






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
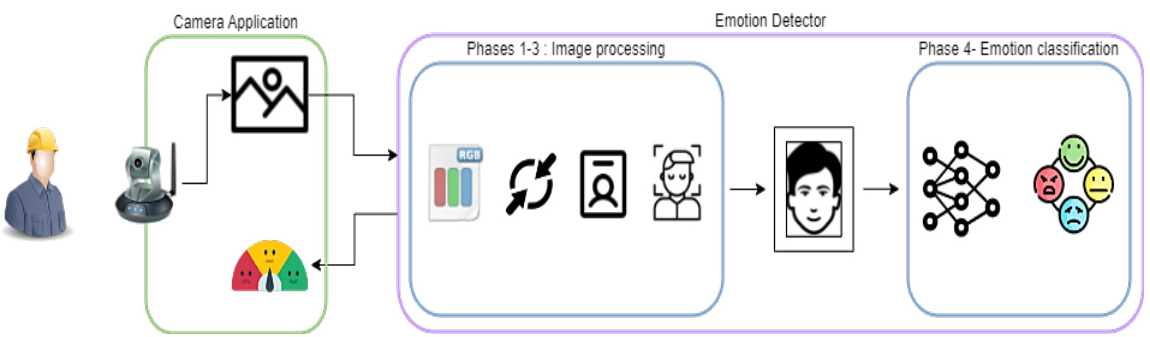
基于CNN的实时情绪检测研究
使用深度学习模型CNN进行实时情绪检测是一种应用广泛的研究方向。步骤:
1. 数据收集和标注:收集包含情绪标签的大量人脸图像数据集。可以通过各种渠道收集,如在线数据库或自行采集。确保数据集中有多样性的情绪表达,如喜悦、愤怒、悲伤、惊讶等。同时,为每个人脸图像标注相应的情绪标签。
2. 数据预处理:对收集到的人脸图像进行预处理,如人脸检测和对齐,以确保输入CNN模型的图像具有统一的尺寸和定位。
3. 构建CNN模型:使用卷积神经网络(CNN)来构建情绪检测模型。可以选择已经被广泛应用的CNN架构,如VGGNet、ResNet或Inception等,或者根据具体需求设计自定义的CNN架构。
4. 数据集划分和训练:将数据集划分为训练集、验证集和测试集。使用训练集对CNN模型进行训练,并用验证集调整超参数和模型结构,以提高模型的性能。确保使用数据增强技术来扩充训练数据的多样性。
5. 模型评估和调整:使用测试集对训练好的CNN模型进行评估。计算准确率、召回率、F1分数等性能指标,评估模型的效果。如果模型性能不理想,可以尝试调整超参数、增加数据量或进行模型结构优化。
6. 实时情绪检测:基于已经训练好的CNN模型,实现实时情绪检测的应用。通过在实时视频流或摄像头捕捉的图像上应用模型,提取人脸并预测情绪标签。可以使用OpenCV等库来实现实时视频处理和人脸检测。
7. 模型优化和部署:根据实际需求,对模型进行优化和改进。可以尝试剪枝和量化等方法来减小模型的大小和计算量,并进行模型压缩和加速。最后,将训练好的模型部署到目标设备上,实现实时情绪检测的应用。
通过以上步骤,可以使用深度学习模型CNN进行实时情绪检测研究。这种技术在情感分析、人机交互、智能监控等领域具有潜在的应用价值。
深度学习是一种监督式机器学习,其中模型学习直接从图像、文本或声音执行分类任务。
深度学习通常使用神经网络实现。
术语“深度”是指网络中的层数——层越多,网络越深。
卷积神经网络可以有数百层,每一层都学习检测图像的不同特征。
滤波器以不同的分辨率和大小应用于每个训练图像,并且每个卷积图像的输出用作下一层的输入。
过滤器可以从非常简单的特征开始,例如亮度和边缘,然后深入提取复杂的特征。
与其他神经网络一样,CNN 由输入层、输出层和介于两者之间的许多隐藏层组成。
一、研究背景与意义
-
实时情绪检测的核心价值
实时情绪检测通过分析面部表情、语音、生理信号等多模态数据,动态捕捉人类情绪变化。其应用涵盖:- 心理健康监测:抑郁症、焦虑症等情绪障碍的早期预警。
- 人机交互优化:智能客服、虚拟助手根据用户情绪调整交互策略。
- 教育领域:实时分析学生课堂情绪以优化教学方式。
- 公共安全:机场、车站等场所的情绪异常检测。
-
CNN的核心优势
卷积神经网络(CNN)在图像特征提取中表现卓越,尤其适合处理面部表情等高维数据:- 空间层次化特征学习:通过卷积层自动捕获局部表情细节(如眼周、嘴角变化)。
- 端到端训练:无需人工设计特征,直接从原始数据学习情绪表达模式。
二、核心技术实现
- CNN模型架构设计
-
典型架构(以面部表情为例):
# 示例代码(基于Keras,[[53]]) model = Sequential() model.add(Conv2D(32, (3,3), activation='relu', input_shape=(48,48,1))) # 输入48x48灰度图 model.add(MaxPooling2D((2,2))) model.add(Conv2D(64, (3,3), activation='relu')) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dense(7, activation='softmax')) # 输出7类情绪 -
优化策略:
-
- 多尺度卷积核:结合5×1和1×3核分别提取时间与空间特征。
- 轻量化设计:MobileNetV2的深度可分离卷积减少参数量80%。
- 动态图卷积:利用GCN捕捉面部关键点拓扑关系。
- 实时性保障技术
- 硬件加速:
- GPU并行计算:利用CUDA加速卷积运算。
- 边缘设备部署:TensorFlow Lite在树莓派4B实现30FPS推理。
- 软件优化:
- 图像预处理流水线:OpenCV的DNN模块优化图像缩放与归一化。
- 异步处理:分离特征提取与分类线程以降低延迟。
三、数据集与预处理
-
常用数据集
数据集 规模 情绪类别 特点 FER2013 35,887图像 7类(愤怒、喜悦等) 灰度48×48,含噪声 CK+ 593序列 6类(含轻蔑) 高分辨率动态表情 SEED 15被试EEG 3类(正/负/中性) 多模态(EEG+视频) -
关键预处理步骤
- 面部对齐:MTCNN检测68个关键点并标准化。
- 数据增强:随机旋转(±20°)、剪切(0.2)、HSV色彩扰动。
- 噪声抑制:CLAHE算法增强低光照下的表情对比度。
四、性能评估与挑战
-
评估指标
- 准确率:在CK+数据集上最优模型达99.73%。
- 实时性:延迟≤33ms(30FPS)为实时标准。
- 鲁棒性:跨种族/光照条件的识别方差需<15%。
- 准确率:在CK+数据集上最优模型达99.73%。
-
技术挑战
- 计算资源限制:移动端模型需压缩至<5MB。
- 数据偏差:现有数据集多为表演性表情,真实场景准确率下降20%。
- 多模态融合:EEG+面部表情的同步率误差需<100ms。
-
伦理与隐私
- 匿名化处理:实时模糊非目标人脸。
- 数据加密:AES-256加密传输生理信号。
五、应用场景与未来方向
-
落地案例
- 医疗领域:结合可穿戴设备实时监测抑郁症患者情绪波动。
- 智能汽车:驾驶员分心/疲劳检测系统。
- 零售分析:商场摄像头统计顾客对商品的即时情绪反馈。
-
前沿趋势
- 神经形态计算:基于脉冲CNN的能效比提升10倍。
- 联邦学习:跨机构联合训练模型,保护数据隐私。
- 元宇宙集成:VR环境中实时渲染虚拟角色的情绪表达。
📚2 运行结果





🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]胡建国. 基于表情识别的儿童情绪能力评测系统[D].东南大学,2015.
[2]张波. 连续对话语音愤怒情绪检测算法研究[D].内蒙古大学,2018.

















 3439
3439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









