









一、实验目的
1、理解K-means算法的基本原理和图像颜色聚类的关键要素;
2、学习使用Python编程语言和机器学习开发工具包(scikit-learn)构建K-means模型;
3、编程实现基于K-means的图像颜色聚类程序,并分析实验结果。
二、概要设计
1.Kmeans——一种无监督机器学习的聚类算法
基本原理:在不给出数据类别标签而直接给出样本数据情况下,该算法首先需要确定结果:要把样本聚成k类。这个聚类的过程为:
- 首先在样本特征空间随机初始化(选择)k个样本点,作为初始化聚类的中心点
- 计算各个样本距离哪个中心点(也就是那个类)最近,于是将其划分为这个类
- 对各个类别的所有样本在特征空间中求和取平均计算其新的中心点,更新k个聚类的中心点
- 重复执行b,c步骤直到k个类别的中心点在样本特征空间中不再改变或改变不大(此时说明对样本的聚类已经效果比较好了)

2.本次实验需要完成的聚类任务介绍:用K-means算法实现图像颜色聚类
我们需要聚类的对象为:图像这个网格集合中的像素的rgb像素值。我们需要对这个图像中的像素值进行k聚类。
3.用K-means算法实现图像颜色聚类的算法流程
-
首先获得图像数据(像素点)
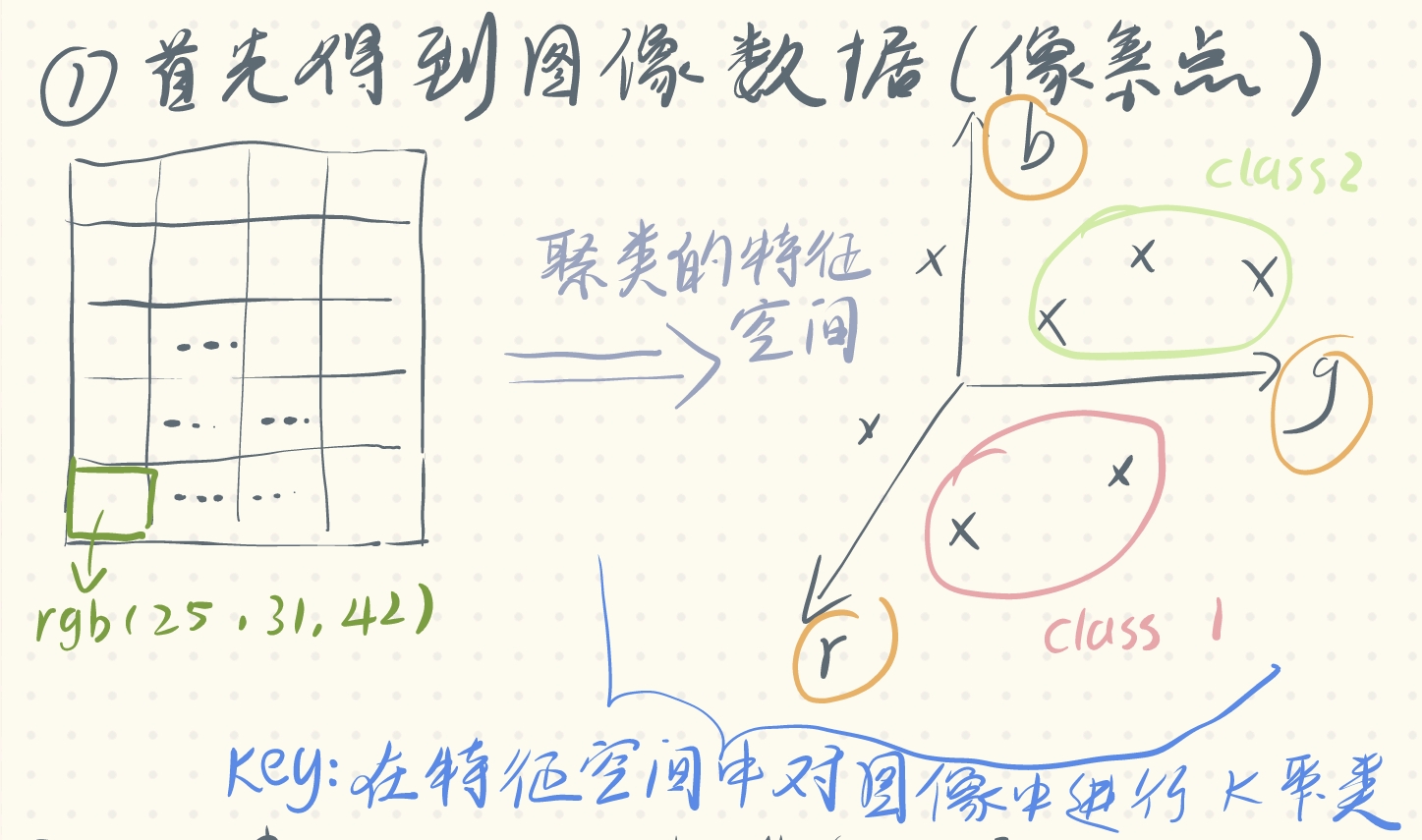
-
构建k-means模型(确定要聚几个类)
-
输入数据进行模型训练
-
得到聚类结果和类别中心点
-
根据聚类结果和类别中心点映射到原图像,对对原图像数据进行聚类处理
三、详细设计(实现代码)
1.首先获得图像数据:加载图像并且将图像转换为二维数组:
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from PIL import Image
# 加载图像
img = Image.open('flower.jpg')
img_data = np.array(img)
# 将图像转换为二维数组
rows, cols, bands = img_data.shape#bands是颜色的通道数
X = img_data.reshape(rows * cols, bands)
2.构建k-means模型(确定分为多少类,这里设置为16类)
# 使用 K-means 算法将颜色值分为 16 个簇
kmeans = KMeans(n_clusters=16, random_state=0)
3.输入数据进行模型训练
kmeans = kmeans.fit(X)
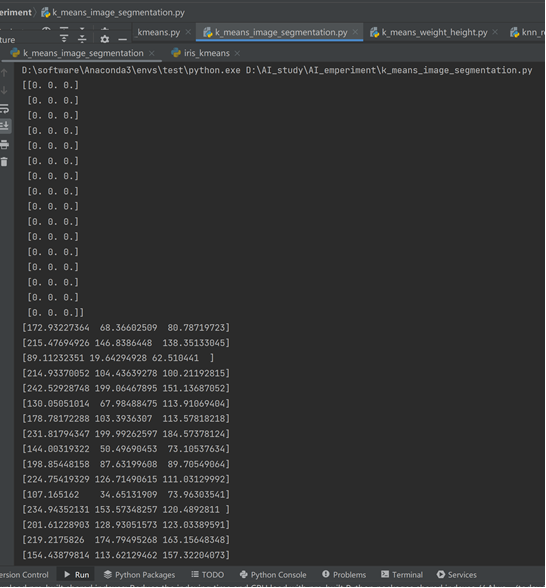
4. 得到聚类结果和类别中心点
# 获取聚类结果和簇中心点
labels = kmeans.labels_
centers = kmeans.cluster_centers_
colors = np.zeros_like(centers)
print(colors)
5. 根据聚类结果和类别中心点映射到原图像,对对原图像数据进行聚类处理
# 将聚类结果重新映射到图像像素值
X_recovered = np.zeros_like(X)
for i in range(6):
X_recovered[labels == i] = centers[i]#colors[i]
print(centers[i])
img_recovered = X_recovered.reshape(rows, cols, bands)
# 绘制原图和聚类后的图像
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
ax[0].imshow(img)
ax[0].set_title('Original Image')
ax[0].axis('off')
ax[1].imshow(img_recovered.astype(np.uint8))
ax[1].set_title('6-color Image')
ax[1].axis('off')
plt.show()
四、实验结果

分析:
- 首先根据控制台输出,我们可以看到聚类后得到了16个类的中心点(聚类结果)
- 根据图像处理结果显示,根据聚类结果的16个聚类中心点rgb颜色值,对原图像进行映射处理后,将原图像中的像素点进行了根据其类别的颜色映射。
-
尝试改变聚类数量
- 由16类到6类)
可以看到,类别减少后,聚类结果得到6个聚类中心点,原图像更加平滑,更加抽象,不如原图像精细。

- 由16类到6类)
-
更改聚类图片,不同图像颜色聚类效果:

可以看到,不同图像,由于像素数值不同,聚类结果以及聚类效果也不同
















 5909
5909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











