置为无效,这会导致处理器系统的崩溃。
为此 HOST 主桥需要专门处理这种情况, 不同的 HOST 主桥采用了不同的方法处理这种 情况, 但无外乎以下三种方法。
(1)一旦发现已经有了M状态,优先处理M状态,其它操作都将等待
(2)发现有M状态,先写入存储器缓冲区;其它Cache命中,输入另一个存储器缓冲区;最后缓冲区合并再汇入存储器
(3)与2类似,但是不理解
3. 3. 5 DMA 写时发生 Cache 命中的优化
当设备进行存储器写时, 如果可以对 Cache 直接进行写操作, 即便这个 存储器写命中了一个状态为 M 的 Cache 行, 也不必将该 Cache 行的数据回写到存储器中, 而 是直接将数据写入 Cache, 之后该 Cache 行的状态依然为 M。
那么这里会遇到的问题是,可能会有多级Cache(L1、L2、L3)
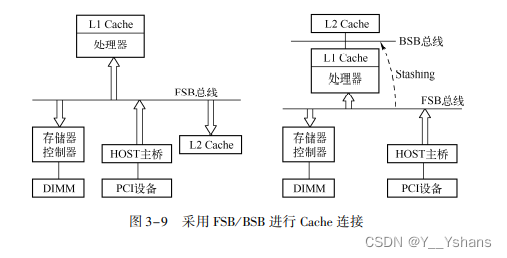
采用BSB总线提供一个通道给L2 Cache
3. 4 预读机制
无论 Cache 的命中率有多高, 总有发生 Cache 行 Miss 的情况。 一旦 Cache 行出现 Miss, 处理器必须启动存储器周期, 将需要的数据从存储器重新填入 Cache 中, 这在某种程 度上增加了存储器访问的开销。 使用预读机制可以在一定程度上降低 Cache 行失效所带来的影响。
3. 4. 1 指令 Fetch
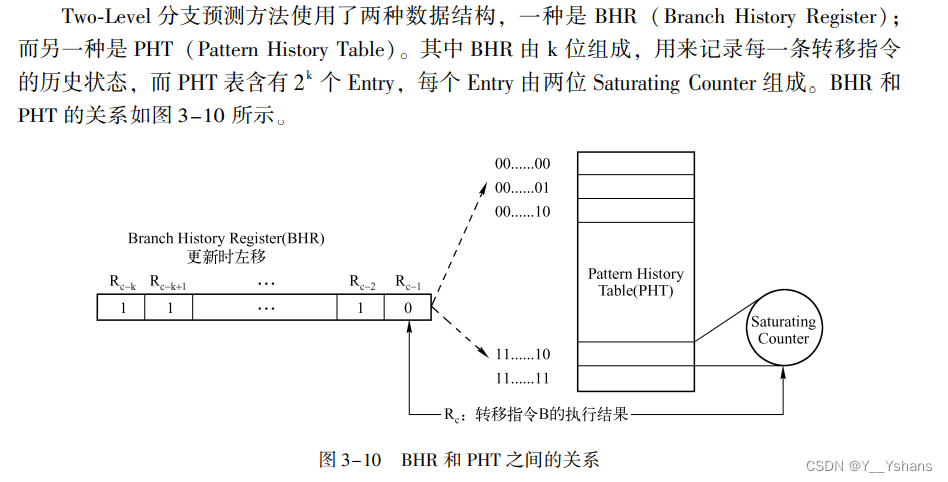
在 CPU 中通常设置了分支预测单元 (Branch Predictor)这些分支预测策略主要分为静态预测和动态预测两种方法。
CPU 使用的动态预测机制是本节研究的重点。
目前在高性能处理器中, 常使用 BTB ( Branch Target Buffer) 管理分支预测指令。
(看不懂)
3. 4. 2 数据预读
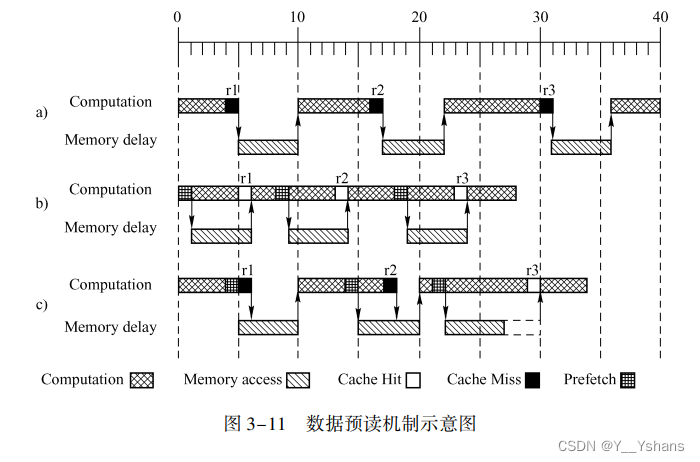
a没有采用预读机制,b是理想的预读机制,c是实际情况中的预读机制。
预读机制能够提高效率。
3. 4. 3 软件预读
在处理器真正需要数据之前, 向存储器发出预读请求, 这个预读请求不需要等待数据真正到达存储器之后, 就可以执行完毕。
软件预读示例:

3. 4. 4 硬件预读
采用硬件预读的优点是不需要软件进行干预, 也不需要浪费一条预读指令来进行预读。
但是无论使用什么方法都无法避免因为预读而造成的 Cache 污染问题, 于是出现了 Stream buffer 机制。 采用该机制, 处理器可以将预读的数据块放入 Stream Buffer 中, 如果处理器使用的数 据没有在 Cache 中, 则首先在 Stream Buffer 中查找, 采用这种方法可以消除预读对 Cache 的 污染, 但是增加了系统设计的复杂性。
3. 4. 5 PCI 总线的预读机制
不是所有的外部设备都支持预读, 只有 “ well⁃behavior” 存储器 支持预读。
well⁃behavior 存储器具有以下特点:
(1)对这些存储器设备进行读操作时不会改变存储器的内容。
(2) 对 “well⁃behavior” 存储器的多次读操作, 可以合并为一次读操作。
(3) 对 “well⁃behavior” 存储器的多次写操作, 可以合并为一次写操作。
(4) 对 “well⁃behavior” 的存储器写操作, 可以合并为一次写操作。
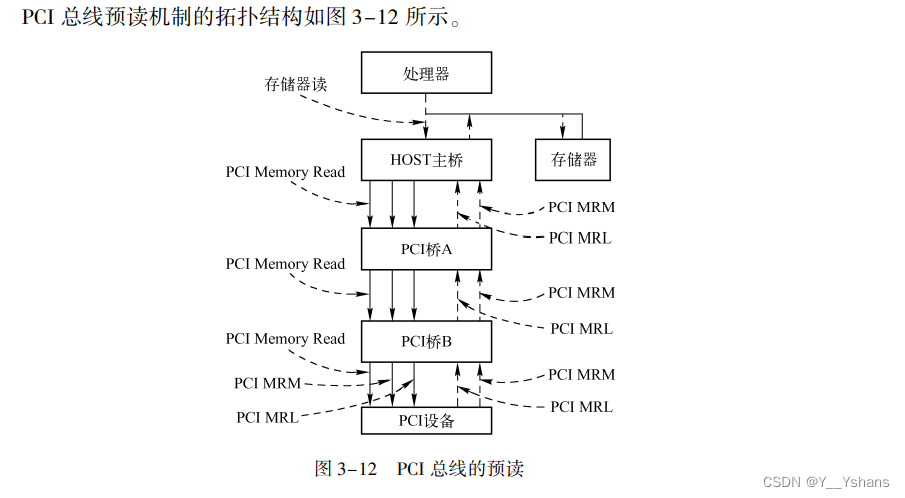
可以看看原文对 “HOST 处理器预读 PCI 设备” 以及 “PCI 设备读取存储器” 的说明
总结
本章重点介绍了 PCI 总线的数据交换。 其中最重要的内容是与 Cache 相关的 PCI 总线事 务和预读机制。 虽然与 Cache 相关的 PCI 总线事务并不多见, 但是理解这些内容对于理解 PCI 和处理器体系结构, 非常重要。 第 I 篇的主体是以 PCI 总线为例, 说明一个局部总线在处理器系统中的作用, 这也是笔 者写作本书的初衷。 PCI 总线作为一个局部总线, 在设计思路上, 与其他局部总线并没有本 质的不同。 在本篇中, 最重要的内容是局部总线的设计与实现方法, 希望读者阅读本书时, 不要仅仅将目光锁定在 PCI 总线本身。 本书的第 II 篇内容与第 I 篇密切相关, 希望读者在真正理解第 I 篇内容的基础上阅读第 II 篇。 PCIe 总线在继承 PCI 总线部分内容的基础上做出了许多重大调整。 但是从处理器体 系结构的角度来看, PCIe 总线依然是局部总线, 这条局部总线与 PCI 总线以及其他平台的 局部总线相比, 并不存在本质的不同。 而理解这些局部总线的关键, 仍然是深入理解处理器 的体系结构。
参考文章:
PCI_Express_体系结构导读——王齐















 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









