






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:具身智能之心
添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

尽管室外可使用 全球导航卫星系统(GNSS)(如 GPS)定位导航,但 GNSS 不适用于室内定位,因为 GPS 信号无法穿透建筑物和障碍物进入地下环境,所以在封闭的室内结构中需采用其他定位技术。室内导航有巨大的应用价值,比如能够指引人们在陌生的建筑物内快速到达目的地,在发生紧急情况时,也可引导人们快速疏散等。
然而,室内导航的研究目前存在多种瓶颈,比如常用的强化学习(RL)和模仿学习(IL)在处理长时间序列任务时,对记忆能力提出了新要求。首先,强化学习(RL)需要大量奖励塑造和辅助损失。在复杂的视觉世界中,智能体的行为决策需要通过奖励机制来引导其学习到期望的行为。例如,在一个机器人导航任务中,当机器人靠近目标时给予正奖励,靠近障碍物时给予负奖励。长周期任务意味着智能体需要在较长的时间序列中做出一系列决策才能完成任务。例如在一个模拟的家庭环境中,让智能体从一个房间出发,经过多个房间,找到并拿起一个特定物品,再返回指定位置,这个过程可能涉及到大量的步骤和决策。RL 算法在每一步决策时都需要根据当前的状态和奖励反馈来更新策略,在长周期任务中,由于状态空间巨大且决策的序列很长,导致学习过程非常缓慢。而且在这个过程中,智能体可能会陷入局部最优解,无法找到全局最优的策略,从而导致效果不佳。另外,模仿学习(IL)是通过让智能体学习专家的行为轨迹来实现的。如果要收集人类的行为轨迹作为专家示范,需要耗费大量的人力、物力和时间。
室内环境的复杂性也对具身智能基础模型的上下文理解能力和跨模态对齐能力提出新要求。除此以外,室内环境具有多变性,比如人们可能会移动室内的物体,导致智能体刚刚学习到的环境再次发生变化,也使室内导航决策更加困难。
本期分享的一些室内导航的文章,有些文章旨在优化室内导航的基础模型的强化学习和模仿学习过程,有的文章希望提高基础模型的上下文理解能力和跨模态对齐能力,也有些文章建立了模拟室内环境的生成模型,用于室内导航训练,解决室内导航数据集不足的问题。接下来一起看看吧~
SPOC:在模拟中模仿最短路径可实现现实世界中的有效导航和操作
强化学习(RL)和模仿学习(IL)是训练现代具身智能体的常用方法,但都存在一些问题。RL 需要大量的奖励塑造和辅助损失,对于长周期任务往往太慢且效果不佳;IL 虽然有效,但收集大规模的人类轨迹成本极高。
这篇文章提出了SPOC 智能体。SPOC 是一个端到端的架构,它以文本指令和视觉观察作为输入,在每个时间步预测一个动作。它基于 Transformer 架构,Transformer 的优势在于能够处理长序列数据,并且能够通过自注意力机制有效地捕捉数据中的长程依赖关系。在 SPOC 中,这种特性有助于处理连续的视觉观察和动作序列,使其能够更好地学习到导航和操作任务中的复杂模式。
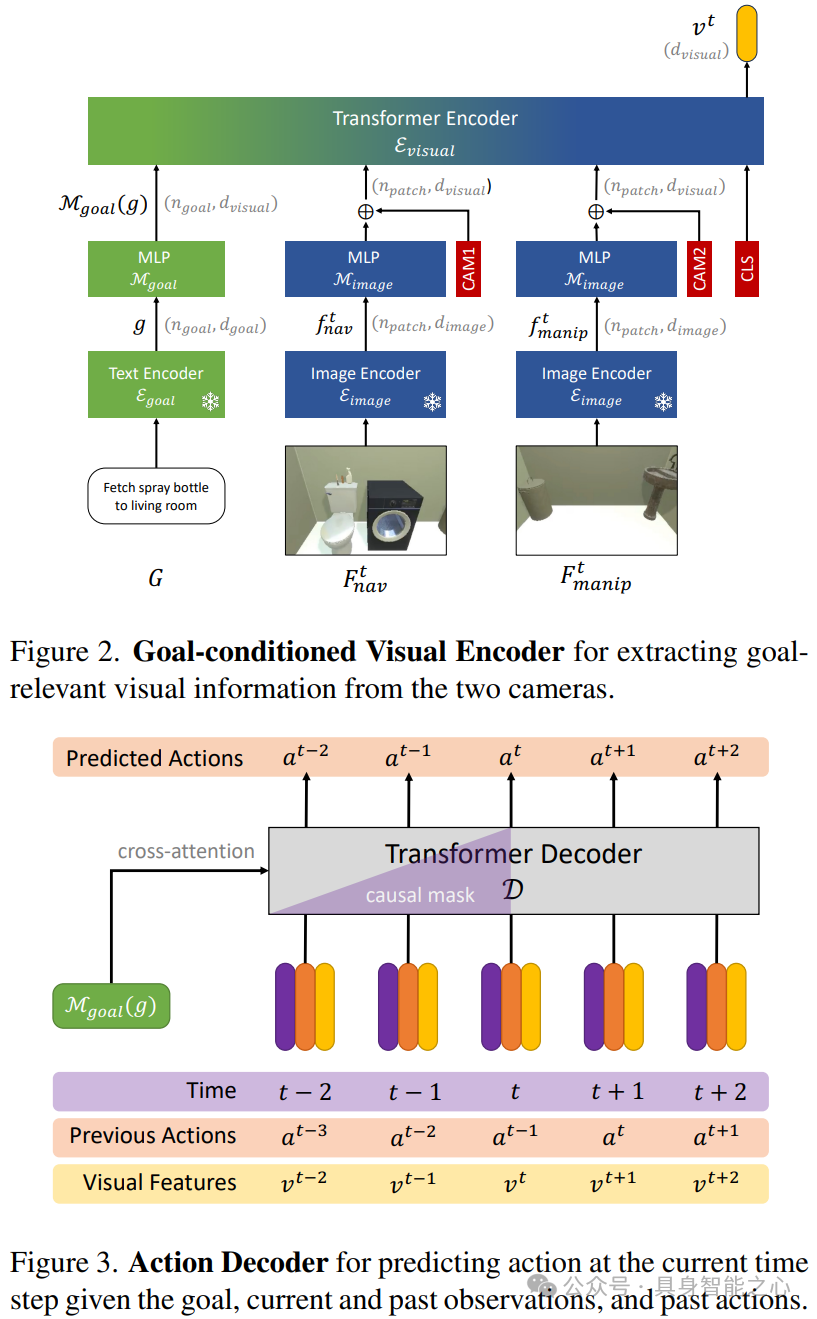
首先使用文本目标编码器处理开放词汇的语言指令,使用指令条件视觉编码器对每个时间步的视觉输入进行编码:文本目标编码器使用预训练的文本编码器(如 T5 和 SIGLIP 文本编码器)将目标指令映射为一系列上下文相关的标记表示。指令条件视觉编码器需要整合来自两个垂直方向的 RGB 摄像头的视觉输入(一个用于导航方向,一个用于机械臂操作方向),使用预训练的图像编码器(如 SIGLIP - VIT - B/16)将每个摄像头的 RGB 帧编码为一系列上下文相关的补丁嵌入。然后,将这些嵌入映射到 Transformer 输入维度,并添加可学习的摄像头类型嵌入以区分来自两个摄像头的特征。
因果 Transformer 动作解码器负责预测当前时间步的动作。它以之前和当前的视觉表示序列作为输入,并结合正弦时间位置编码和学习到的之前时间步的动作嵌入。在预测过程中,它通过交叉注意力机制关注目标编码,并在每个时间步,将 Transformer 解码器的输出嵌入通过线性和 softmax 层来预测该时间步的动作分布。在训练过程中,使用因果掩码确保解码器仅关注当前和过去的输入来预测当前动作,而在推理过程中,模型根据预测的动作分布进行采样,并将采样得到的动作作为下一个时间步的输入。
在训练过程中,SPOC 通过模仿模拟环境中的最短路径规划器来学习有效的行为策略。这些最短路径规划器能够在复杂的多房间环境中进行导航和操作,例如能够识别和与物体交互、在杂乱环境中导航以及适应各种障碍物。它们通过计算最短路径(如通过导航网格计算到目标物体的最短路径)来指导智能体的行动,SPOC 学习模仿这些规划器的行为,从而获得在模拟环境中有效导航和操作的能力,并能够迁移到现实世界中。

PoliFormer:使用 Transformer 扩展基于策略的强化学习造就卓越的导航器
强化学习(RL)和模仿学习(IL)被广泛用于训练具身机器人完成室内导航任务。IL 在 Object Goal Navigation(ObjectNav)任务上表现出潜力,但仍有不足。RL 具有探索状态空间的优势,但在应用于更复杂的导航问题时面临挑战,如训练不稳定和训练时间过长。
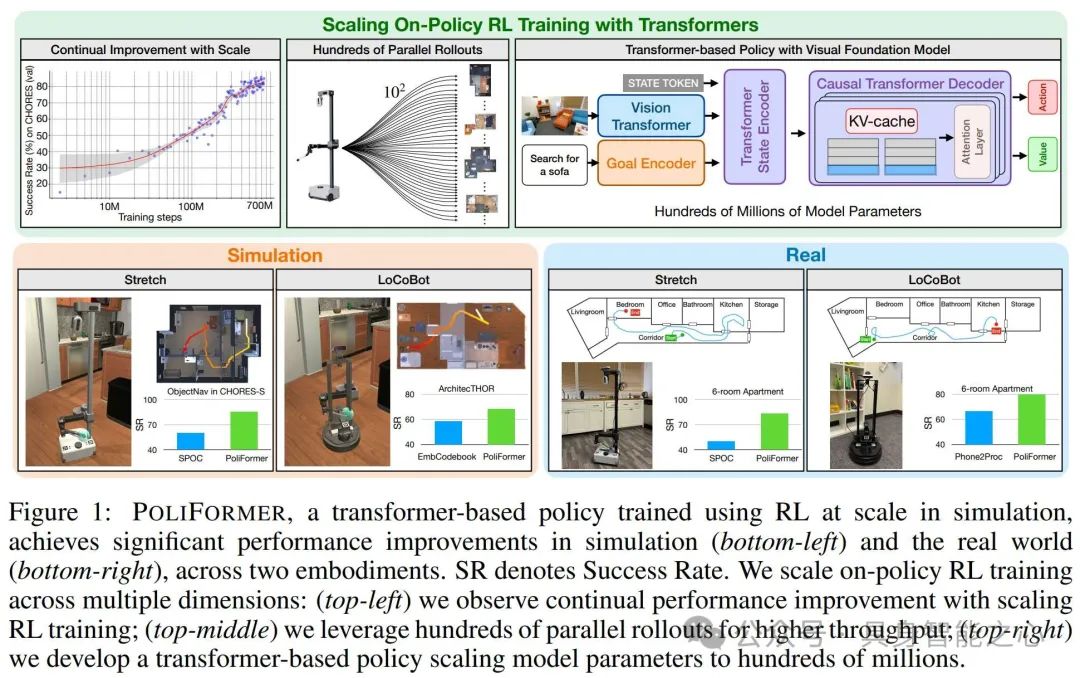
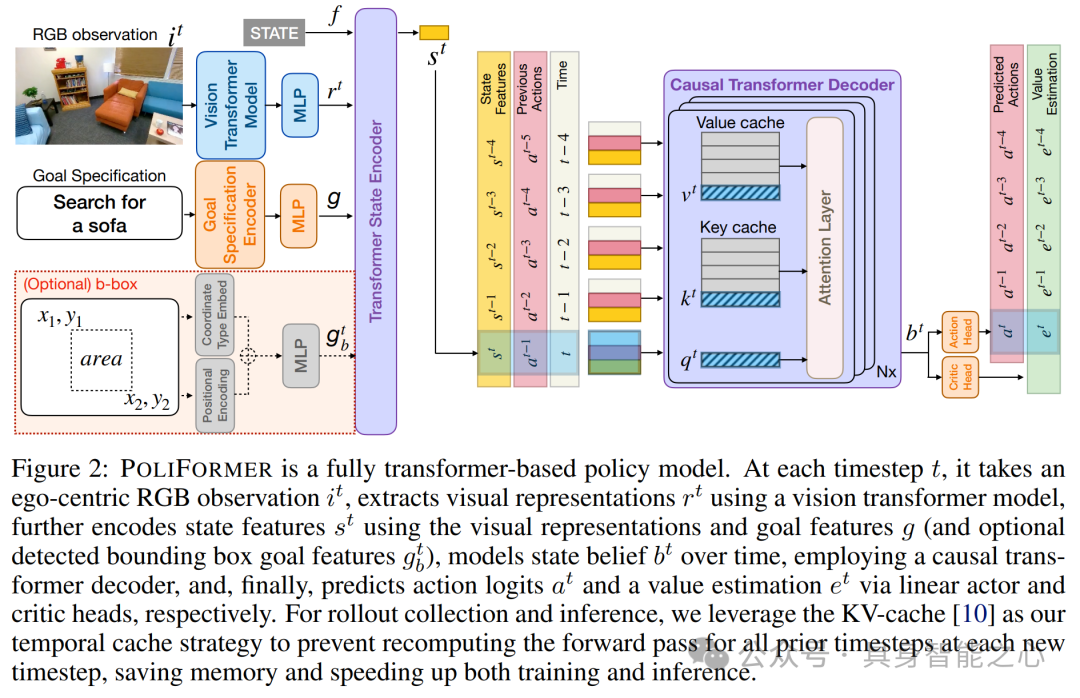
文章提出PoliFormer 架构,它基于 SPOC 架构改进而来。其整体架构在每个时间步以自我中心的 RGB 观测作为输入,经一系列模块处理后预测动作 logits 和价值估计。该架构包含几个关键组件:
视觉 Transformer 模型以特定的 RGB 观测为输入,产生按块表示的输出,经重塑和投影后作为 Transformer State Encoder 的输入维度,且在模拟训练时保持冻结。
目标编码器针对不同机器人有不同编码方式,LoCoBot 使用独热嵌入层编码目标物体类别,Stretch RE - 1 使用 FLAN - T5 small 模型编码自然语言目标并投影到所需维度;还可通过边界框指定目标,此时目标编码器会用特定方式处理并投影到所需维度。
Transformer State Encoder 将每个时间步的状态总结为一个向量,其输入包括视觉表示、目标特征和一个 STATE 标记的嵌入,经连接和非因果 Transformer 编码器处理后得到状态特征向量。
因果 Transformer 解码器(Causal Transformer Decoder)用于随时间进行显式的记忆建模,能够实现长周期(如回溯式的详尽探索)和短周期(如绕过物体导航)的规划。它使用状态特征序列构建状态信念,通过 KV - cache 技术克服标准因果 Transformer 计算成本高的问题,只需用最新状态特征进行前馈计算,提高了计算效率。
文章还成功提高了模拟速度、优化了加载时间。由于 on - policy RL 要求智能体与环境实时交互,发现 Stretch RE - 1 智能体在 AI2 - THOR 中的连续物理模拟对于大规模高效训练来说太慢。为克服此问题,采用一种带有碰撞检查的瞬移方法来离散地近似智能体的连续运动。例如,在移动智能体时,沿着期望的运动方向使用一个胶囊碰撞体进行物理投射,如果没有碰撞到任何物体,则将智能体瞬移到目标位置;否则,让 AI2 - THOR 像往常一样模拟连续运动。通过这些近似方法,模拟速度提高了约 40%。
PANDA:基于提示的上下文和室内感知视觉和语言导航预训练
本文提出了一种基于提示的上下文和室内感知预训练(PANDA)框架,用于解决视觉 - 语言导航(VLN)任务中的问题,在 R2R 和 REVERIE 数据集上的实验结果显示了其相对于现有先进方法的优越性。
在 VLN 任务中,智能体需要根据自然语言指令在环境中进行导航。智能体不仅需要理解每个单独动作的含义,还需要理解这些动作之间的上下文关系。并且,VLN 任务涉及到视觉和语言两种模态的信息。智能体需要将自然语言指令中的语义信息与视觉环境中的实际场景进行对齐。而且这种对齐需要按照指令的顺序进行。
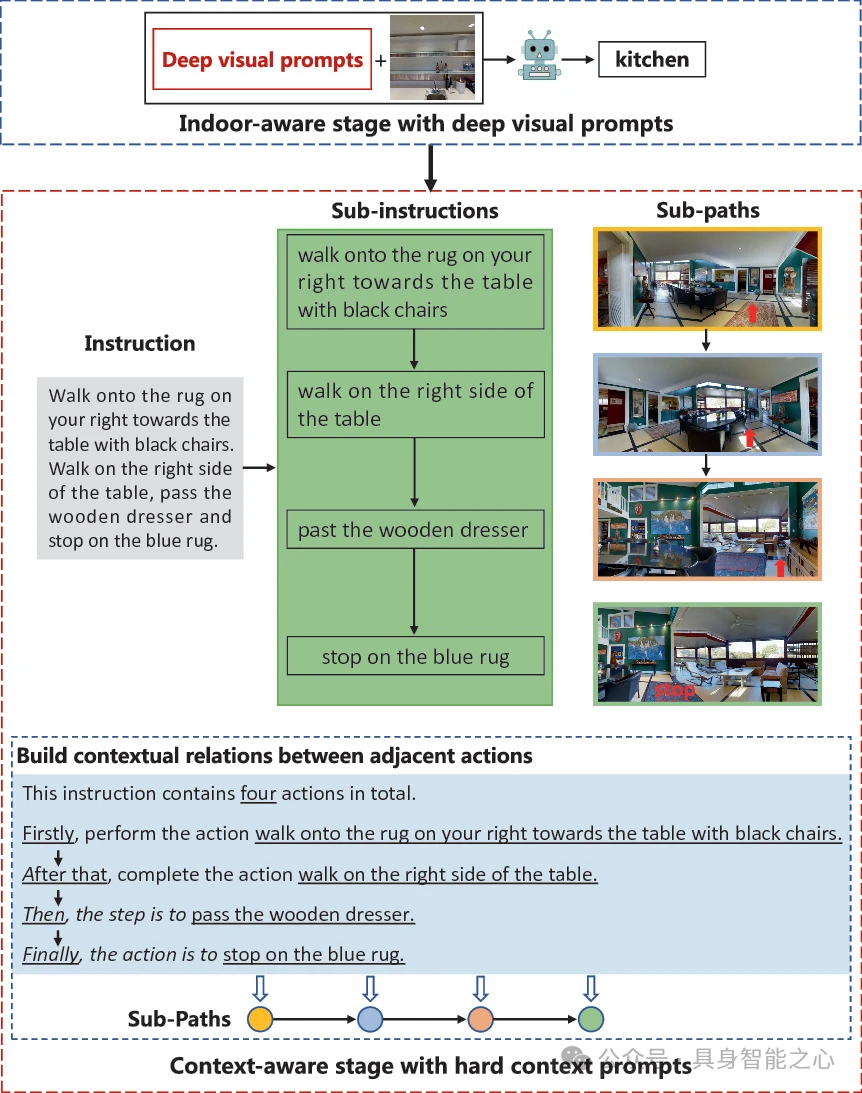
PANDA 框架主要包含两个阶段:室内感知阶段和上下文感知阶段。通过这两个阶段对预训练模型进行调整,使其更好地适应 VLN 任务中的室内场景,并能够理解路径上动作的上下文关系以及进行跨模态顺序对齐。
室内感知阶段旨在为预训练模型增加对室内环境的归纳偏差,使 VLN 智能体能够更高效地适应室内场景。采用一种高效的调整范式从室内数据集中学习深度视觉提示。具体来说,可能是利用室内数据集的特定信息(例如室内物体的布局、室内常见物体的特征等)来调整模型的参数,使得模型能够更好地识别和理解室内场景相关的特征。
上下文感知阶段是为了让智能体能够更好地理解路径上动作的上下文关系,并实现跨模态顺序对齐。通过捕捉指令中的序列级语义,进一步调整预训练模型。具体方法为设计一组硬上下文提示,这些提示可能是基于对 VLN 任务中指令特点的分析而构建的。例如,对于包含多个动作的导航指令,提示可能会强调动作之间的先后顺序、动作与环境特征之间的关联等信息。通过对比学习的方式,利用这些提示来调整预训练模型的参数,使得模型能够更好地理解指令中的上下文关系,并在视觉环境中按照正确的顺序执行相应的动作。
文章在 R2R 和 REVERIE 数据集上的实验结果显示了其相对于现有先进方法的优越性。
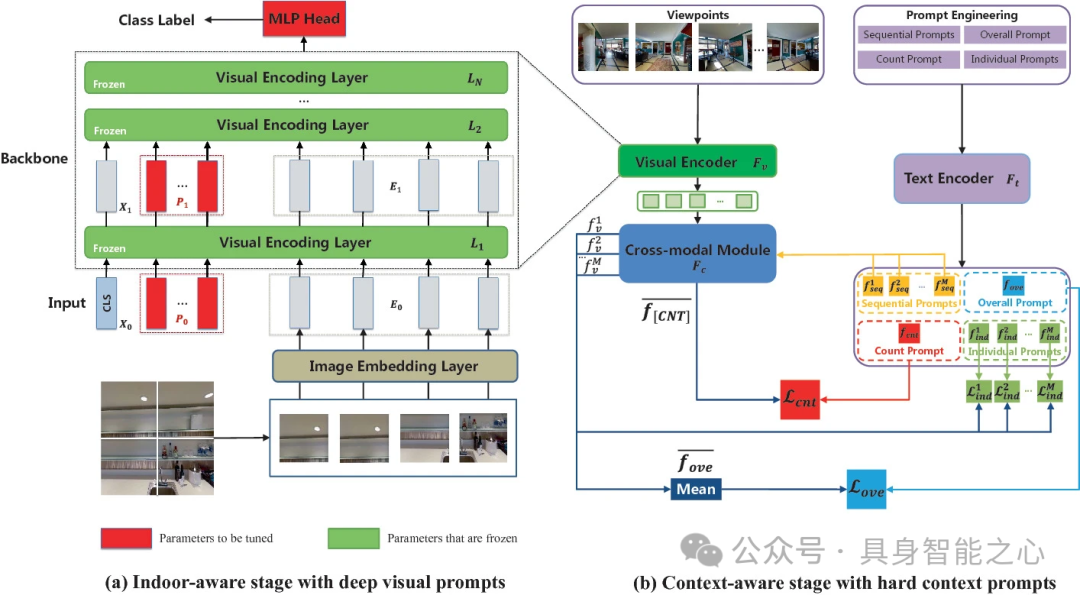
基于历史感知跨模态特征融合的室内环境视觉与语言导航
视觉 - 语言导航(VLN)是一项具有挑战性的任务,传统方法存在感知信息利用不充分、特定领域训练数据稀缺以及图像和语言输入多样等问题,导致性能欠佳。本文提出了一种基于历史感知跨模态特征融合的视觉 - 语言导航(VLN)模型,通过融合历史状态信息、引入regretful model和数据增强方法,提高了导航成功率,减少了动作冗余,并增强了模型的泛化能力,在 R2R 和 R4R 基准测试中取得了较好的效果。
VLN 任务的输入信息包括全景数据和语言指令。视觉特征通过预训练的 ResNet - 152 模型提取。语言指令的嵌入采用 Transformer 结构,并结合层归一化。并且,文章提出的跨模态注意力模型由两个单模态编码器(视觉和语言)和一个多模态编码器组成,基于多层 Transformer。通过注意力计算对齐视觉和语言模态,得到动作输出概率和当前状态。
文章提出了regretful model,它使用基于 LSTM 的序列到序列框架,将跨模态特征融合后的语言和视觉特征与前一时刻的动作输出级联。模型融合语言和视觉的历史状态特征作为输入,能更准确地判断导航完成进度和下一步执行动作。还使用进度监视器强制语言注意力权重与导航进度对齐,并引入前向和后向嵌入,根据完成进度的差异确定智能体的前进或后退动作。
针对 R2R 数据集的局限性,采用两种数据增强方法。一是用 Airbert 的 BnB 数据集进行大规模域内 VLN 预训练,二是采用说话者数据增强方法,通过两个模型(I 和 II)生成新的数据对,最后用 VLN 数据集和合成数据训练模型,以获得良好的泛化能力。
文章提出的新跨模态融合方法在标准测试场景中有效,通过生成 VLN 数据和采用数据增强技术解决了数据有限的问题,提高了模型在未知环境中的泛化能力。

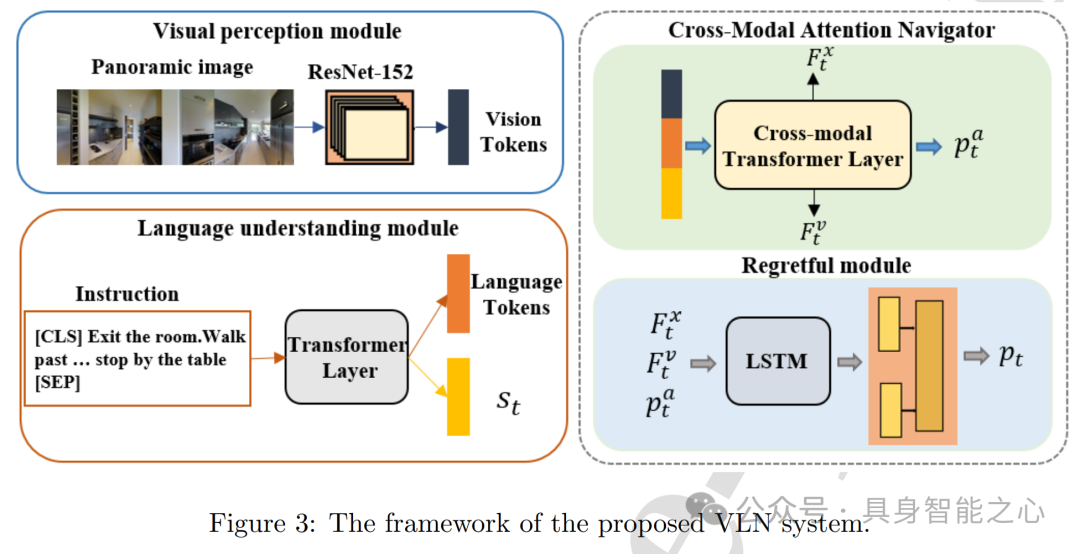
Pathdreamer:一种用于室内导航的世界模型
本文提出了 Pathdreamer,一种用于室内导航的视觉世界模型。该模型可以根据之前的视觉观测,为未访问过的视点生成合理的高分辨率 360° 视觉观测(包括 RGB、语义分割和深度),并在 Vision - and - Language Navigation(VLN)下游任务中展现出了潜力。
Pathdreamer 模型是一个分层两阶段模型,输入为室内场景的先前观测序列(包括 RGB 图像、语义分割图像和深度图像)以及对应的相机位姿序列,目标是为未来的相机位姿轨迹生成 RGB、语义分割和深度图像。模型使用一个潜在噪声张量来捕捉关于下一个观测的随机信息。
结构生成器(Structure Generator)是一个随机编码器 - 解码器网络,用于生成多样、合理的分割和深度图像。首先将先前的分割和深度图像转换为 3D 点云并重新投影以提供上下文,然后将语义指导图像和深度指导图像的组合作为编码器输入,引入潜在空间噪声张量,最终输出分割图像和深度图像。
图像生成器(Image Generator)是一个基于 GAN 的图像到图像转换模型,将结构生成器的语义和深度预测转换为真实的 RGB 图像。模型架构基于 SPADE 块,插入两个 SPADE 归一化层,使用部分卷积处理 RGB 指导图像的稀疏性,由 7 个 Multi - SPADE 块和一个卷积块组成。
在 VLN 任务中评估 Pathdreamer,使用基线 VLN 智能体生成未来轨迹,用指令 - 轨迹兼容性模型对轨迹排序,未来步骤的 RGB 观测来自不同来源。结果表明使用真实视觉观测可显著提高性能,Pathdreamer 的视觉观测可缩小与真实观测的差距约一半,说明 Pathdreamer 可作为视觉世界模型提高下游任务性能。

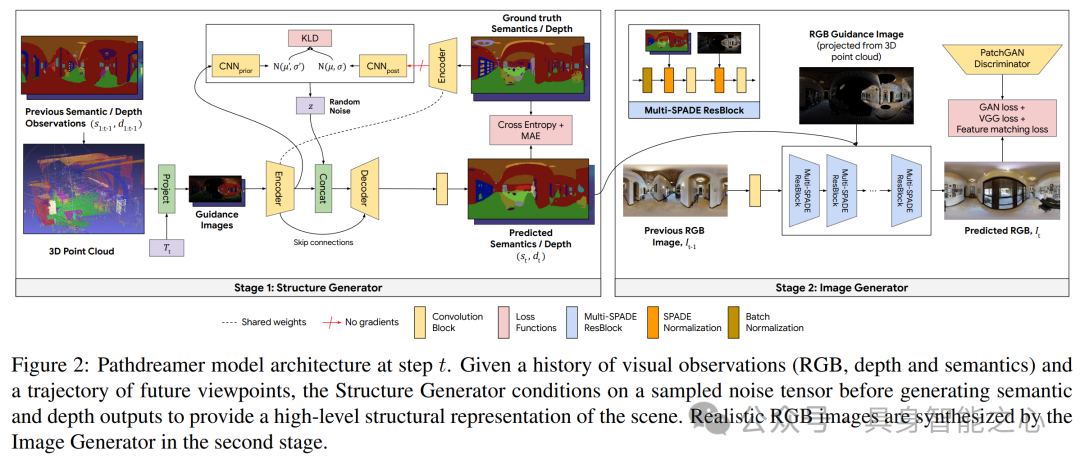
通过生成未来视图图像语义改进视觉 - 语言导航
视觉 - 语言导航(VLN)任务中,智能体通常基于预定义的候选动作进行导航,而人类在导航时会根据自然语言指令和周围环境对未来场景有所预期。先前的研究虽有探索生成未来场景,但对利用生成的未来观察中的语义信息的潜力仍未充分挖掘。
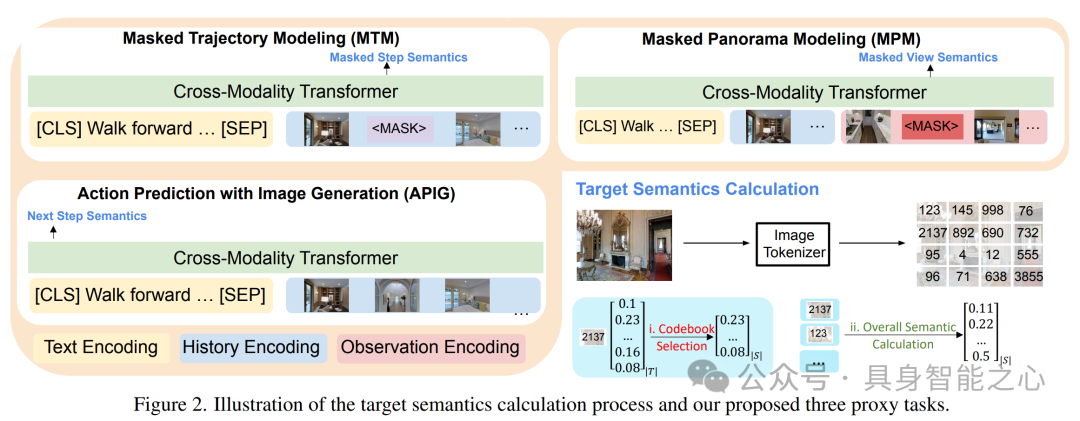
本文提出了 VLN - SIG 方法,通过在预训练阶段设计三个代理任务以及在微调阶段使用辅助损失,使智能体能够生成未来导航视图的语义信息,从而提高视觉 - 语言导航(VLN)任务的性能。
预训练中,文章提出了三种有效预测整体图像语义生成概率的方法,包括均值补丁概率、采样补丁概率和加权补丁概率(含块加权补丁概率),以解决直接预测所有补丁语义导致的计算不可行及学习效果不佳的问题。
对于视觉标记码本,提出静态码本选择和动态码本选择两种方法,学习优化视觉标记词汇的子集,使智能体聚焦于频繁出现和学习困难的标记。
提出三个代理任务帮助智能体学习生成图像语义:Masked Trajectory Modeling(MTM)随机掩盖导航轨迹中的部分步骤,恢复被掩盖的视图;Masked Panorama Modeling(MPM)随机掩盖全景视图中的部分视图,预测被掩盖的视图;Action Prediction with Image Generation(APIG)基于语言指令和导航历史生成下一步视图的语义,并挑选最接近生成图像的候选动作。
采用模仿学习和强化学习的混合方式对导航任务进行微调,并将 APIG 作为辅助任务进一步训练智能体。通过预提取图像的均值补丁概率和目标视觉标记,针对不同的语义表示方法优化相应的损失函数。
参考文献
SPOC: Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World, https://arxiv.org/abs/2312.02976
PoliFormer: Scaling On - Policy RL with Transformers Results in Masterful Navigators, https://arxiv.org/abs/2406.20083
PANDA: Prompt - Based Context - and Indoor - Aware Pretraining for Vision and Language Navigation, https://link.springer.com/chapter/10.1007/978-3-031-53305-1_15
Vision-and-language navigation based on history-aware cross-modal feature fusion in indoor environment, https://www.sciencedirect.com/science/article/pii/S0950705124012449
Pathdreamer: A World Model for Indoor Navigation, https://openaccess.thecvf.com/content/ICCV2021/papers/Koh_Pathdreamer_A_World_Model_for_Indoor_Navigation_ICCV_2021_paper.pdf
Improving Vision-and-Language Navigation by Generating Future-View Image Semantics, https://openaccess.thecvf.com/content/CVPR2023/papers/Li_Improving_Vision-and-Language_Navigation_by_Generating_Future-View_Image_Semantics_CVPR_2023_paper.pdf
这里给大家推荐一门我们最新的课程《国内首个面向具身智能方向的理论与实战课程》:






课程亮点
本课程从学术研究和实际应用两方面,带你从零入门具身智能的原理学习、论文阅读、代码梳理等内容。
课程由具身智能领域的资深专家主讲,他们先后担任研究所、国企、大厂具身智能负责人,拥有丰富的理论知识和实践经验。
课程答疑
本课程答疑主要在本课程对应的鹅圈子中答疑,学员学习过程中,有任何问题,可以随时在鹅圈子中提问。



















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









