






有趣的大模型中RAG噪声的作用分析
大模型(LLMs)在多个任务上表现出色,但存在依赖过时知识、幻觉等问题。RAG作为一种提高LLM性能的方法,通过在推理过程中引入外部信息来缓解这些限制。
Figure 1 展示了一个来自 NoiserBench 的示例,它阐释了不同类型的 RAG 噪声对大型语言模型(LLM)的影响。这个示例通过一个具体的问题和答案的情境来说明有益噪声和有害噪声对模型性能的不同作用:

- 有害噪声(Counterfactual Noise):最初,模型受到反事实噪声的误导。反事实噪声是指与事实相反的陈述,例如错误的信息或者过时的知识。在这个例子中,模型由于接触到了错误的信息,被引导至错误的答案。
- 有益噪声的引入:在引入有益噪声之后,模型能够成功区分正确和错误的信息。有益噪声是指那些实际上可以增强模型性能的噪声类型,如语义噪声、数据类型噪声和非法句子噪声。这些噪声类型有助于模型更好地识别和利用正确的信息,从而提高答案的准确性。
- 正确答案的产生:在这个例子中,模型最终产生了准确的答案 ‘D’。这说明在有益噪声的帮助下,模型能够克服最初由有害噪声引起的误导,正确地识别出正确的答案。
这个示例强调了噪声在 RAG 系统中的双重作用:一方面,有害噪声可能会损害模型的性能,导致错误的答案;另一方面,有益噪声可以帮助模型提高其处理和回答问题的能力。研究者通过这种对比展示了在实际应用中,如何通过理解和利用不同类型的噪声来优化模型的性能。
最近的工作 《Pandora’s Box or Aladdin’s Lamp: A Comprehensive Analysis Revealing the Role of RAG Noise in Large Language Models》(https://arxiv.org/pdf/2408.13533),该工作定义了七种不同类型的噪声,并建立了一个包含多个数据集和推理任务的噪声RAG基准测试框架。
具体来看2个点:
1、噪声类型的分类
在噪声定义与分类上,作者从语言学角度定义了七种不同的噪声类型,并将它们分为两类:对LLM有益的噪声(有益噪声)和对LLM有害的噪声(有害噪声)。
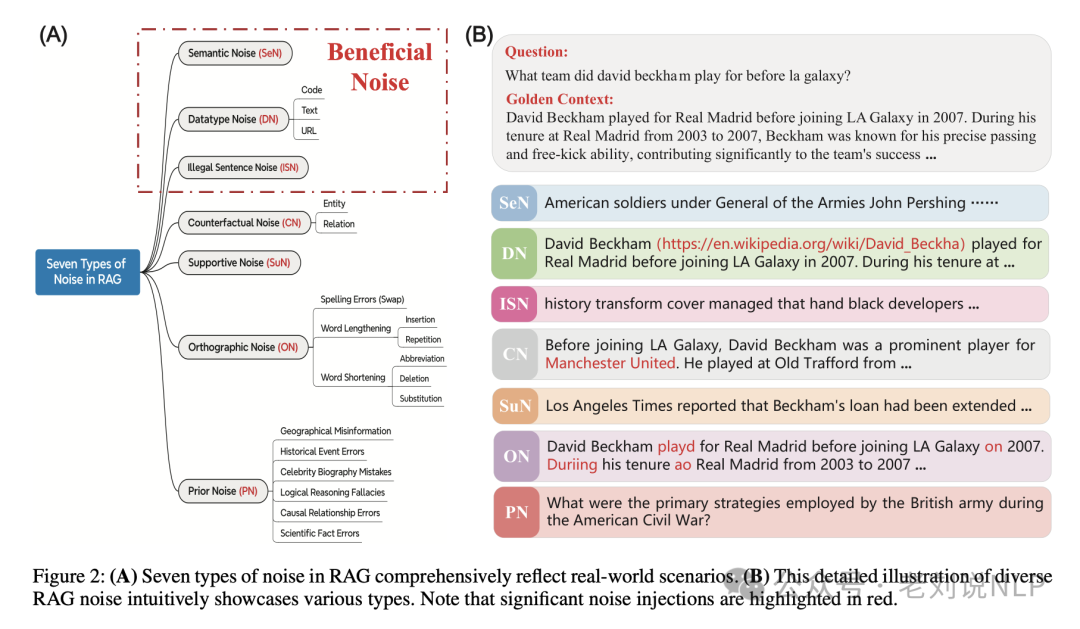
Figure 2 在论文中提供了对 RAG 噪声类型的详细分类和直观展示:
(A) 七种 RAG 噪声类型全面反映现实世界场景:
-
这部分说明作者定义的七种噪声类型能够广泛覆盖现实世界中可能遇到的各种情况。这些噪声类型包括:
-
- 语义噪声(Semantic Noise, SeN):检索文档可能包含与查询语义相关度低的内容,通常是离题或偏离预期意义的。
- 数据类型噪声(Datatype Noise, DN):网页上不同类型的数据混合,如文本、链接和代码的混合。
- 非法句子噪声(Illegal Sentence Noise, ISN):网页内容可能包括不构成语法正确句子的片段。
- 反事实噪声(Counterfactual Noise, CN):互联网上包含大量虚假信息,如假新闻和过时知识,这对 RAG 系统构成挑战。
- 支持性噪声(Supportive Noise, SuN):虽然与假设高度语义相关,但缺乏相应答案信息的文档。
- 正字法噪声(Orthographic Noise, ON):可能包括拼写错误和单词拉长等写作错误。
- 先前知识噪声(Prior Noise, PN):基于错误假设或前提的问题。
(B) 多种 RAG 噪声的详细插图直观展示各种类型:
- 这部分提供了一个直观的插图,展示不同类型的 RAG 噪声。插图可能通过不同的视觉元素或图表来表示每种噪声的特征和它们如何影响 RAG 系统。
- 插图中特别强调了显著的噪声注入,用红色突出显示。这有助于读者快速识别和理解在实际应用中可能对模型性能产生重大影响的噪声类型。
2、噪声影响的评估
在评估数据集上,建立了一个NoiseRAG Benchmark(NoiserBench),这是一个综合评估框架,包含多个数据集和推理任务,用于测试不同噪声类型对LLM性能的影响。
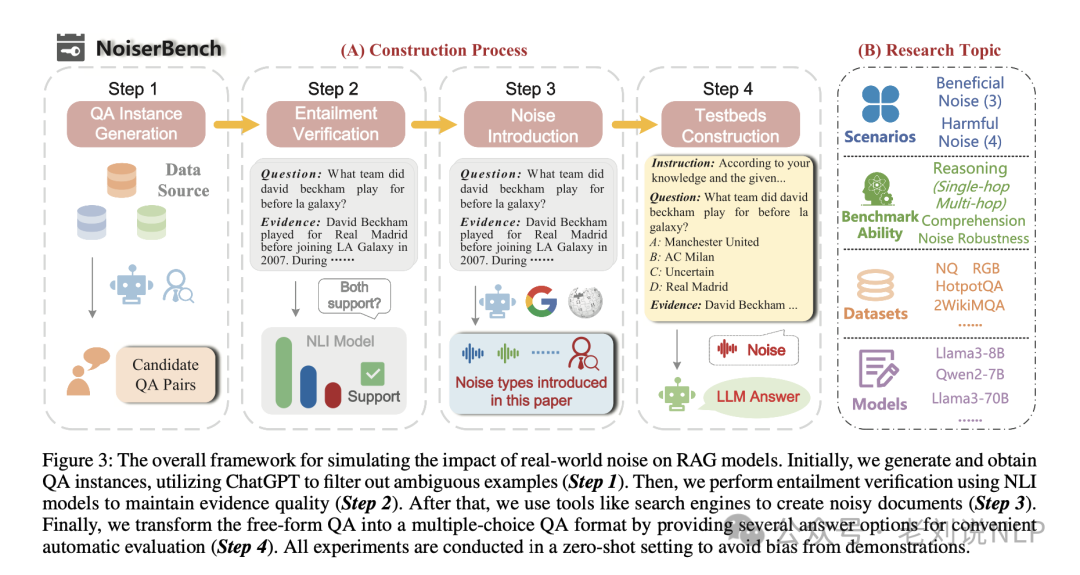
Figure 3 描述了用于模拟现实世界噪声对 RAG 模型影响的整体框架:
-
生成和获取 QA 实例(步骤 1):
-
- 首先,研究者生成或获取问答(QA)实例,即问题和答案对。
- 使用 ChatGPT 来筛选出那些模棱两可或难以评估的实例,确保 QA 实例的质量。
-
进行蕴含性验证(步骤 2):
-
- 接着,使用自然语言推理(NLI)模型来验证证据和答案之间的蕴含关系,确保证据能够有效地支持答案。
- 只保留那些蕴含概率大于或等于 0.8 的例子,以此来维持证据的质量。
-
使用搜索引擎等工具创建噪声文档(步骤 3):
-
- 利用搜索引擎和其他工具从互联网上检索信息,构建包含不同噪声类型的文档。
- 这些噪声文档模拟了现实世界中存在的各种非标准噪声,如假新闻、过时内容、拼写错误和数据污染。
-
转换为多项选择 QA 格式(步骤 4):
-
- 将自由形式的 QA 对转换成多项选择格式,为每个问题提供几个答案选项。
- 这样做可以限制回答空间,便于进行更准确的自动评估。
- 正确答案、两个反事实的选项和“不确定”作为选项,且正确答案的顺序完全随机,以避免模型对选项顺序的敏感性。
-
零样本设置(Zero-shot setting):
-
- 所有实验都在零样本设置下进行,即模型在没有接受过针对特定任务的训练或演示的情况下进行评估。
- 这种设置避免了由于演示偏差而带来的影响,确保了实验结果的公正性和模型泛化能力的评估。
3、评估的结论
在性能发现上,可以看看:
- 有益噪声(如语义噪声、数据类型噪声、非法句子噪声)可以促进更标准化的答案格式、更清晰的推理路径。
- 有害噪声(如反事实噪声、支持性噪声、拼写噪声、先前知识噪声)通常损害性能。
总结
本文主要介绍了大模型中RAG噪声的作用分析,其中对于噪声的定义以及一些作用影响,大家可以多关注。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}