






作者:张继耀 | 来源:机器之心
类别级 6D 物体位姿估计是一个基础且重要的问题,在机器人、虚拟现实和增强现实等领域应用广泛。本文中,来自北京大学的研究者提出了一种类别级 6D 物体位姿估计新范式,取得了新的 SOTA 结果,论文已被机器学习领域顶会 NeurIPS 2023 接收。
6D 物体位姿估计作为计算机视觉领域的一个重要任务,在机器人、虚拟现实和增强现实等领域有众多应用。尽管实例级别的物体位姿估计已经取得了显著进展,但它需要事先了解物体的特性,因此无法轻松适用于新的物体,这限制了其实际应用。为了解决这一问题,近年来,越来越多的研究工作集中在类别级别的物体位姿估计上。类别级别的位姿估计要求算法不依赖于物体的 CAD 模型,能够直接应用到与训练数据中相同类别的新物体。
目前,主流的类别级别 6D 物体位姿估计方法可以分为两大类:一是直接回归的端到端方法,二是基于物体类别先验的两阶段方法。然而,这些方法都将该问题建模为回归任务,因此在处理对称物体和部分可见物体时,需要特殊的设计来应对多解问题。
为了克服这些挑战,北京大学的研究团队提出了一种全新的类别级 6D 物体位姿估计范式,将该问题重新定义为条件分布建模问题,从而实现了最新的最优性能。他们还将这一方法成功应用于机器人操作任务,如在视频中展示的倒水等任务。

论文地址:https://arxiv.org/abs/2306.10531
类别级 6D 物体姿态估计中的多解问题
在类别级 6D 物体姿态估计中,多解问题指的是在同一观测条件下,可能存在多个合理的位姿估计。这种情况主要源于两个方面,如图 1 所示:对称物体和部分观测。对于对称物体,例如球形或圆柱形的物体,在不同方向上的观测可能会完全相同,因此从理论上讲,它们有无限多个可能的位姿真值。同时,单一视角无法获取到完整的物体观测,例如马克杯,在没有观察到杯柄的情况下,也存在无限多个可能的位姿真值。

图 1. 多解问题的来源:对称物体和部分观测
方法介绍
那么如何应对上述多解问题呢?作者把该问题看作条件分布建模问题,提出了一种名为 GenPose 的方法,利用扩散模型来估计物体位姿的条件分布。该方法首先使用基于分数的扩散模型生成物体位姿的候选项。然后通过两步对候选项进行聚合:首先,通过似然估计筛选掉异常值,接着通过平均池化对剩余候选位姿进行聚合。为了避免在估计似然时需要繁琐的积分计算,研究作者还引入了一种基于能量的扩散模型的训练方法,以实现端到端的似然估计。

图 2. GenPose 框架结构
基于分数的扩散模型用于物体姿态候选的生成
这一步骤旨在解决多解问题,那么如何建模物体位姿的条件概率分布呢?作者采用了基于分数的扩散模型,利用 VE SDE(Variational Eulerian Stochastic Differential Equation)构建了一个连续的扩散过程。在模型的训练过程中,其目标是估计扰动条件姿态分布的分数函数,并最终通过 Probability Flow ODE(Ordinary Differential Equation)从条件分布中采样物体姿态的候选项。
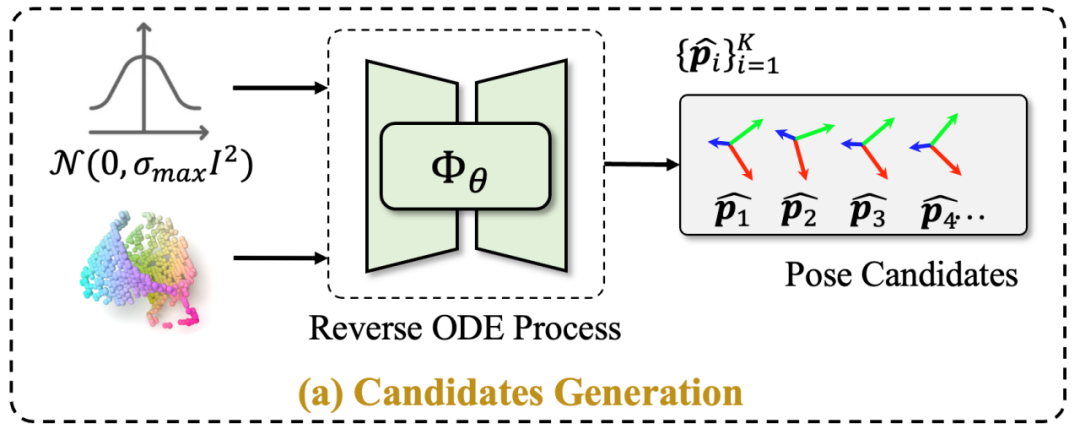
图3. 基于分数的扩散模型生成物体姿态候选
基于能量的扩散模型用于物体姿态候选的聚合
从训练好的条件分布可以采样出无限个物体位姿候选,如果从候选中得到一个最终的物体位姿呢?最直接的方式是随机采样,但是这种方法无法保证预测的稳定性。是否可以通过平均池化来聚合候选项呢?然而这种聚合方式未考虑候选的质量,容易受到离群值的影响。作者认为可以通过似然估计的方式把候选的质量作为聚合的参考。具体来说,根据似然估计结果对物体姿态候选进行排序,过滤掉似然估计较低离群候选后对剩余候选进行平均池化,就可以得到聚合后的姿态估计结果。但是,扩散模型进行似然估计需要繁琐的积分计算,这严重影响了推理速度,及其限制其实际应用。为了解决这个问题,作者提出训练一个基于能量的扩散模型,直接用于进行端到端的似然估计,实现候选的快速聚合。
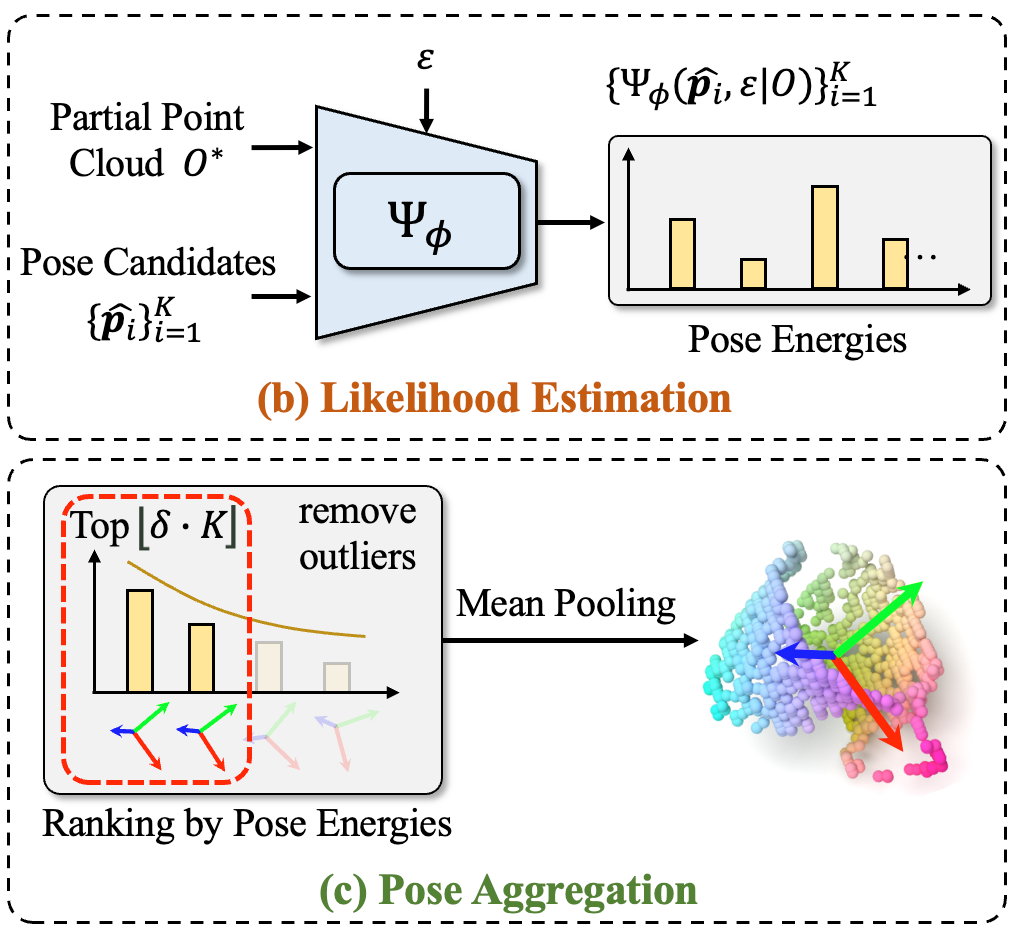
图4. 基于能量的扩散模型用于似然估计与物体姿态候选聚合
实验与结果
作者在 REAL275 数据集上对 GenPose 性能进行了验证,可以看出 GenPose 在各项指标上都大幅优于之前的方法,即使是与使用更多模态信息的方法进行对比,GenPose 依然有很大的领先优势,表 1 展示了作者提出的生成式物体姿态估计范式的优势。图 5 是可视化的结果。
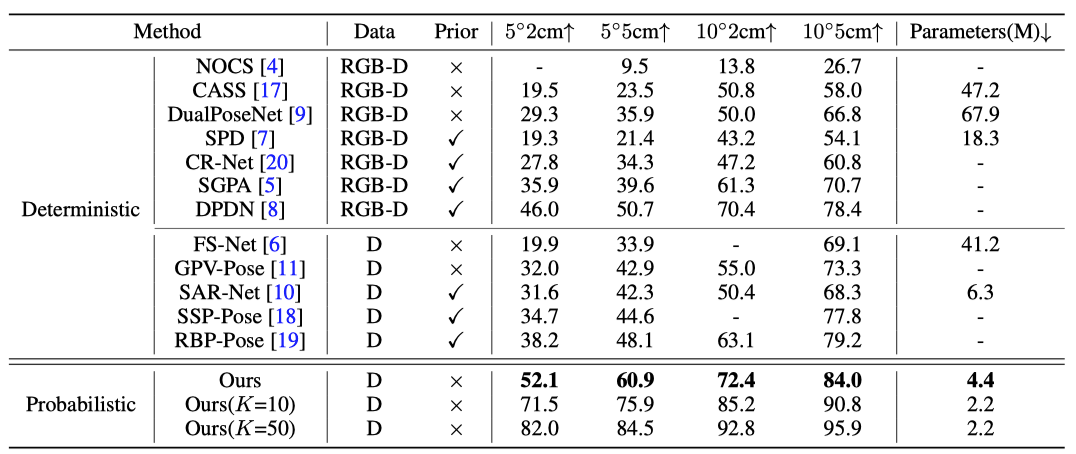
表 1. 与其他方法的对比

图 5. 不同方法的预测可视化效果
作者还研究了使用不同的聚合方法(随机采样,随机排序后聚合、基于能量排序后聚合、GT 排序后聚合)的影响。可以看出使用能量模型进行排序明显优于随机抽样方法。可以看出作者提出的基于能量的扩散模型对物体姿态候选进行聚合的方法明显由于随机采样的方法和随机排序后平均池化的方法。
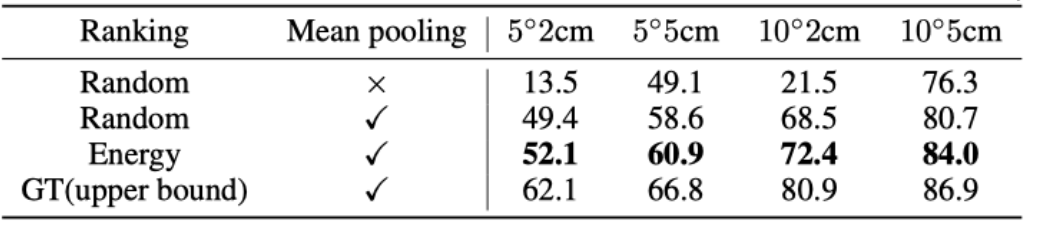
表 2. 不同聚合方式的对比
为了更好地分析能量模型的影响,作者进一步研究了估计的位姿误差与预测的能量之间的相关性。如图 4 所示,预测的位姿误差和能量之间存在一般的负相关关系。能量模型在识别误差较大的姿态时表现较好,而在识别误差较小的姿态时表现较差,这解释了为什么预测的能量被用来去除离群点,而非直接选出能量最大的候选。
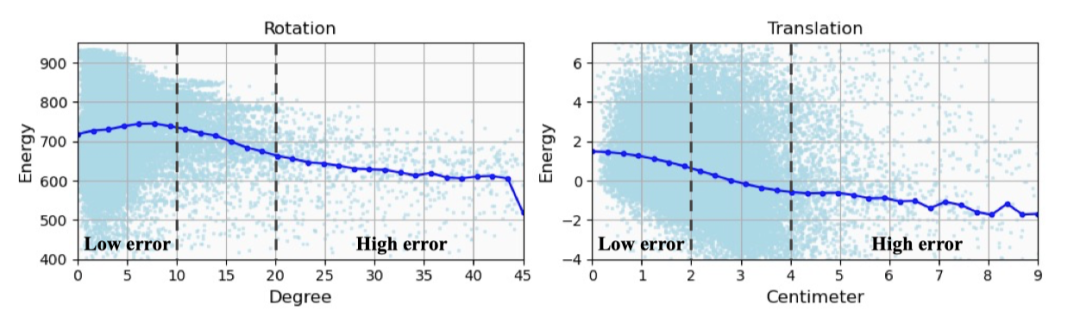
图6. 能量与预测误差相关性分析
作者还展示了该方法跨类别泛化的能力,该方法不依赖类别先验,在跨类别的泛化上的表现也显著优于之前的方法。

表 3. 跨类别泛化效果。‘/’ 左边表示训练数据集包含测试类时的性能,‘/’ 右边表示把训练时把测试的类别移除时候的性能。
同时,由于扩散模型的闭环生成过程,文章中的单帧姿态估计框架还可以直接用于 6D 物体姿态跟踪任务,没有任何特殊的设计,该方法在多项指标中优于最先进的 6D 物体姿态跟踪方法,结果如表 4 所示。
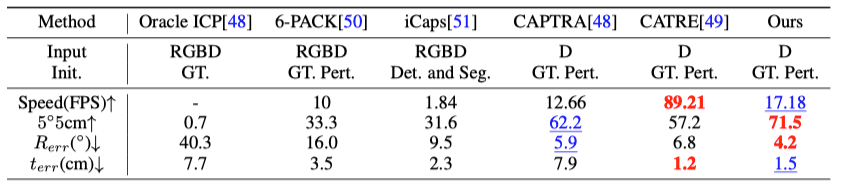
表 4. 类别级 6D 物体姿态追踪性能对比
总结与展望
这项工作提出了一个类别级 6D 物体位姿估计新范式,训练过程无需针对对称物体和部分观测带来的多解问题做任何特殊设计,取得了新的 SOTA 性能。未来的工作会利用扩散模型的最新进展来加速推理过程,并考虑结合强化学习来实现主动式 6D 物体位姿估计。
研究团队介绍:
本次研究的通讯作者董豪为北京大学的助理教授、博导、博雅青年学者、智源学者,其创立并领导北大超平面实验室(Hyperplane Lab)。
论文共同一作张继耀、吴铭东为北京大学博士生,导师为董豪老师,详见个人主页。
https://jiyao06.github.io/
https://aaronanima.github.io/
下载1
在公众号「3D视觉工坊」后台,回复「3d001」,即可获取工业3D视觉(结构光、缺陷检测、三维点云)、SLAM(视觉/激光SLAM)、自动驾驶、三维重建、事件相机、无人机等近千余篇最新顶会论文。
下载2
在公众号「3D视觉工坊」后台,回复「3d002」,即可获取巴塞罗那自治大学3D视觉课件、慕尼黑工业大学3D视觉和视觉导航精品课件。
下载3
在公众号「3D视觉工坊」后台,回复「3d003」,即可获取相机标定、结构光、三维重建、激光-视觉-IMU-GPS多模态融合SLAM、LOAM、ORB-SLAM3,深度估计、模型部署、3D目标检测等学习课件。注:非完整版。
高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶、三维重建、无人机方向,细分群包括:
[工业3D视觉]相机标定、立体匹配、三维点云、结构光(面/线/散斑)、机械臂抓取(2D/3D)、2D缺陷检测、3D缺陷检测、6D位姿估计、相位偏折术、Halcon、光场重建、摄影测量、阵列相机、偏振三维测量、光度立体视觉、激光雷达、综合群等。
[SLAM]视觉SLAM、激光SLAM、ORB-SLAM、Vins-Fusion、LOAM/LeGo-LOAM、cartographer、VIO、语义SLAM、滤波算法、多传感器融合、多传感器标定、MSCKF、动态SLAM、MOT SLAM、NeRF SLAM、FAST-LIO、LVI-SAM、LIO-SAM、事件相机/GPS/RTK/UWB/IMU/码盘/TOF(iToF/dToF)/激光雷达/气压计/毫米波雷达/RGB-D相机/超声波等、机器人导航、综合群等。
[自动驾驶]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪、综合群等。
[三维重建]NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
[无人机]四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 3D视觉从入门到精通系统课程
目前3D视觉工坊平台针对各个方向的知识点,打造了多门从理论到实战课程,包括:
论文写作课程:三维科研基础入门课程:C++、Linux、相机标定、ROS2、dToF工业3D视觉课程:面结构光、线结构光、散斑结构光、相位偏折术、机械臂抓取、三维点云(PCL和Open3D)、缺陷检测SLAM课程:LeGo-LOAM、LOAM、LVI-SAM(激光-视觉-IMU-GPS融合SLAM)、Vins-Fusion、ORB-SLAM3、室内/室外激光SLAM等机器人路径规划与控制课程:机器人规控入门与实践三维重建课程:comlap、MVSNet等自动驾驶课程:多传感器标定、视觉Transformer、单目深度估计、3D目标检测、模型部署等。
注:工坊现面向平台所有读者招募主讲老师,奖励丰厚,具体详情可以可以参考:3D视觉主讲老师招募

第三步 加入知识星球,问题及时得到解答
「3D视觉从入门到精通」知识星球,依托于微信公众号「3D视觉工坊」、「计算机视觉工坊」、「3DCV」平台,星球内除了包含3D视觉独家秘制视频课程(近20门,包括三维重建、三维点云、手眼标定、相机标定、3D目标检测、深度估计、ORB-SLAM3、Vins-Fusion、激光-视觉-IMU-GPS融合、机械臂抓取等)、3D视觉项目对接、3D视觉学习路线、最新论文&代码分享、入门书籍推荐、源码汇总、最新行业模组分享、编程基础&作业、求职招聘&面经&面试题等,更有各类大厂的算法工程人员进行技术指导。目前星球铁杆粉丝已近6000+,让我们一起探索更其妙的3D视觉技术、为祖国的创新发展贡献自己的一份力。知识星球入口:3D视觉从入门到精通

















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









