







模型
背景:
transformer用到视觉问题上的难处:
transfomer的计算复杂度,
O
(
n
2
)
O(n^2)
O(n2),而像素点的序列长度太长->用特征图当作输入/控制窗口的大小来控制输入序列的长度/2d矩阵的自注意力换成两个1d的自注意力(具体如何实现,参考Stand-alone axial-attention for panoptic segmentation)
但这些都是先用cnn 有不用cnn的方法吗?
-----------------------论文部分--------------------------
摘要:1. 单纯使用transformer进行图片分类也能获得很好的效果 2. 当在大规模数据集上与训练后,再迁移到中小型数据集上,能获得当下最好结果 3. 在取得最好结果的同时,对资源的需求也大幅减少
问题:1. 原本的cnn框架有没有使用预训练?如果没有,如何证明获得最好结果是transformer的功劳? 2. 这三个数据集,都算是中小型数据集吗?
引言:1. 1B=10亿 1M=100万 transformer在nlp领域占据统治地位,然而在视觉领域,仍然以cnn为主流。已经有一些工作,对两者的结合做了尝试(以下论文也证明了某种发展趋势:卷积利用局部性提高了效率缺牺牲了对远距上下文的关注->self-attention帮助完成远距上下文->如何在视觉任务中降低self-attention中
O
(
n
2
)
O(n^2)
O(n2)的时间复杂度成为新的探索方向):
【Non-local Neural Networks】:用非局部均值建立了图片中远像素之间的关系
【End-to-End Object Detection with Transformers】:先cnn,再transformer
【Stand-Alone Self-Attention in Vision Models】:用self-attention完全代替cnn(获得了更少的参数量和相当甚至更高的结果)
【Stand-alone axial-attention for panoptic segmentation】:使用轴注意力替代复杂度高的self-attention(如何将2D注意力分解成两个1D注意力)
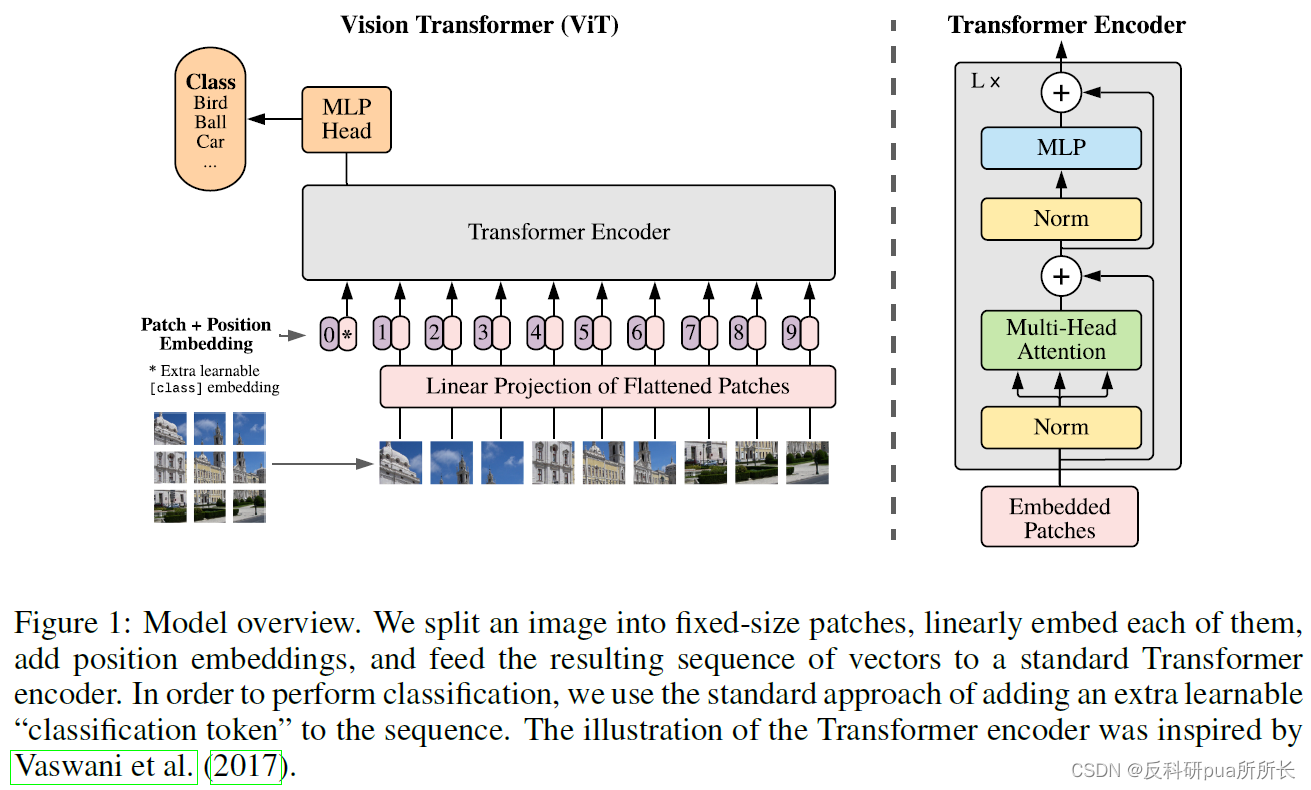
2. 为了直接在视觉领域应用transformer,将一张图切分为多个patch然后送入transformer,以有监督的形式训练transforemer
3. 当在中小型数据集上训练时,结果可能不如resnet,作者认为这是由于transformer缺乏cnn特有的归纳偏置,如空间局部性(得到的特征只与其局部的输入有关)、平移等价性(输入的特征平移到任何位置,卷积核都能找到此位置并被激活)
4. 如果在大型数据集上预训练再到其他任务上微调,则获得了最优结果
相关工作:sparse注意力 轴注意力 image GPT
跟这个论文最像的是ICLR2020的一篇论文【On the relationship between selfattention and convolutional layers】,区别在于这篇文章,只能处理小图片(因为patch设置的太小)
方法:1. 尽可能按照原本的transformer模型来做
2. 在首位加入cls token,用于之后作为整个图像的特征(或者使用所有token特征的平均池化,作者在实验中表明,两者结果相似)
3. 维度推演:输入图片224224 patch1616 -> 输入X196*768(其中196为224/16=14
2
^2
2, 768=16*16*3)-> 线性映射层E 768*768->tranformer输入 197(196+1)*768 -> transformer输出 197*768
后面补充了一些分析:归纳偏置(少了很多图像特有的归纳偏置)
cnn+transformer(不是相关工作中提到的吗?)
高分辨率图片时的微调(位置编码就没用了,那么可以使用位置插值)唯一的归纳偏置?(没听懂)
实验:主要是图三和图四两个图
可视化:第一层学到了什么。与vit的全连接层相比;位置编码的可视化(不太明白);不同注意力层,能注意到的信息
结论:如果在足够多的数据上进行预训练,就可以用transformer替代cnn(训练时间一定很长)
展望:1. 扩展到多模态任务 2. 自监督训练(对比学习的方法)3. cnn transformer和mlp将鹿死谁手 犹未可知
参考:b站视频——ViT论文逐段精读【论文精读】















 3475
3475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









