






作者丨Heeger@知乎
来源丨https://zhuanlan.zhihu.com/p/387253491
编辑丨3D视觉工坊
本文介绍我们实验室最新发表在IROS 2021上关于机器人持续模仿学习的文章。我们使用深度生成式回放的基本方法,结合生成模型和预测模型,提出了针对于机器人模仿学习数据的一种新的数据回放方法,在一系列虚拟环境和真实环境上的机器人操作任务上获得了最多10个任务的持续模仿学习效果。
文章链接 :https://arxiv.org/abs/2106.09422
开源代码:https://github.com/HeegerGao/CRIL
简介
机器人模仿学习(Imitation Learning,也叫做Learning from Demonstrations)使用人类或者别的机器人提供的专家示教轨迹,使用行为克隆(Behavior Cloning)或者逆强化学习(Inverse Reinforcmeent Learning)的方法对示教数据进行模仿,以此学到示教中包含的技能。相比于强化学习在机器人上的使用,模仿学习方法避免了随机探索,更有可能被应用在实体机器人上。近年来模仿学习已经被应用在多种多样的机器人任务上:[1] [2]

[1] DeepMimic

[2] One-shot Imitation Learning
然而,让机器人能够同时模仿多种多样的技能是比较困难的。对于现有的多任务模仿学习算法来说,这既需要示教者提前同时提供所有任务的示教样本,又给多任务模仿学习算法带来了负担。而且,一旦学习结束,机器人的策略无法继续进行新任务的学习。在实际生活中,我们常常难以提前确定机器人所需要的所有任务,因而如何能够让机器人进行持续模仿学习是一个重要的研究问题。
持续学习
持续学习(Continual Learning,或者叫Lifelong Learning)旨在解决神经网络在面对不断到来的新任务时会发生的灾难性遗忘(Catastrophic Forgetting)的问题。常用的方法包括数据回放(Rehearsal)、分布回放(Deep Generative Replay)以及渐进扩增网络(Progressive Neuron Networks)等。其中,深度分布回放DGR方法是一种存储量少、效果不错的方法。该方法将过去任务的数据“记”在一个生成式的模型中,然后在新任务学习的时候将过去的数据重新生成出来并和新的任务数据混在一起训练,以此避免灾难性遗忘。DGR已经被广泛应用在图像分类的持续学习中。
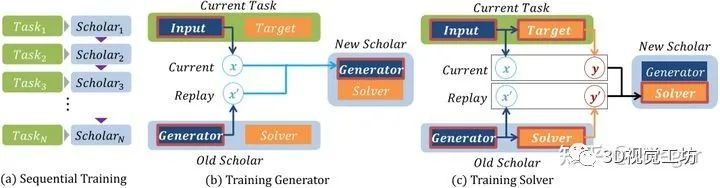
Deep Generative Replay方法
然而,在机器人模仿学习任务中,示教数据是一条一条的时序轨迹,直接应用DGR方法的话相当于要训练一个多任务的视频生成模型(Video Generation Model)。对于机器人示教数据来说,一个任务常常只提供几十、几百条轨迹,这对于生成高质量的视频来说是一个挑战。看来,直接应用DGR回放视频数据是不可行的。
方法
机器人模仿学习毕竟不是纯粹的视频数据。我们指出,每一帧状态数据对应有动作数据,这是大量视频生成任务中所不具备的。基于此,我们提出了结合使用状态、动作信息同时生成过往训练数据的思路。具体来说,为了减轻生成式模型的负担,我们舍弃了视频生成的思路,只将每条轨迹的第一帧进行生成,然后训练一个预测模型,根据当前帧和当前动作预测下一帧,以此根据回放的第一帧不断地迭代生成新的帧和对应的动作,以此极大地降低生成模型的复杂度:
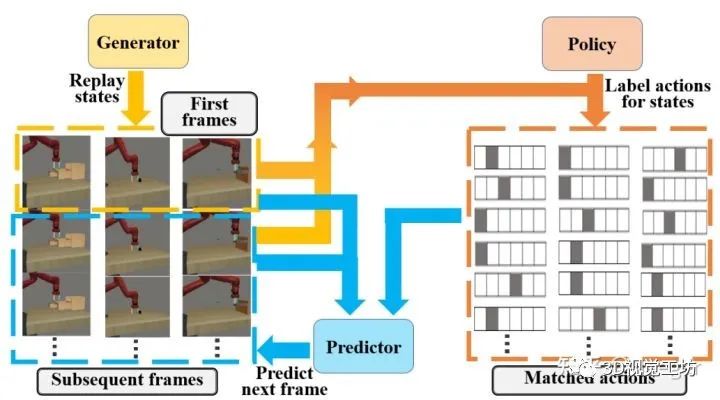
将生成模型的任务进行分解为首帧生成和视频预测
从理论上来说,我们的方法在DGR框架中添加了一个预测模块,于是首帧回放模块、策略模块和预测模块正好能够对应组成一条轨迹的似然函数:
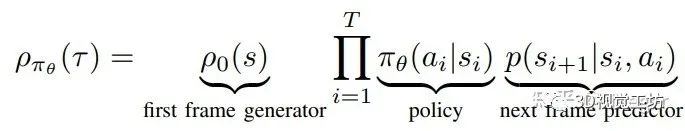
轨迹似然函数的分解
同时,基于Wasserstein距离,我们证明了我们的方法和DGR方法具有同样的保优性。
实验
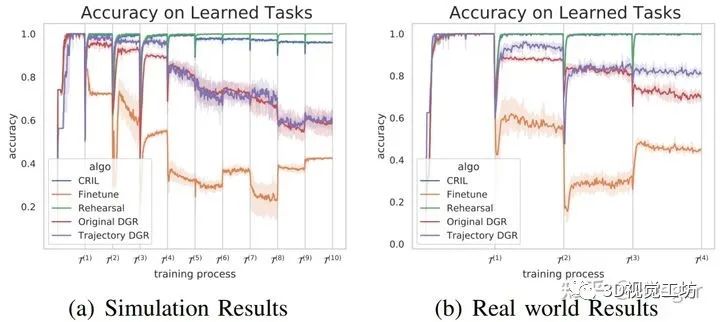
我们在仿真环境中(Meta-world)和实体环境中分别进行了持续模仿学习的实验。我们的方法只需要对每个任务采集少于100条轨迹的数据,便可在实体环境中达到4和任务的持续学习效果,在仿真环境中达到10个任务的持续学习效果。更多的细节可参见原文中的实验章节。
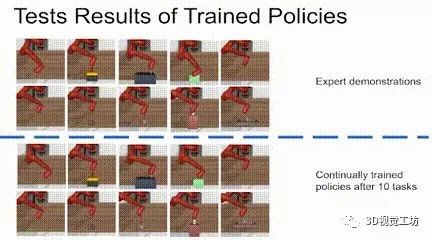 仿真实验结果
仿真实验结果
 实体实验结果
实体实验结果
对比直接使用DGR的方法和直接整条视频生成的方法,我们的方法拥有更慢的遗忘曲线:
和基线方法对比的遗忘曲线
参考文献:
1、Su, X., Jiang, Y., Guo, S. and Chen, F., 2020, November. Task Understanding from Confusing Multi-task Data. In International Conference on Machine Learning (pp. 9177-9186). PMLR.
2、Guo, S., Yan, Q., Su, X., Hu, X. and Chen, F., 2021. State-Temporal Compression in Reinforcement Learning with the Reward-Restricted Geodesic Metric. IEEE Transactions on Pattern Analysis and Machine Intelligence.
3、Zhang, T., Guo, S., Tan, T., Hu, X. and Chen, F., 2020. Generating Adjacency-Constrained Subgoals in Hierarchical Reinforcement Learning. Advances in Neural Information Processing Systems. (NeurIPS Spotlight)
4、Su, X., Guo, S., Tan, T. and Chen, F., 2019. Generative memory for lifelong learning. IEEE transactions on neural networks and learning systems, 31(6), pp.1884-1898.
5、Ren, Jinsheng, Shangqi Guo, and Feng Chen. 2021, Orientation-Preserving Rewards' Balancing in Reinforcement Learning. IEEE Transactions on Neural Networks and Learning Systems .
6、Gao, H., Yang, Z., Su, X., Tan, T. and Chen, F., 2020, Adaptability Preserving Domain Decomposition for Stabilizing Sim2Real Reinforcement Learning. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
7、Chongkai Gao, Haichuan Gao, Shangqi Guo, Tianren Zhang and Feng Chen. CRIL: Continual Robot Imitation Learning via Generative and Prediction Model. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









