






本文概要
目录
1.PS部分架构及资源分析
所有的 Zynq 芯片都有相同的基本架构。作为处理器系统(PS)的基础,所有的芯片都 包含了一颗双核 ARM Cortex-A9 处理器。
重要的是,Zynq 的处理器系统里并非只有 ARM 处理器,还有一组相关的处理资 源,形成了一个应用处理器单元 (Application Processing Unit,APU),另外还 有扩展外设接口、cache 存储器、存储器接口、互联接口和时钟发生电路。下图所示就是 PS 部分架构框图,其中高亮的部分就是 APU。
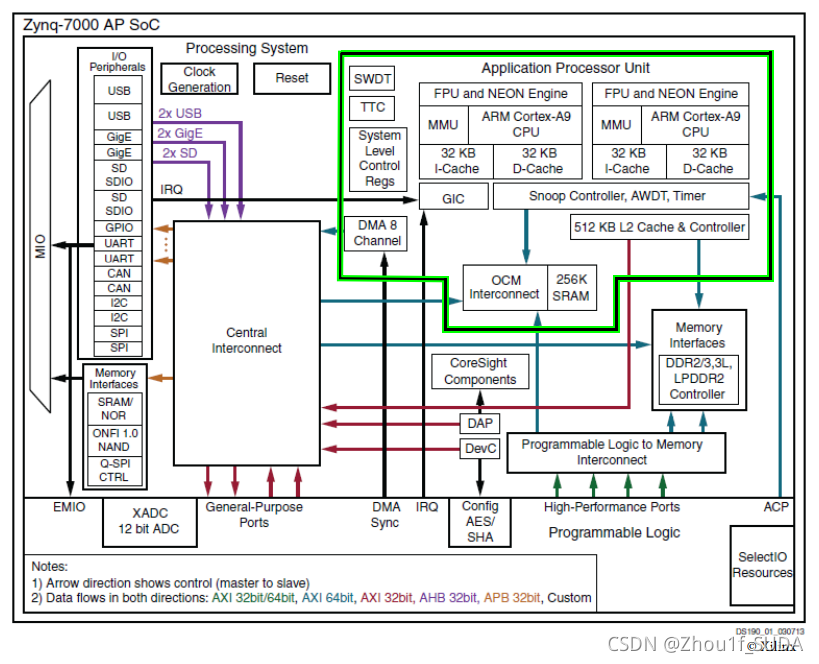 图 1.1
图 1.1
接下来我们对APU进行一些简单的介绍。
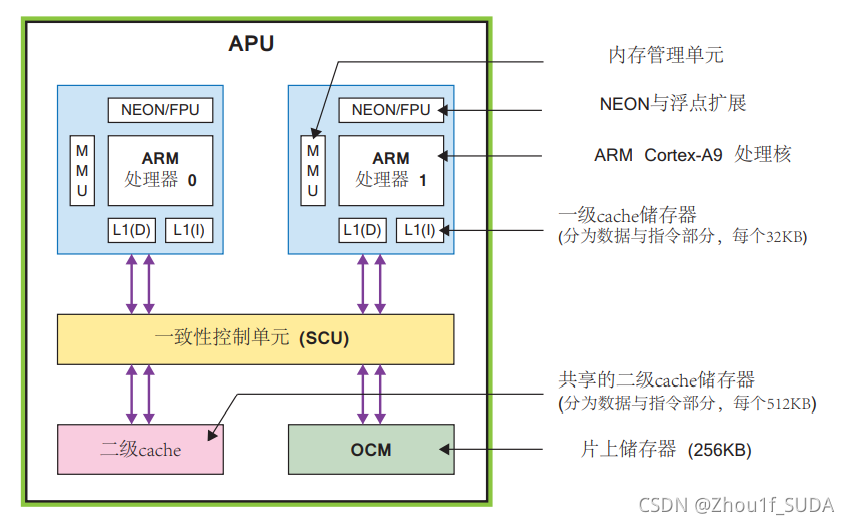
图 1.2
APU 主要是由两个 ARM 处理核组成的,每个都 关联了一些可计算的单元:一个 NEONTM 媒体处理引擎(Media Processing Engine, MPE)和浮点单元 (Floating Point Unit,FPU);一个内存管理单元 (Memory Management Unit,MMU);和一个一级 cache 存储器(分为指令L1(I)和数据L1(D)两个部分)。 APU 里还有一个二级 cache 存储器,再往下还有片上存储器 (On Chip Memory,OCM)。最后,由一个一致性控制单元 (Snoop Control Unit,SCU)在 ARM 核和二 级 cache 及 OCM 存储器之间形成了桥连接,这个单元还部分负责与 PL 对接,图中没有标出这个接口。
接下来我简要介绍一下APU中一些功能单元的作用。
- MMU:MMU 的主要责任是在虚拟地址和物理地址之间做翻译;
- cache:一级cache和二级cache都是用来存放指令和数据;
- SCU:一致性 (窥视)控制单元 (SCU)从事的是一些和两个处理器与一二级 cache 存储器之间的接口相关的任务;
- NEON:作为主 ARM 处理器的附加功能,NEON 引擎实现了单指令多数据 (Single Instruction Multiple Data,SIMD)功能来实现媒体和 DSP类算法的战略加速。NEON可以对 输入向量中的多组数据,同时执行相同的运算来得到对应的输出向量。这种计算范 式很好地迎合了像图像和视频处理这样的应用,可以同时对大量的数据样本(像素 点)做运算,也适合天生具有并行性的常用的信号处理函数,比如有限脉冲响应 (Finite Impulse Response,FIR)滤波和快速傅立叶变换 (Fast Fourier Transforms,FFT)。需要指出的是,NEON 支持多种数据类型,包括有符号和无符号的整数、单精度浮点书和半精度 浮点数,但是不支持双精度的。
- FPU:这个单元实现了与 IEEE 754标准兼容的浮点运算的硬件加速,支持单精度和 双精度格式,另外还部分支持半精度和整数转换。
另外,PS 和外部接口之间的通信主要是通过复用的输入 / 输出(Multiplexed Input/ Output,MIO)实现的,也可以这采用EMIO来实现,这边暂且不做过多介绍。
从编程的角度看,对 ARM 指令的支持是由 Xilinx 软件开发包 (Software Development Kit,SDK)来实现的,它包含了开发部署在 ARM 处理器上的软件所需 的全部内容
2.PL部分架构及资源分析

图 2.1
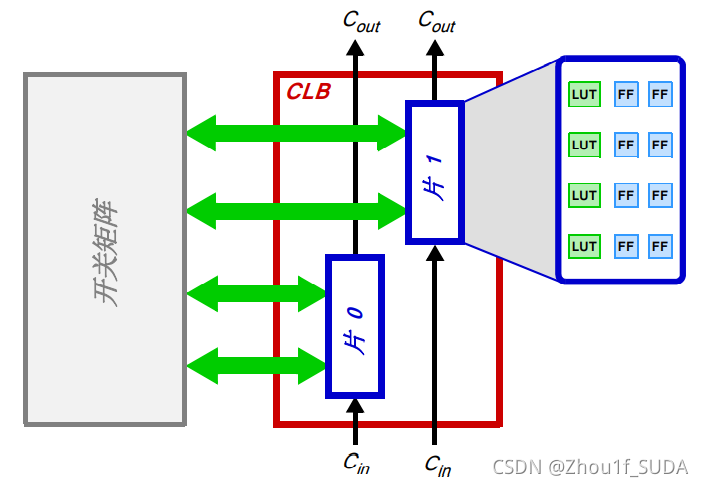
图 2.2
图2.1描绘了 Zynq 芯片的 PL 部分,其中几个功能被高亮了出来。PL 主要是由 通用 FPGA 逻辑部分组成的,这个 FPGA 是由逻辑片和可配置逻辑块(Configurable Logic Block,CLB)组成的,另外还有用于接口的输入 / 输出块 (Input/ Output Block,IOB)(注意这些都是 Xilinx 专有的术语)。
现在我们来简单介绍一下这些模块:
- 可配置逻辑块CLB——CLB 是逻辑单元的小规模、普通编组,在 PL 中排列为 一个二维阵列,通过可编程互联连接到其他类似的资源。每个 CLB 里包含两个逻辑片,并且紧邻一个开关矩阵,如图 2.2所示。
- 片 (Slice)——CLB 里的一个子单元,图2.2中蓝色线条方框,里面有实现组合和时序逻辑电路的资 源。如图 2.6 所示,Zynq 的片是由 4 个查找表、8 个触发器和其他一些逻辑所组成的。
- 查找表 (Lookup Table,LUT) ——一个灵活的资源,可以实现(1)至多 6 个输入的逻辑函数; (2)一小片只读存储器 (ROM);(3)一小片随机 访问存储器 (RAM);或(4)一个移位寄存器。LUT 可以按需组合起来形成 更大的逻辑函数、存储器或移位寄存器。
- 触发器(Flip-flop,FF) —— 一个实现 1 位寄存的时序电路,带有复位功能。 FF 的一种用处是实现锁存。
- 开关矩阵 (Switch Matrix) —— 每个CLB 旁都有一个开关矩阵,实现灵活的布线功能来(一)连接 CLB 内的单元;或(二)把一个 CLB 与 PL 内的其他资 源连接起来。
- 进位逻辑 (Carry Logic) —— 算术电路需要在相邻的片之间传递信号,这就 是通过进位逻辑来实现的。进位逻辑把布线和复用器组成链条来连接一个垂直列上的片。
- 输入 / 输出块 (Input/Output Blocks,IOB) —— IOB 实现了 PL 逻辑资源之间的对接,Zynq 上的通用输入 / 输出功能(IOB)合起来被称作 SelectIO 资源,它们被组织成50个IOB 一组。每个 IOB 有一个焊盘,是与外部世界连接来做单个信号的输入或输出的。并且提供物理设备 “ 焊盘 ” 来连接外部电路。每个 IOB 可以处理一位的输入或输出信号。每个 IOB 还包含一个 IOSERDES 资源,可以做并行和串行数据的可编程转换(串行化和反串行化),数据可以是 2 位到 8 位的。IOB 通常位于芯片的周边。
- 通信接口——Zynq 芯片里含有嵌入在逻辑部分里的 GTX 收发器和高速通信接口块,包括 PCI Express、串行 RapidIO、SCSI 和 SATA。要实现 PCI Express,除了 GTX 收发器本身 之外,还需要另一个硬 IP 包(一个 PCI Express 块,也存在于相应的 Zynq 芯 片)和块 RAM。笔者目前使用的Z-7010版本是没有这个PCI Express块的。
补充:GTX 收发器一组有四个独立的通道,每个通道包括一个那个通道专用的锁相环 (Phase Locked Loop,PLL)、一个发送 器和一个接收器。要使用这些 GTX 块,需要通过一个 Wizard 工具的支持,它能自动创建所需的接口的核。
两种特殊资源:
满足密集存储需要的块 RAM 和用 于高速算术的 DSP48E1 片。这两个资源都按列排列集成在逻辑阵列中,嵌入在逻辑部分中,而且往往彼此靠近,图2.1中蓝色方块为DSP48E1,绿色方块为块RAM。
- 块RAM——可以实现 RAM、ROM 和先入先出 (First In First Out,FIFO)缓冲器,同时还支 持纠错编码 (Error Correction Coding,ECC);
- DSP48E1——逻辑部分里的 LUT 可以用来实现任意长度的算术运算,但是最合适的是做短字 长的算术运算(长字长的算术电路会在逻辑片中占据较大的空间,这样的布局和布线因素会使得时钟频率是次优的)。DSP48E1是专门用于实现对长字长信号的高速算术运算的逻辑片。值得一提的是,多个DSP48E1组合在一起可以实现复数运算。DSP48E1 适合信号处理及其他各种应用。其中最有影响力的 一种用法是用来实现对称形式的有限脉冲响应滤波器,这是在 DSP 和数字通信中常用的部件。(具体关于DSP48E1的知识可以参考《The Zynq Book》。)
其他资源:
- 模拟 - 数字转换 — PL 还具有其他的硬 IP 部件:XADC块。这是一个专用的模拟 - 数字转换器 (Analogue to Digital Converter,ADC)混合信号硬件,具有两个独立的12 位 ADC,每个可以以 1Msps 对外部模拟输入信号采样。对 XADC 的控制是用位于 PS 内的 PS-XADC 接口控制块实现的,而且 PS-XADC 控制块本身可以由 APU 上所执行的软件来编程。
- 时钟 — PL 接收来自 PS 的四个独立的时钟输入,另外还能产生和分发它自己的与 PS无关的时钟信号 。
- 编程与调试 — 在 PL 部分实现了一组 JTAG 端口来实现对 PL 的配置和调试。尽管在部署的时候通常倾向于更安全的方法,在开发阶段还是常用 JTAG 来做配置。ARM 和 Xlinx 工具都支持通过 JTAG 来做调试。
3.PS和PL部分之间的连接
Zynq 的表现不仅仅依赖于它的两个组成部分 PS 和 PL 的特性,还在 于能把两者协同起来形成完整、集成的系统的能力。这其中起关键作用的,是一组 高度定制的 AXI 互联和接口用来在两个部分之间形成桥梁。另外,在 PS 和 PL 之间 还有一些其他类型的连接,特别是 EMIO,这里暂不讨论EMIO。
3.1 AXI标准
AXI 表示的是高级可扩展接口(Advanced eXtensible Interface),当前的版本是 AXI4。
AXI 总线可以灵活使用,而且一般情况下是用来在一个嵌入式系统中连接处理器和其他 IP 包的。实际上有三类 AXI4,每一类代表了一种不同的总线协议,下面会有总结。对于一个特定的连接选择哪个 AXI 总线协议是基于那个连接所需的特性的。
- AXI4 —— 用于存储映射链接,它支持最高的性能:通过一簇高达 256 个数 据字 (或 “ 数据拍 (data beats)”)的数据传输来给定一个地址。
- AXI4-Lite —— 一种简化了的链接,只支持每次连接传输一个数据(非批 量)。AXI4-Lite也是存储映射的:这种协议下每次传输一个地址和单个数据。
- AXI4-Stream —— 用于高速流数据,支持批量传输无限大小的数据。没有 地址机制,这种总线类型最适合源和目的地之间的直接数据流(非存储器映射)。
“ 存储映射 ” 的概念:如果一个协议是存储映射的,那么在主机所发出的会话(无论读或写)中就 会标明一个地址,这个地址是对应于系统存储空间中的一个地址的。对于仅支持每 次会话单个数据传输的 AXI4-Lite 而言,数据就是写入那个指定的地址,或从那个 地址读出;而在 AXI4 批量的情况下,地址表明的是要传输的第一个数据字的地址, 而从机端必须计算随后的数据字的地址。
3.2 AXI互联和接口
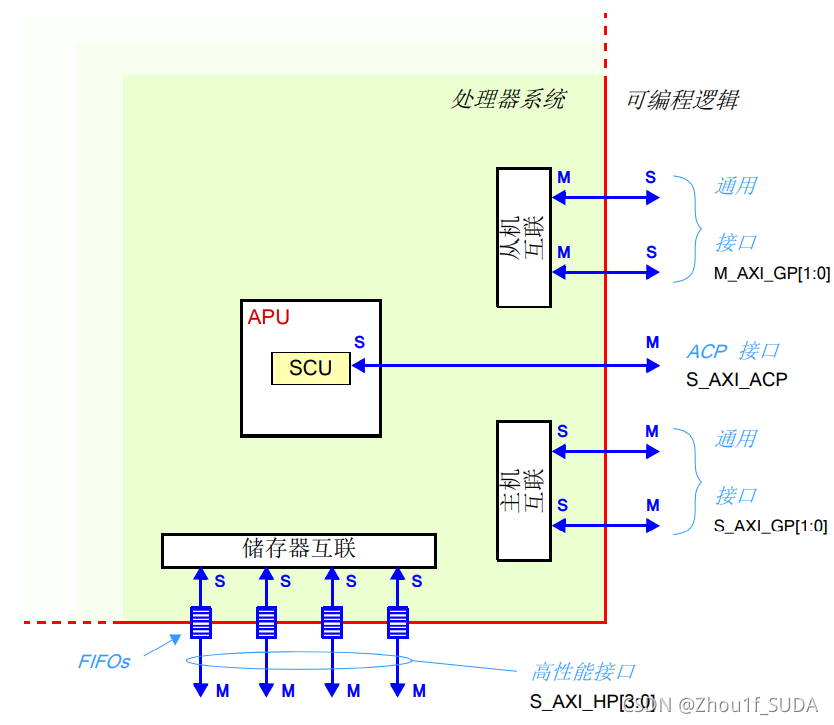
图 3.1
在 PS 和 PL 之间的主要连接是通过一组 9 个AXI接口,每个接口有多个通道组成。这些形成了 PS 内部的互联以及与 PL 的连接,如图 3.1所示。这里,有必要定义两个重要的术语:
互联(Interconnect)——互联实际上是一个开关,管理并直接传递所连接的 AXI 接口之间的通信。在 PS 内有几个互联,其中有些还直接连接到 PL(如图 3.1),而另一些是只用于内部连接的。这些互联之间的连接也是用 AXI 接口 所构成的。
接口 (Interface) — 用于在系统内的主机和从机之间传递数据、地址和握 手信号的点对点连接。
从图上可以注意到所有的接口都明确地连接到 PS 内的 AXI 互联,唯一例外的是 ACP 接口,它直接连到 APU 里面的一致性控制单元 (SCU)。关于PS内部的一些互联和接口可以结合图1.1。
表3给出了图 3.1中的箭头所表示的接口的总结。它给出了每个接口的简 述,标出了主机和从机 (按照惯例,主机是控制总线并发起会话的,而从机是做响 应的)。注意接口命名的规范(在表 3的第一列)是表示了 PS 的角色的,也就是 说,第一个字母 “M” 表示 PS 是主机,而第一个字母 “S” 表示 PS 是从机。
表3
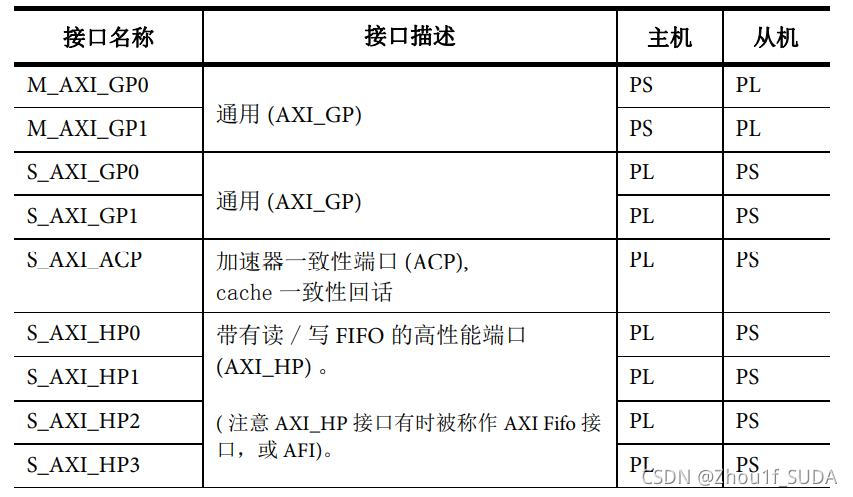
下面总结一下这些接口的作用(读者可以结合图3.1一起来看):
- 通用 AXI(General Purpose AXI)——一条 32 位数据总线,适合 PL 和 PS 之 间的中低速通信。接口是透传的不带缓冲。总共有四个通用接口:两个 PS 做 主机,另两个 PL 做主机。
- 加速器一致性端口(Accelerator Coherency Port) —— 在 PL 和 APU 内的 SCU 之间的单个异步连接,总线宽度为 64 位。这个端口用来实现 APU cache 和 PL 的单元之间的一致性。PL 是做主机的。
- 高性能端口(High Performance Ports) ——四个高性能 AXI 接口,带有 FIFO 缓冲来提供 “ 批量 ” 读写操作,并支持 PL 和 PS 中的存储器单元的高速率通 信。数据宽度是 32 或 64 位,在所有四个接口中 PL 都是做主机的。
注:每条总线都是由一组信号组成的,这些总线上的会话是根据所定义的总线标准,也就是 AXI4来发生的。
今天的内容就是这些,欢迎大家指正讨论呀!

















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









