






作者丨孙文@知乎
来源丨https://www.zhihu.com/question/63159179/answer/257832184
编辑丨3D视觉工坊
主流的方法有下面几种:
基于模板匹配的方法
基于点的方法
基于描述子的方法
霍夫森林(vote based)
Object Coordiantes 回归法
end to end
概率法
下面一一介绍:
1.基于模板匹配的方法

代表论文:
Gradient Response Maps for Real-Time Detection of Textureless Objects
Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes
这个以Stefan Hinterstoisser的LINEMOD为代表。方法是在可能的SE3空间通过渲染对要检测的物体作充分的采样,提取足够鲁棒的模板,再对模板进行匹配就可以大致的估计位姿,最后ICP精化结果。作者在优化模板匹配速度上做了很多工作(看得我头大),效果也确实不错。知乎上面没趣啊同学,讨论了一些LINEMOD的一些细节问题,并做了一些改进。大家可以关注他的github。
2. 基于点的方法
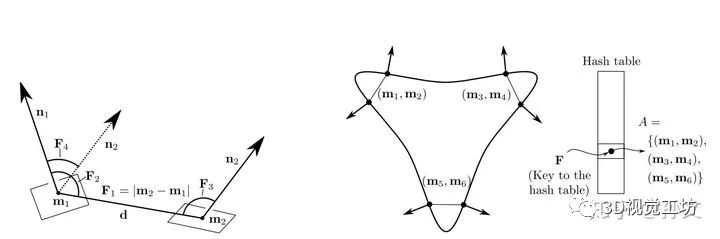
代表论文:
Model Globally, Match Locally: Efficient and Robust 3D Object Recognition (PPF)
Going Further with Point Pair Features(Hinterstoisser)
An Efficient RANSAC for 3D Object Recognition in Noisy and Occluded Scenes(object ransac)
A performance evaluation of point pair features
点方法这个名字是我起的,这类方法基本上是通过点云上面少量的点对构成描述子来做的。最经典的文章就是Bertram Drost的Model Globally, Match Locally: Efficient and Robust 3D Object Recognition。这篇文章,作者的命名为“全局建模,局部匹配”,我觉得非常精确,它非常高度的概括了这个算法的思想。先说全局建模,就是对模型的点云中的所有任意的两个点法都计算PPF描述子,构建模型hash表,以描述子为key,以这两个点法为value。在从scene点晕中匹配的时候,同样对scene中的所有的任意两个点法计算PPF描述子,在模型hash表中查询,这样可以得到所有可能匹配点法对。由于,两个点法对如果匹配,可以计算出其变换的刚体变换矩阵,也就是我们要求的pose。这样可以在SE3的位姿空间进行投票,以消除一些误匹配。这就是局部匹配。当然作者还是做了很多工作来处理SE3空间的投票问题(这不好做)。
Going Further with Point Pair Features这篇论文,Hinterstoisser对PPF做了很多优化工作,让PPF的估计准确率基本可以达到2016年的 state of the art。对于PPF(2010)这样一个简单的算法来说,可以达到这样的性能是非常了不起的。
An Efficient RANSAC for 3D Object Recognition in Noisy and Occluded Scenes是Chavda Papazov的,他好像和Sami Haddadin( franka机器人)是一个组的。这篇文章前面步骤与Drost那篇相同,都是计算PPF描述子构建模型的Hash表,然后对scene点云采样匹配。这里的采样是基于RANSAC的思路,随机取两个点法,得到描述子后丢Hash表匹配,可以计算出一个可能的pose,那么如何知道这个pose是不是正确的呢,Papazov采用的是对于计算出来的pose用一个目标函数作快速的假设检验,留下得分最高的。由于引入了随机采样这个方法每次得出的pose都不一样,速度也是时快时慢,但是贵在有时可以对付及其严重的点云遮盖。
3. 基于描述子的方法
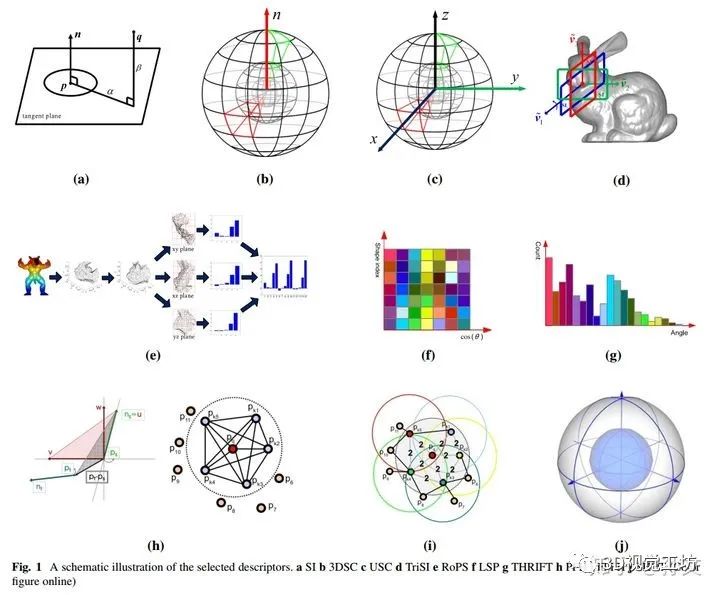
相关关键论文:
Point Cloud Library - Three-Dimensional Object Recognition and 6 DoF Pose Estimation
A Global Hypotheses Verification Method for 3D Object Recognition (假设检验)
A Comprehensive Performance Evaluation of 3D Local Feature Descriptors
由于,我们知道三个对应点对就可以解析的解出pose,所以如何让匹配点对更精确更鲁棒是描述子方法的研究重点,也涌现了很多的方法,比如PFH,FPFH,SHOT等。在得到匹配的点对之后,我们可以按照Point Cloud Library - Three-Dimensional Object Recognition and 6 DoF Pose Estimation文章中给出的local pipline 和global pipline,对点云进行处理来完成pose estimation。A Comprehensive Performance Evaluation of 3D Local Feature Descriptors是国防科技大学郭裕兰教授的一篇关于各种描述子性能的比较综述文章。
4. 霍夫森林(vote based)
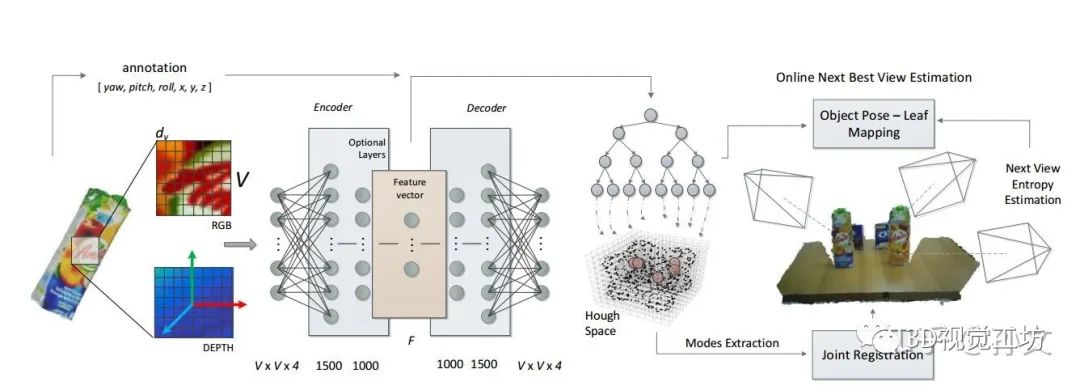
相关关键论文:
Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd(有源码)
Latent-Class Hough Forests for 6 DoF Object Pose Estimation
这两篇文章都使用了一种霍夫森林的方法,其思想是建立图像patch与SE3中的pose的对应关系,就是训练一个随机森林。然后检测的时候从图像中提取patch,在SE3空间投票以推算最终的pose。大概的思想应该是这样子,但是细节部分不是很懂,特别是第二篇,欢迎高手指教。
还有这两篇文章应该是出自同一个组的,而且这个组这两年一直有相关方面的文章。
5. Object Coordinates回归法

代表论文:
Learning 6D Object Pose Estimation using 3D Object Coordinates
Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image(有源码)
这一类方法的特点有两个,一是不使用patch来训练随机森林,这是因为patch大小不好确定,二是不直接建立图像中元素到SE3空间的映射,而是建立图像中元素到Object Coordinates也就是模型自身坐标的映射。第一篇文章中作者构建了一个随机森林,建立了图像中每一个像素与模型坐标的映射。输入一张图像,随机森林可以判断这张图片的每一个像素它属于那个物体,并且告知这个像素在物体的那个部位。有了这个对应关系(当然存在很多误匹配)作者采用了一个基于采样的方法抽取了物体最终的pose。
第二篇文章与第一篇类似,特点是不使用RGBD图像,而使用RGB图像,也可以很好的估计pose。
这两篇文章也是出自一个组,他们最近也有相关的文章。
6. end to end
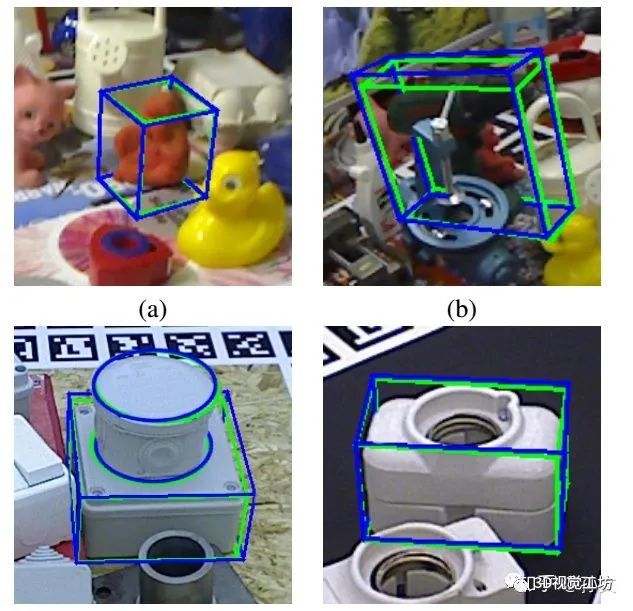
BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects without Using Depth
SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again
这个方向我文章没看太懂,大概都是使用神经网络解决问题,这个方向很热,文章也很多,可以参阅另一个类似的问题。
7. 概率法
Probabilistic Approaches for Pose Estimation
Bingham Distribution-Based Linear Filter for Online Pose Estimation(有源码)
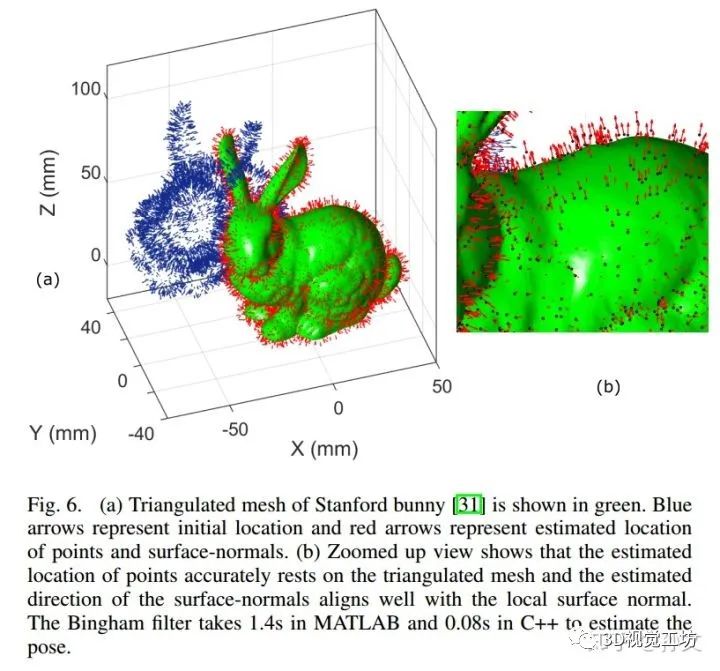
这个叫概率法,不知道恰不恰当。主要提一个概率模型Bingham Distribution,这个模型是对高斯分布的一个拓展,可以对四元数的随机分布建模。有了这个模型,作者构建了一个Bingham distribution-based filtering (BF)来在线的估计pose的旋转部分。这样的迭代下去就可以对两个点云配准。作者表示这个方法对噪声和点云密度鲁棒性很好,而且比之ICP又快又准。
以上是我这两个月,还有更之前所看的资料的一个总结。有一些描述可能有些问题,希望大家指出,也欢迎大家一起交流探讨
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









