






作者:马雪奇 | 来源: 深圳大学可视计算研究中心
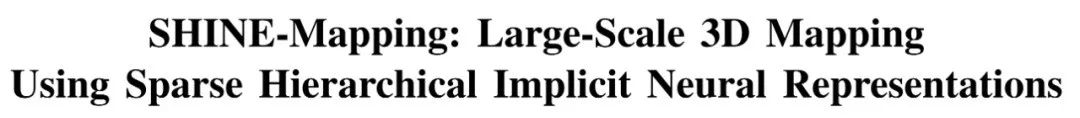

导读
本文是VCC马雪奇同学对论文 SHINE-Mapping: Large-Scale 3D Mapping Using Sparse Hierarchical Implicit Neural Representations[1] 的解读,该工作来自德国波恩大学摄影测量与机器人实验室,已被机器人领域的顶级会议ICRA 2023收录。
项目主页:
https://github.com/PRBonn/SHINE_mapping
该工作提出了一种基于隐式表达的大规模三维建图的方法,它利用分层八叉树的结构来存储可学习的局部特征,并通过共享的浅层MLP将局部特征转换为有符号距离场。相比于以往的工作,该方法能够以更小的资源消耗,重建出更准确、更完整的大规模场景。
注:本文图片与视频均来自原论文与其项目主页。

I
引言
对移动机器人而言,在大规模的室外场景中进行定位和导航是一项常见的任务。因此,一个精确的三维环境地图变得尤为重要。重建的三维场景地图除了要足够精确,还应该尽可能地减少内存消耗。而目前的建图方法往往采用空间网格来表示三维地图[2][3][4],这种方法很难同时满足精确建图和减少内存的要求。
最近,基于隐式神经网络的表示方法在精确重建网格的同时,还能保持低内存消耗的要求。不过,这类方法通常应用于RGB-D数据构建的三维场景[5][6][7],在LiDAR数据方面应用的不多。此外,这类方法只适用于小型场景,很难应用于大规模的室外场景中。
本次导读论文从Takikawa等人[8] 的工作中得到启发,通过构建稀疏的分层隐式神经网络表示,完成了对大规模场景的增量式重建。该方法利用八叉树的稀疏数据结构来增量式地存储学习到的局部特征,并基于一个浅层的MLP将学习到的局部特征转换为有符号距离场。除此之外,该工作还设计了一个二值交叉熵损失函数,能够高效地实现局部特征优化。并且,该论文采用正则化的方法对特征更新进行约束,有效地缓解了在大规模场景建图过程中遇到的灾难性遗忘问题。实验结果表明:
(1) 在密集点云采样区域,该方法的重建精度优于基于TSDF的方法[4][9] 以及基于体积渲染的隐式神经映射方法[7];
(2) 在稀疏点云采样区域,该方法的重建完整度优于非学习的方法[12];
(3) 相比于基于TSDF的方法,该方法重建的场景内存消耗更小。
II
技术贡献
本工作主要贡献如下:
提出了一种新的基于稀疏分层八叉树的大规模场景表示方法。该方法增量式地将学习到的局部特征向量存储在八叉树中,并通过一个浅层的神经网络将学习到的局部特征转换为有符号距离值;
设计了一种二值交叉损失函数,能够实现快速且鲁棒的局部特征值优化;
通过对特征进行正则化,有效避免了灾难性遗忘问题对大规模场景建图的影响。
III
方法介绍
SHINE-Mapping以激光雷达点云作为输入,利用稀疏分层八叉树以及全局共享的MLP解码器来隐式地表示连续空间中的有符号距离场。该方法以直接测量的点云作为监督,通过在线优化MLP解码器输出的有符号距离值来捕捉局部场景中的几何信息。最后,该方法利用Marching Cubes[10]将有符号距离场转换为显式的网格信息。
隐式神经地图表示
首先,SHINE-Mapping将三维空间中的局部特征存储在稀疏分层八叉树中,实现了隐式地图表示,有效地减少了建图过程中的内存开销。其次,该方法将八叉树中存储的多层局部特征进行求和,并送入到MLP中进行解码,从而得到三维空间中的有符号距离场。
此外,为了能够快速查找局部空间中的特征信息,SHINE-Mapping将八叉树中每一层特征信息存储在一个哈希表中,并通过独特的莫顿码,将多维数据映射到一维。这样的设计使得该方法能够轻松地扩展地图,而无需事先分配内存,从而有效地提升了建图速度。
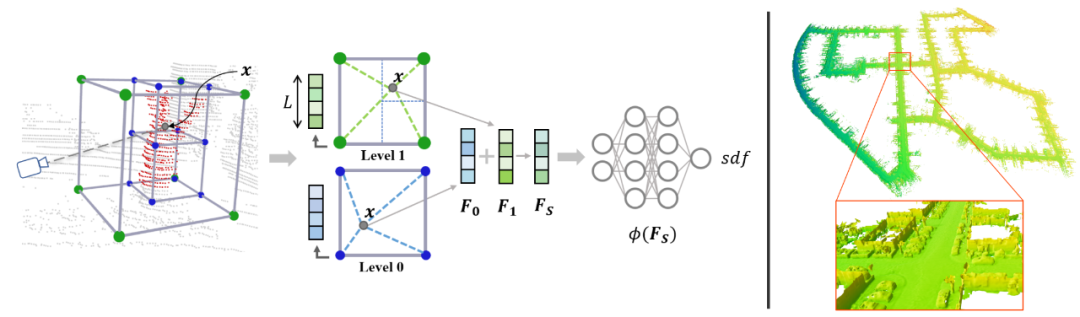
图1 SHINE-Mapping整体重建过程
图1为SHINE-Mapping重建隐式表示地图的整体过程。为了便于理解,上图中仅描述了两个层级的特征,绿色和蓝色。该方法的流程为:对于任意的查询点 首先从最底层(第0层)开始,对 的空间位置进行三线性插值,从而得到第0层的特征。然后以此类推,获得第1层的特征信息。接着,该方法通过对多层的特征信息进行求和,得到合并后的特征,并将合并后的特征送入到MLP中,从而获得 位置点的有符号距离值。由于整个过程是可微的,因此可以通过反向传播的方式对特征向量和MLP参数进行联合优化。
训练与损失函数
因为LiDAR能够提供准确的三维空间测距结果,因此该方法直接以LiDAR作为真值,以二值交叉熵 作为损失函数来对特征向量和MLP参数进行监督训练。除此之外,由于该方法的网络输出是有符号距离值,为了能够得到准确的输出结果,该方法在损失函数中添加了一个Eikonal项[11]:
其中 为网络模型的输出, 为网络模型的参数, 为网络模型的输入。
得到的损失函数如下: 其中, 为超参数,其表示 的权重。
增量式重建
在增量式重建工程中,由于每次重建只聚焦于当前的局部区域,忽略了之前重建区域的信息,往往会导致最终的全局重建性能下降。为了避免这种问题对重建结果的影响SHINE-Mapping在损失函数中添加了正则化项 用于约束参数更新: 其中, 为权重,表示先前训练数据的Loss对于参数变化的敏感性。 为当前的参数值, 为之前数据训练收敛之后的参数值。增量式重建的损失函数如下: 其中, 为超参数,表示 的权重。
IV
部分结果展示
接下来我们首先以虚拟场景数据集MaiCity dataset为例,展示SHINE-Mapping与之前方法 Voxblox、VDBFusion、Puma[12] 以及添加可微渲染 (Differentiable Rendering: DR) 的SHINE-Mapping的重建结果对比。第一行展示的是重建后的网格结果,其中,黑色线框部分为街道两旁的“树”;第二行展示的是重建结果的误差图,从蓝色到红色的颜色图表示从-5cm到5cm的有符号重建误差。
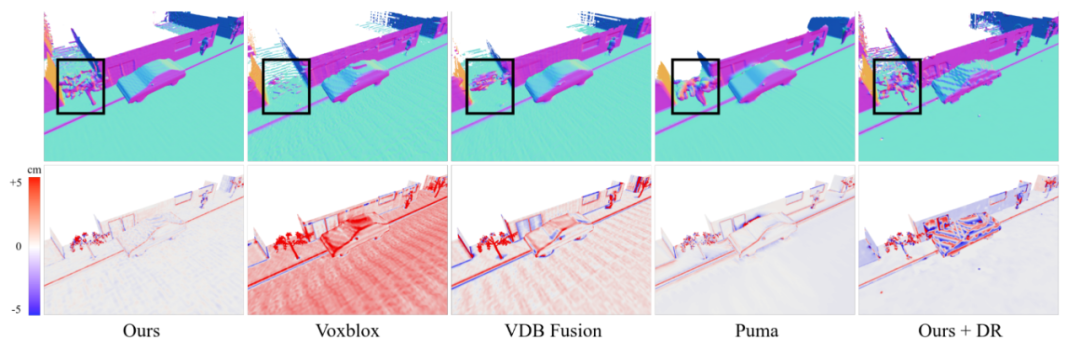
图2 在MaiCity数据集上,不同方法的重建结果对比
表1为不同方法在MaiCity数据集上的重建质量评价结果。可以看出,SHINE-Mapping与先前的大规模室外场景建图方法相比,在完整性误差,准确性误差、Chamfer-L1误差、完整度、F-score上均表现 SOTA。
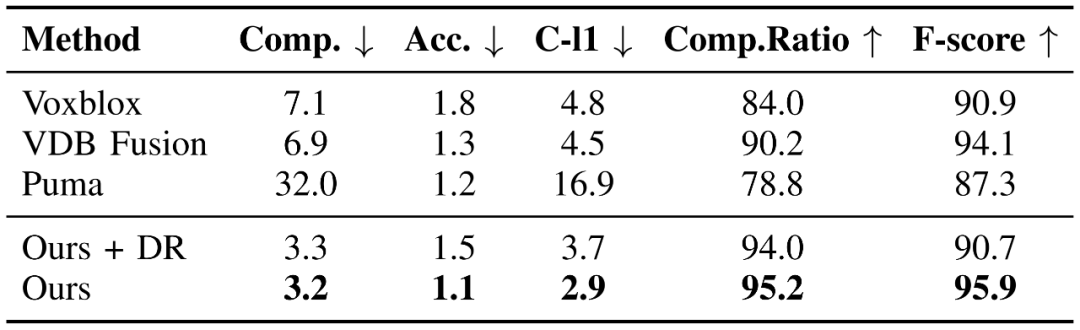
表1 不同方法在MaiCity数据集上的重建质量对比

图3 在MaiCity数据集上,SHINE-Mapping增量式重建过程
接下来是SHINE-Mapping在真实场景数据集Newer College dataset上的重建结果。第一行展示的是不同方法重建的Newer College网格结果,黑色线框部分为“树”;第二行展示的是重建结果的误差图,从蓝色到红色的颜色图表示从-50cm到50cm的有符号重建误差。

图4 在Newer College数据集上,不同方法的重建结果对比
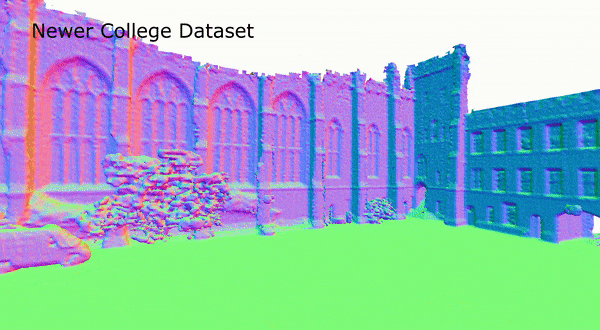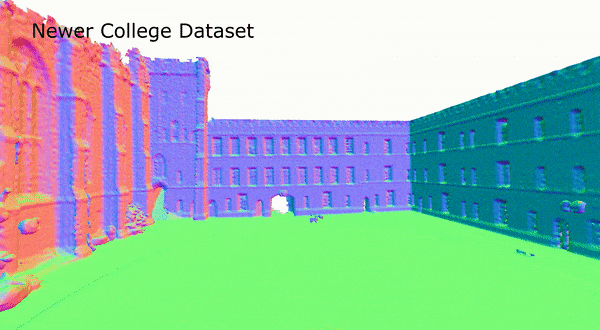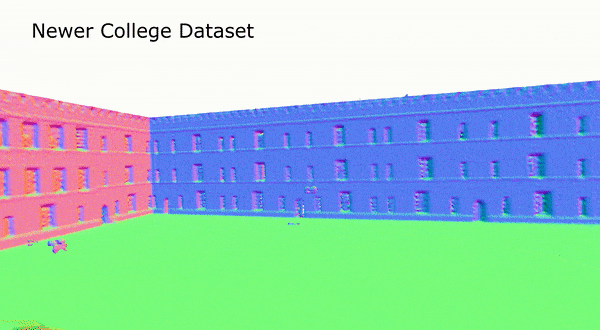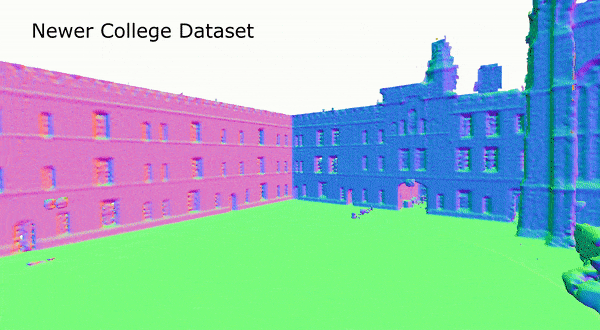
图5 在Newer College数据集上,SHINE-Mapping的重建结果
表2为不同方法在Newer College dataset上的重建质量评价结果。可以看到,在真实场景数据集上,相比于其他方法,SHINE-Mapping的重建质量也是最好的。
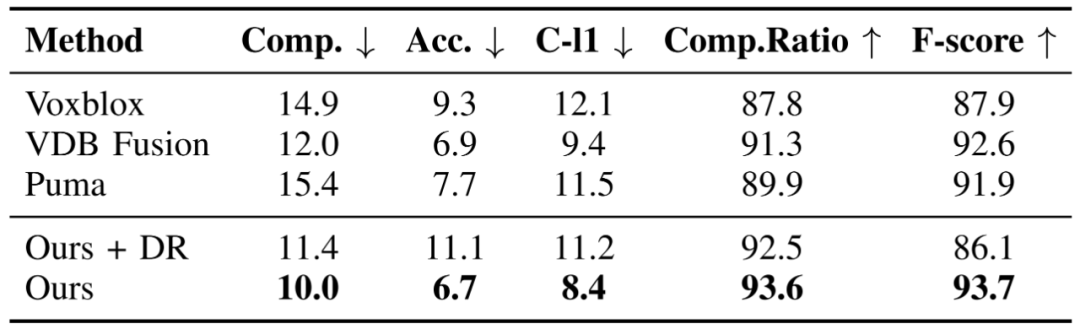
表2 不同方法在Newer College数据集上的重建质量对比
下图描述了在MaiCity dataset与Newer College dataset两个数据集实验中,内存消耗与建图质量之间的关系,地图的分辨率从100cm到10cm。从对比结果可以看出,SHINE-Mapping方法可以使用更小的内存资源来重建出质量更高的室外地图。
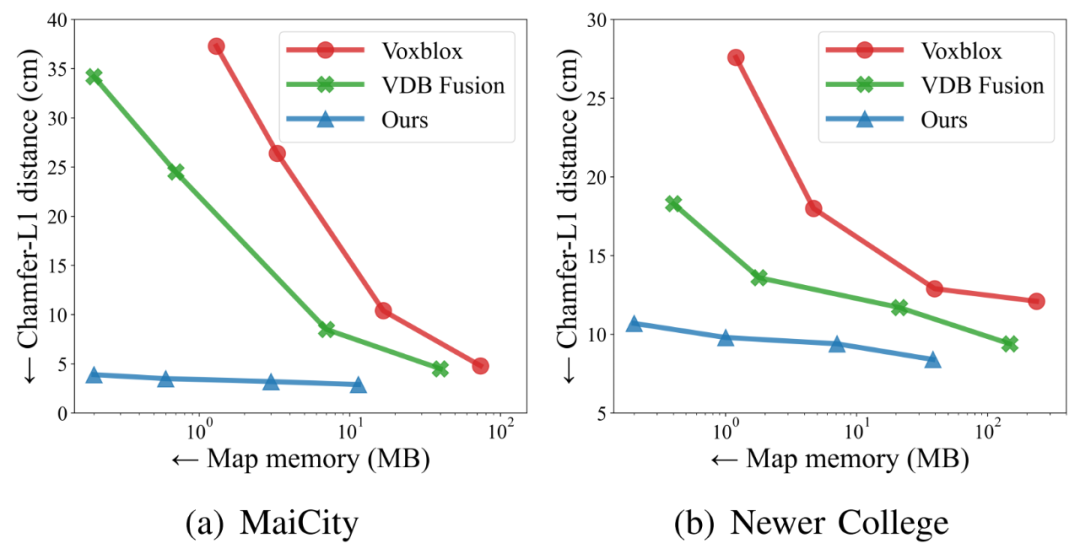
图6 不同方法在内存效率与重建误差上的表现
下图为SHINE-Mapping在KITTI dataset上的重建过程。可以看到,即使是大规模的实际复杂街道场景,该方法依然可以精确地重建出道路的真实样貌。

图7 SHINE-Mapping在KITTI数据集上的重建过程
V
总结与展望
本次导读的论文提出了一种基于LiDAR的大规模三维场景建图方法。与基于TSDF的方法不同,SHINE-Mapping方法使用基于八叉树的隐式表示法,将学习到的隐式特征存储在哈希表中,大大缩短了处理时间。其次,该方法将学习到的特征通过一个MLP转换为有符号距离值,并通过Marching Cubes进行显式化网格重建。除此之外,该方法通过对损失函数进行调整,并添加相应的正则化,避免了增量式重建过程中遇到的灾难性遗忘问题。实验结果表明,该方法能够以较小的内存重建出更为准确和完整的三维地图。
VI
思考与讨论
Q: SHINE-Mapping方法将局部特征信息存放入八叉树中时,使用了其中的几层呢?又是如何实现快速查找对应的特征信息的呢?
A: 如下图所示,假设八叉树为11层,SHINE-Mapping方法将最低的三层作为局部特征存放层,即第0,1,2层(分别对应图中的红色、绿色、蓝色方格)。为了能够加速建图速度,SHINE-Mapping将八叉树中第 0,1,2层的局部特征信息存储在哈希表中,并且每一层对应一个哈希表。当需要查询指定点的局部特征时,使用哈希表可以很快得到相应的特征信息。
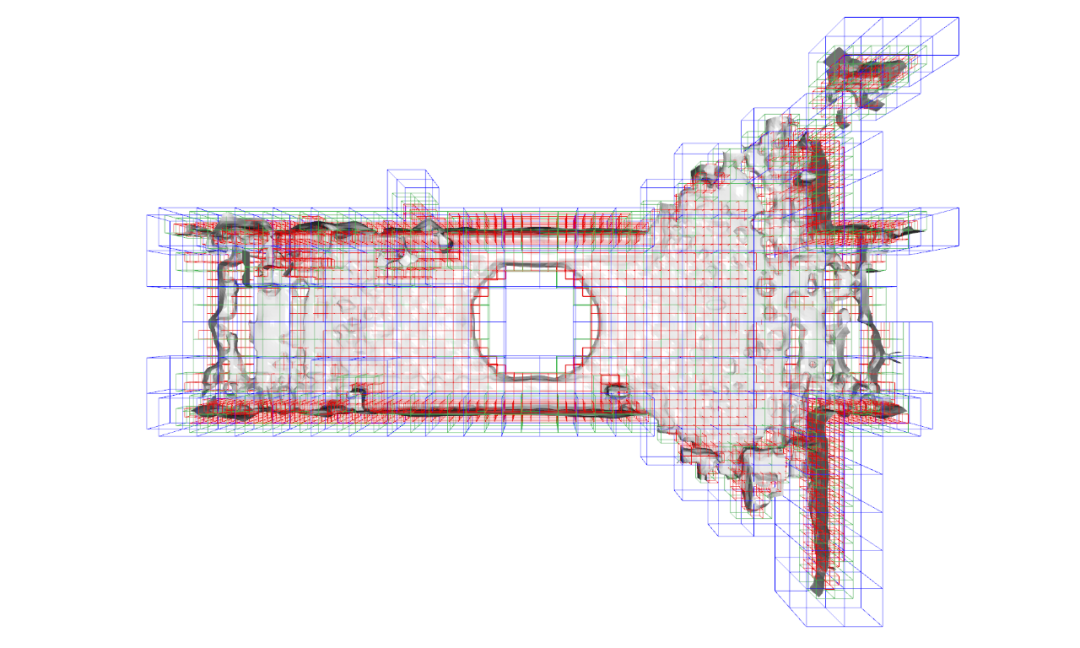
图8 SHINE-Mapping对空间进行网格划分,并得到局部特征信息
Q: 在增量式重建过程中,是否可以使用预训练的MLP作为解码器来得到相应的有符号距离值?
A: 是的,虽然本文提出的方法可以在训练过程中联合优化八叉树中的局部特征信息以及MLP中的参数,但是在实际增量式重建过程中,作者采用的是预训练的MLP来得到对应位置的有符号距离值,一方面这样可以加快重建的速度,另外一方面,在实验过程中,使用预训练的MLP可以得到更好的重建效果。
以下是开放性问题,欢迎读者朋友留言讨论:
Q: SHINE-Mapping在增量式重建的过程中,实际上是增量式地更新空间中的局部特征信息,并在更新完整个地图之后,使用MLP将局部特征信息转换为有符号距离值,然后使用Marching Cubes来显式的构建网格。因此,如果想在建图的过程中,实时地查看重建的网格信息,则需要不断地调用MLP和Marching Cubes,这将会导致实时的计算效率非常低。那么应该如何改进这一方法,或者是否可以使用其他的网格构建方法,使得在快速建图过程中,能够实时地查看重建效果呢?
-- End--
导 读 | 马雪奇
审 核 | 黄惠
编 辑 | 申金
参考文献
[1] Xingguang Zhong, Yue Pan, Jens Behley, Cyrill Stachniss. SHINE-Mapping: Large-scale 3d mapping using sparse hierarchical implicit neural representations. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2023.
[2] Armin Hornung, Kai M. Wurm, Maren Bennewitz, Cyrill Stachniss, Wolfram Burgard. OctoMap: An efficient probabilistic 3d mapping framework based on octrees. Autonomous Robots, 34:189–206, 2013.
[3] Yue Pan, Yves Kompis, Luca Bartolomei, Ruben Mascaro, Cyrill Stachniss, Margarita Chli. Voxfield: Non-projective signed distance fields for online planning and 3d reconstruction. In Proc. of the IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS), 2022.
[4] Ignacio Vizzo, Tiziano Guadagnino, Jens Behley, Cyrill Stachniss. Vdbfusion: Flexible and efficient tsdf integration of range sensor data. Sensors, 22(3):1296, 2022.
[5] Dejan Azinović, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, Justus Thies. Neural rgb-d surface reconstruction. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2022.
[6] Edgar Sucar, Shikun Liu, Joseph Ortiz, Andrew J. Davison. imap: Implicit mapping and positioning in real-time. In Proc. of the IEEE/CVF Intl. Conf. on Computer Vision (ICCV), 2021.
[7] Zihan Zhu, Songyou Peng, Viktor Larsson, Weiwei Xu, Hujun Bao, Zhaopeng Cui, Martin R. Oswald, Marc Pollefeys. Nice-slam: Neural implicit scalable encoding for slam. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2022.
[8] Towaki Takikawa, Joey Litalien, Kangxue Yin, Karsten Kreis, Charles Loop, Derek Nowrouzezahrai, Alec Jacobson, Morgan McGuire, Sanja Fidler. Neural geometric level of detail: Real-time rendering with implicit 3d shapes. In Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2021.
[9] Helen Oleynikova, Zachary Taylor, Marius Fehr, Roland Siegwart, Juan Nieto. Voxblox: Incremental 3d euclidean signed distance fields for on-board mav planning. In Proc. of the IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS), 2017.
[10] William E. Lorensen, Harvey E. Cline. Marching Cubes: A high resolution 3d surface construction algorithm. In Proc. of the Intl. Conf. on Computer Graphics and Interactive Techniques (SIGGRAPH), pages 163–169, 1987.
[11] Joseph Ortiz, Alexander Clegg, Jing Dong, Edgar Sucar, David Novotny, Michael Zollhoefer, Mustafa Mukadam. isdf: Real-time neural signed distance fields for robot perception. In Proc. of Robotics: Science and Systems (RSS), 2022.
[12] Ignacio Vizzo, Xieyuanli Chen, Nived Chebrolu, Jens Behley, Cyrill Stachniss. Poisson surface reconstruction for LiDAR odometry and mapping. In Proc. of the IEEE Intl. Conf. on Robotics & Automation (ICRA), 2021.
—END—
高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。[三维重建方向]NeRF、colmap、OpenMVS等。除了这些,还有求职、硬件选型、视觉产品落地等交流群。大家可以添加小助理微信: cv3d007,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」
学习3D视觉核心技术,扫描查看,3天内无条件退款
第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
基础课程:
[1]面向三维视觉算法的C++重要模块精讲:从零基础入门到进阶
工业3D视觉方向课程:
SLAM方向课程:
[1]如何高效学习基于LeGo-LOAM框架的激光SLAM?
[1]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[2](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[3]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[4]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
视觉三维重建
[1]彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进)
自动驾驶方向课程:

















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









